En los últimos años, los grandes modelos multimodales se han desarrollado rápidamente y han surgido muchos modelos excelentes. Sin embargo, la mayoría de los modelos existentes se basan en codificadores visuales, que sufren problemas de sesgo de inducción visual causados por la separación del entrenamiento, lo que limita la eficiencia y el rendimiento. El editor de Downcodes le ofrece un nuevo modelo de lenguaje visual EVE lanzado por el Instituto de Investigación Zhiyuan junto con universidades. Adopta una arquitectura sin codificador y ha logrado excelentes resultados en múltiples pruebas comparativas, lo que brinda nuevas oportunidades para el desarrollo de modelos multimodales. .
Recientemente, se han logrado avances significativos en la investigación y aplicación de grandes modelos multimodales. Empresas extranjeras como OpenAI, Google, Microsoft, etc. han lanzado una serie de modelos avanzados, e instituciones nacionales como Zhipu AI y Step Star han logrado avances en este campo. Estos modelos generalmente se basan en codificadores visuales para extraer características visuales y combinarlas con modelos de lenguaje grandes, pero existe un problema de sesgo de inducción visual causado por la separación del entrenamiento, que limita la eficiencia de implementación y el rendimiento de los modelos grandes multimodales.
Para resolver estos problemas, el Instituto de Investigación Zhiyuan, junto con la Universidad Tecnológica de Dalian, la Universidad de Pekín y otras universidades, lanzaron una nueva generación de modelo de lenguaje visual sin codificador EVE. EVE integra representación, alineación e inferencia visual-lingüística en una arquitectura de decodificador puro unificada a través de estrategias de capacitación refinadas y supervisión visual adicional. Utilizando datos públicos, EVE funciona bien en múltiples puntos de referencia visual-lingüísticos, acercándose o incluso superando los métodos multimodales basados en codificadores convencionales.
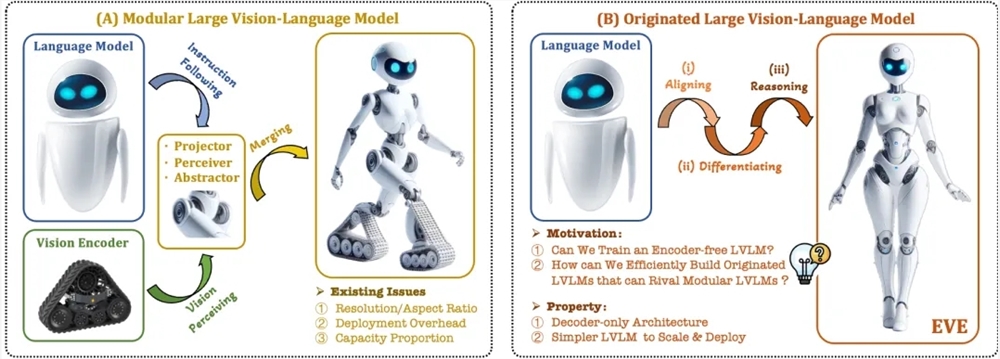
Las características clave de EVE incluyen:
Modelo de lenguaje visual nativo: elimina el codificador visual y maneja cualquier relación de aspecto de la imagen, lo cual es significativamente mejor que el mismo tipo de modelo Fuyu-8B.
Bajos costos de datos y capacitación: la capacitación previa utiliza datos públicos como OpenImages, SAM y LAION, y el tiempo de capacitación es corto.
Exploración transparente y eficiente: proporciona una ruta de desarrollo eficiente y transparente para arquitecturas multimodales nativas de decodificadores puros.
Estructura del modelo:
Capa de incrustación de parches: obtenga el mapa de características 2D de la imagen a través de una única capa convolucional y una capa de agrupación promedio para mejorar las características locales y la información global.
Capa de alineación de parches: integre funciones visuales de red multicapa para lograr una alineación detallada con la salida del codificador visual.
Estrategia de formación:
Etapa de preformación guiada por grandes modelos de lenguaje: estableciendo la conexión inicial entre visión y lenguaje.
Etapa de preentrenamiento generativo: mejorar la capacidad del modelo para comprender el contenido visual-lingüístico.
Fase de ajuste supervisada: regula la capacidad del modelo para seguir instrucciones del lenguaje y aprender patrones de conversación.
Análisis cuantitativo: EVE funciona bien en múltiples puntos de referencia del lenguaje visual y es comparable a una variedad de modelos de lenguaje visual basados en codificadores convencionales. A pesar de los desafíos para responder con precisión a instrucciones específicas, a través de una estrategia de entrenamiento eficiente, EVE logra un rendimiento comparable a los modelos de lenguaje visual con bases de codificador.
EVE ha demostrado el potencial de los modelos de lenguaje visual nativo sin codificador. En el futuro, puede continuar promoviendo el desarrollo de modelos multimodales mediante nuevas mejoras de rendimiento, optimización de arquitecturas sin codificador y la construcción de multimodales nativos. modelos.
Dirección del artículo: https://arxiv.org/abs/2406.11832
Código del proyecto: https://github.com/baaivision/EVE
Dirección del modelo: https://huggingface.co/BAAI/EVE-7B-HD-v1.0
Con todo, la aparición del modelo EVE proporciona nuevas direcciones y posibilidades para el desarrollo de grandes modelos multimodales. Su estrategia de entrenamiento eficiente y su excelente rendimiento merecen atención. Esperamos que el futuro modelo EVE pueda demostrar sus poderosas capacidades en más campos.