El editor de Downcodes lo llevará a conocer una tecnología innovadora que mejora la eficiencia de los modelos de lenguaje grandes (LLM): Q-Sparse. Las poderosas capacidades de procesamiento del lenguaje natural de los LLM han atraído mucha atención, pero su alto costo computacional y su uso de memoria siempre han sido cuellos de botella en las aplicaciones prácticas. Q-Sparse utiliza un método de dispersión inteligente para mejorar significativamente la eficiencia de la inferencia y al mismo tiempo garantizar el rendimiento del modelo, allanando el camino para la aplicación generalizada de LLM. Este artículo explorará en profundidad la tecnología central, las ventajas y los resultados de verificación experimental de Q-Sparse, mostrando su enorme potencial para mejorar la eficiencia de los LLM.
En el mundo de la inteligencia artificial, los grandes modelos de lenguaje (LLM) son conocidos por sus capacidades superiores de procesamiento del lenguaje natural. Sin embargo, el despliegue de estos modelos en aplicaciones prácticas enfrenta enormes desafíos, principalmente debido a su alto costo computacional y uso de memoria durante la etapa de inferencia. Para resolver este problema, los investigadores han estado explorando cómo mejorar la eficiencia de los LLM. Recientemente, un método llamado Q-Sparse ha atraído una gran atención.
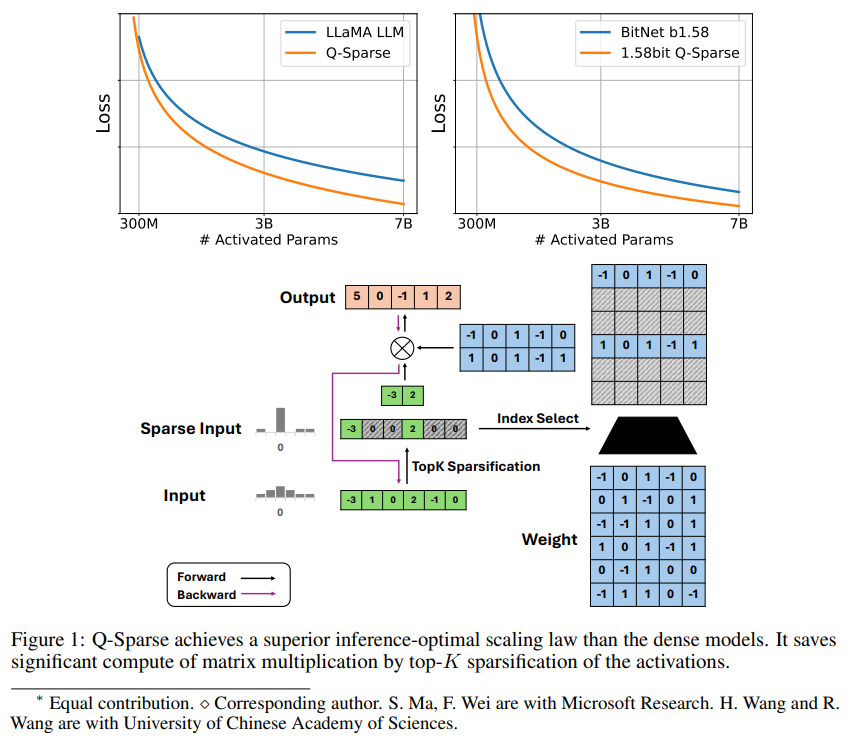
Q-Sparse es un método simple pero efectivo que logra una activación completamente dispersa de LLM mediante la aplicación de una dispersión top-K en las activaciones y un estimador de transferencia en el entrenamiento. Esto significa mejoras significativas en la eficiencia a la hora de inferir. Los resultados clave de la investigación incluyen:
Q-Sparse logra una mayor eficiencia de inferencia al tiempo que mantiene resultados comparables a los de los LLM de referencia.
Se propone una regla de expansión óptima inferencial adecuada para LLM de activación escasa.
Q-Sparse funciona en diferentes entornos, incluida la capacitación desde cero, la capacitación continua de LLM disponibles en el mercado y el ajuste.
Q-Sparse funciona con total precisión y LLM de 1 bit (por ejemplo, BitNet b1.58).
Ventajas de la activación escasa
La escasez mejora la eficiencia de los LLM de dos maneras: en primer lugar, la escasez puede reducir la cantidad de cálculo de la multiplicación de matrices, porque los elementos cero no se calcularán; en segundo lugar, la escasez puede reducir la cantidad de transmisión de entrada/salida (E/S), lo que Es el principal cuello de botella en la fase de inferencia de los LLM.
Q-Sparse logra una dispersión total de activaciones aplicando una función de dispersión top-K en cada proyección lineal. Para la retropropagación, el gradiente de activación se calcula utilizando un estimador de paso. Además, se introduce la función ReLU al cuadrado para mejorar aún más la escasez de activación.
Verificación experimental
Los investigadores estudiaron la ley de expansión de los LLM escasamente activados mediante una serie de experimentos de expansión y llegaron a algunos hallazgos interesantes:
El rendimiento de los modelos de activación dispersa mejora al aumentar el tamaño del modelo y la proporción de escasez.
Dada una relación de escasez fija S, el rendimiento de un modelo de activación dispersa escala con el tamaño del modelo N en forma de ley de potencia.
Dado un parámetro fijo N, el rendimiento del modelo de activación dispersa aumenta exponencialmente con la relación de escasez S.
Q-Sparse se puede utilizar no solo para capacitación desde cero, sino también para capacitación continua y ajuste de LLM disponibles en el mercado. En las configuraciones de entrenamiento continuo y ajuste, los investigadores utilizaron la misma arquitectura y proceso de entrenamiento que el entrenamiento desde cero, la única diferencia fue inicializar el modelo con pesos previamente entrenados y habilitar funciones dispersas para continuar el entrenamiento.
Los investigadores están explorando el uso de Q-Sparse con LLM de 1 bit (como BitNet b1.58) y expertos mixtos (MoE) para mejorar aún más la eficiencia de los LLM. Además, están trabajando para hacer que Q-Sparse sea compatible con el modo por lotes, lo que proporcionará más flexibilidad para la capacitación y la inferencia de LLM.
La aparición de la tecnología Q-Sparse proporciona nuevas ideas para resolver el problema de eficiencia de los LLM. Tiene un gran potencial para reducir los costos informáticos y el uso de memoria, y se espera que promueva la aplicación de los LLM en más campos. Se cree que en el futuro surgirán más resultados de investigación basados en Q-Sparse para mejorar aún más el rendimiento y la eficiencia de los LLM.