Recientemente, el Laboratorio de Inteligencia Artificial de Tencent lanzó un nuevo modelo llamado VTA-LDM, que está diseñado para convertir de manera eficiente contenido de video en audio semántica y temporalmente consistente. La tecnología central de este modelo radica en la "alineación implícita", que combina perfectamente el contenido de audio y video generado, mejorando en gran medida la calidad y los escenarios de aplicación de la generación de audio. El editor de Downcodes lo llevará a comprender en profundidad las innovaciones y las perspectivas de aplicación del modelo VTA-LDM.
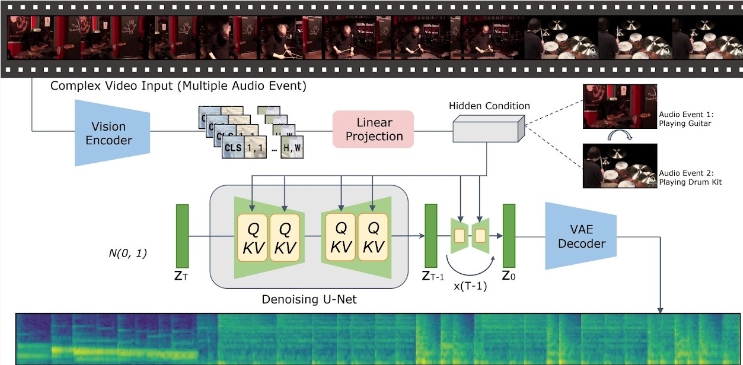
Con el importante progreso en la tecnología de generación de texto a video, cómo generar contenido de audio semántica y temporalmente consistente a partir de una entrada de video se ha convertido en un tema candente entre los investigadores. Recientemente, el equipo de investigación del Laboratorio de Inteligencia Artificial de Tencent lanzó un nuevo modelo llamado "Generación de video a audio implícitamente alineado" - VTA-LDM, cuyo objetivo es proporcionar soluciones eficientes de generación de audio.
Entrada del proyecto: https://top.aibase.com/tool/vta-ldm
La idea central del modelo VTA-LDM es hacer coincidir semántica y temporalmente el contenido de audio y video generado mediante tecnología de alineación implícita. Este método no solo mejora la calidad de la generación de audio, sino que también amplía los escenarios de aplicación de la tecnología de generación de video. El equipo de investigación realizó una exploración en profundidad del diseño del modelo y combinó una variedad de medios técnicos para garantizar la precisión y coherencia del audio generado.
La investigación se centra en tres aspectos clave: codificadores visuales, incrustaciones auxiliares y técnicas de aumento de datos. El equipo de investigación primero estableció un modelo básico y realizó una gran cantidad de experimentos de ablación sobre esta base para evaluar el impacto de diferentes codificadores visuales e incrustaciones auxiliares en el efecto de generación. Los resultados de estos experimentos muestran que el modelo funciona bien en términos de calidad de generación y alineación simultánea de vídeo y audio, situándose a la vanguardia de la tecnología actual.
En términos de inferencia, los usuarios solo necesitan colocar los videoclips en el directorio de datos especificado y ejecutar el script de inferencia proporcionado para generar el contenido de audio correspondiente. El equipo de investigación también proporciona un conjunto de herramientas para ayudar a los usuarios a fusionar el audio generado con el vídeo original, mejorando aún más la comodidad de la aplicación.
El modelo VTA-LDM actualmente ofrece múltiples versiones de modelos diferentes para satisfacer diferentes necesidades de investigación. Estos modelos cubren modelos básicos y una variedad de modelos mejorados, con el objetivo de brindar a los usuarios opciones flexibles para adaptarse a diversos experimentos y escenarios de aplicación.
El lanzamiento del modelo VTA-LDM marca un progreso importante en el campo de la generación de vídeo a audio. Los investigadores esperan utilizar este modelo para promover el desarrollo de tecnologías relacionadas y crear posibilidades de aplicación más ricas.
## Reflejos:
La aparición del modelo VTA-LDM ha traído nuevos avances al campo de la generación de video y audio. Sus métodos de operación eficientes y convenientes y sus potentes funciones presagian una perspectiva de aplicación más amplia en el futuro. Se cree que con el desarrollo continuo de la tecnología, el modelo VTA-LDM desempeñará un papel importante en más campos.