En la comunicación de voz en tiempo real, cambiar el timbre del hablante sin afectar la semántica y la prosodia siempre ha sido un problema técnico. El editor de Downcodes presentará hoy una tecnología innovadora: StreamVC, que puede cambiar el timbre de voz del hablante en tiempo real manteniendo el contenido y el ritmo de la voz. Es adecuado para plataformas móviles y proporciona comunicación en tiempo real y anonimización de voz. La baja latencia, la síntesis de voz de alta calidad y la estabilidad del tono de StreamVC le otorgan ventajas significativas en el campo de las comunicaciones en tiempo real.
En un mundo de comunicación en tiempo real, ya sea una llamada telefónica o una videoconferencia, el sonido es una herramienta importante para expresarnos. Pero, ¿alguna vez has pensado en lo que pasaría si pudiéramos cambiar el timbre de la voz de un hablante en tiempo real sin afectar el contenido y el ritmo del idioma? La aparición de la tecnología StreamVC nos permite hacerlo.
StreamVC es una innovadora solución de conversión de voz que iguala el timbre de la voz de destino manteniendo el contenido y la prosodia de la voz de origen. A diferencia de los métodos tradicionales, StreamVC produce la forma de onda resultante con baja latencia en la señal de entrada, incluso en plataformas móviles, lo que lo hace adecuado para escenarios de comunicación en tiempo real, como llamadas telefónicas y videoconferencias, así como para la anonimización de voz en estos escenarios.
Aspectos destacados técnicos:
Tiempo real: StreamVC es capaz de realizar 70,8 milisegundos de inferencia de baja latencia en dispositivos móviles.
Síntesis de voz de alta calidad: utilice la arquitectura y la estrategia de entrenamiento del códec de audio neuronal SoundStream para lograr una síntesis de voz liviana y de alta calidad.
Estabilidad del tono: al introducir información de frecuencia fundamental blanqueada (f0), se mejora la consistencia del tono sin filtrar la información del timbre del altavoz fuente.
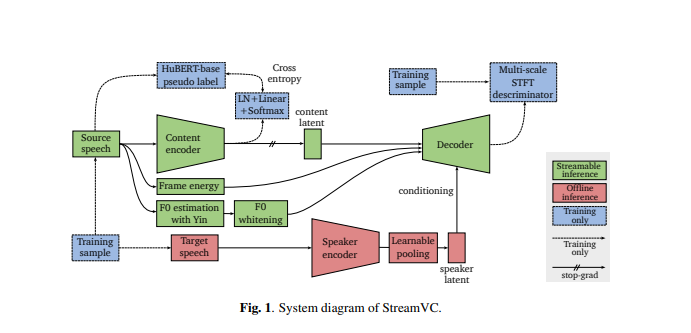
El diseño de StreamVC está inspirado en Soft-VC y SoundStream. Utiliza unidades de voz discretas extraídas por el modelo HuBERT como objetivos de predicción para la red codificadora de contenidos. La arquitectura del codificador y decodificador de contenido y la estrategia de capacitación están diseñadas a partir del códec de audio neuronal SoundStream para lograr una síntesis de audio causal de alta calidad.
StreamVC se comparó con tecnologías existentes en múltiples puntos de referencia, incluida la naturalidad, la comprensibilidad, la similitud de los hablantes y la coherencia del tono. Los resultados experimentales muestran que StreamVC funciona bien a la hora de preservar el tono del idioma de origen y es comparable al modelo ajustado en términos de similitud de hablantes.
StreamVC demuestra que la conversión de sonido eficiente con baja latencia en dispositivos móviles es totalmente factible. Las unidades de habla suave derivadas de HuBERT se pueden aprender a través de una arquitectura de red neuronal convolucional causal transmitible, y inyectar información f0 blanqueada en el decodificador es crucial para proporcionar resultados de alta calidad.
Dirección del artículo: https://arxiv.org/pdf/2401.03078
La aparición de la tecnología StreamVC ha brindado nuevas posibilidades para la comunicación de voz en tiempo real. Sus capacidades de conversión de voz de alta calidad y baja latencia promoverán la aplicación de la tecnología de voz en más campos. Creo que en el futuro StreamVC desempeñará un papel más importante en la anonimización de voz, efectos especiales de voz, etc. ¡Esperamos más aplicaciones innovadoras basadas en StreamVC!