Los modelos de lenguaje grande (LLM) se utilizan cada vez más, pero su gran número de parámetros conlleva enormes necesidades de recursos informáticos. Para resolver este problema y mejorar la eficiencia y precisión del modelo en diferentes entornos de recursos, los investigadores continúan explorando nuevos métodos. Este artículo presentará el marco Flextron desarrollado conjuntamente por investigadores de NVIDIA y la Universidad de Texas en Austin. Este marco está diseñado para lograr una implementación flexible de modelos de IA sin ajustes adicionales y resolver eficazmente los problemas de ineficiencia de los métodos tradicionales. El editor de Downcodes explicará en detalle las innovaciones del marco Flextron y sus ventajas en entornos con recursos limitados.
En el campo de la inteligencia artificial, los grandes modelos de lenguaje (LLM), como GPT-3 y Llama-2, han logrado avances significativos y pueden comprender y generar con precisión el lenguaje humano. Sin embargo, la gran cantidad de parámetros de estos modelos hace que requieran una gran cantidad de recursos informáticos durante el entrenamiento y la implementación, lo que plantea un desafío en entornos con recursos limitados.
Entrada en papel: https://arxiv.org/html/2406.10260v1
Tradicionalmente, para lograr un equilibrio entre eficiencia y precisión bajo diferentes limitaciones de recursos informáticos, los investigadores necesitan entrenar múltiples versiones diferentes del modelo. Por ejemplo, la familia de modelos Llama-2 incluye diferentes variantes con 7 mil millones, 1,3 mil millones y 700 millones de parámetros. Sin embargo, este método requiere una gran cantidad de datos y recursos informáticos y no es muy eficiente.
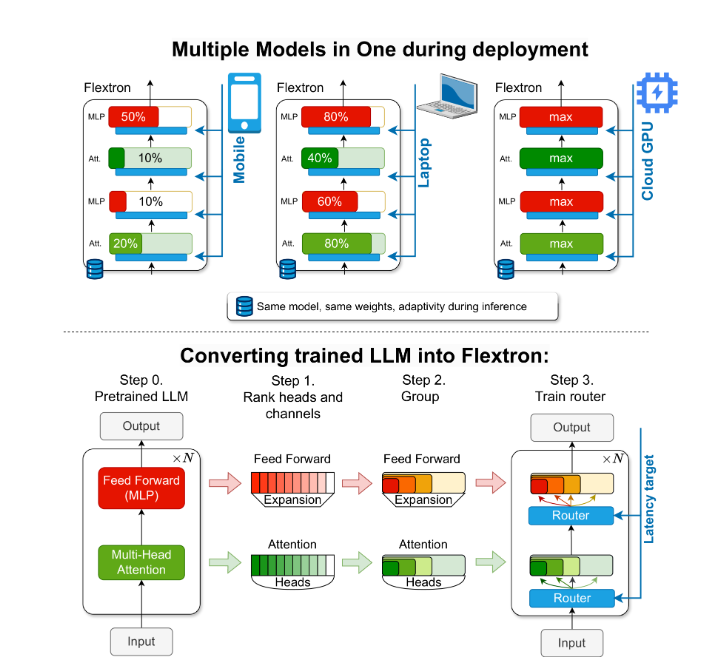
Para resolver este problema, investigadores de NVIDIA y la Universidad de Texas en Austin introdujeron el marco Flextron. Flextron es una novedosa arquitectura de modelo flexible y un marco de optimización posterior al entrenamiento que admite la implementación adaptativa de modelos sin la necesidad de ajustes adicionales, resolviendo así los problemas de ineficiencia de los métodos tradicionales.
Flextron transforma LLM previamente entrenado en modelos elásticos mediante métodos de entrenamiento eficientes en muestras y algoritmos de enrutamiento avanzados. Esta estructura presenta un diseño elástico anidado que permite ajustes dinámicos durante la inferencia para cumplir objetivos específicos de latencia y precisión. Esta adaptabilidad hace posible utilizar un único modelo previamente entrenado en una variedad de escenarios de implementación, lo que reduce significativamente la necesidad de múltiples variantes de modelo.
La evaluación del rendimiento de Flextron muestra que supera en eficiencia y precisión en comparación con múltiples modelos entrenados de un extremo a otro y otras redes elásticas de última generación. Por ejemplo, Flextron funciona bien en múltiples puntos de referencia como ARC-easy, LAMBADA, PIQA, WinoGrande, MMLU y HellaSwag, utilizando solo el 7,63% de los marcadores de entrenamiento en el entrenamiento previo original, ahorrando así una gran cantidad de recursos informáticos y tiempo. .
El marco Flextron también incluye capas elásticas de perceptrón multicapa (MLP) y atención elástica de múltiples cabezas (MHA), lo que mejora aún más su adaptabilidad. La capa elástica MHA utiliza eficazmente la memoria disponible y la potencia de procesamiento seleccionando un subconjunto de cabezas de atención en función de los datos de entrada, y es particularmente adecuada para escenarios con recursos informáticos limitados.
Destacar:
? El marco Flextron admite la implementación flexible del modelo de IA sin ajustes adicionales.
Mediante un entrenamiento de muestras eficiente y algoritmos de enrutamiento avanzados, se mejoran la eficiencia y precisión del modelo.
La capa de atención elástica de múltiples cabezales optimiza la utilización de recursos y es particularmente adecuada para entornos con recursos informáticos limitados.
Este informe espera presentar la importancia y la innovación del marco Flextron a los estudiantes de secundaria de una manera fácil de entender.
En definitiva, el marco Flextron proporciona una solución eficiente e innovadora al problema de implementar grandes modelos de lenguaje en entornos con recursos limitados. Su arquitectura flexible y su método de entrenamiento eficiente en muestras le brindan ventajas significativas en aplicaciones prácticas y brindan una nueva dirección para el desarrollo futuro de la tecnología de inteligencia artificial. El editor de Downcodes espera que este artículo pueda ayudar a todos a comprender mejor las ideas centrales y las contribuciones técnicas del marco Flextron.