¡El editor de Downcodes trae grandes novedades! ¡Se lanza oficialmente la revolucionaria tecnología de aceleración de Transformer FlashAttention-3! Esta tecnología revolucionará la velocidad de inferencia y el coste de los modelos de lenguajes grandes (LLM), logrando mejoras de eficiencia sin precedentes. La velocidad aumenta de 1,5 a 2 veces, la operación de baja precisión (FP8) mantiene una alta precisión y las capacidades de procesamiento de textos largos se mejoran significativamente, lo que brindará nuevas posibilidades para las aplicaciones de IA. Echemos un vistazo más de cerca a esta tecnología innovadora.
¡Se ha lanzado la nueva tecnología de aceleración de Transformer, FlashAttention-3! ¡Esto no es solo una actualización, presagia un fuerte aumento en la velocidad de inferencia y una caída en picado del costo de nuestros grandes modelos de lenguaje (LLM)!
Hablemos primero de este FlashAttention-3. En comparación con la versión anterior, es simplemente un cambio de escopeta:
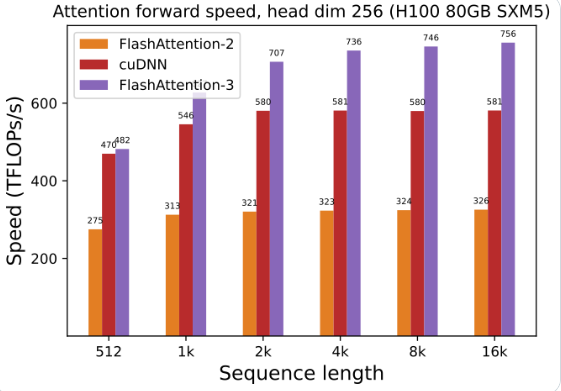
La utilización de la GPU se ha mejorado enormemente: al usar FlashAttention-3 para entrenar y ejecutar modelos de lenguaje grandes, la velocidad se duplica directamente, ¡de 1,5 a 2 veces más rápida!
Baja precisión, alto rendimiento: también puede funcionar con números de baja precisión (FP8) manteniendo la precisión. ¿Qué significa esto? Menor costo sin comprometer el rendimiento.
Procesar textos largos es pan comido: FlashAttention-3 mejora en gran medida la capacidad del modelo de IA para procesar textos largos, algo que antes era inimaginable.
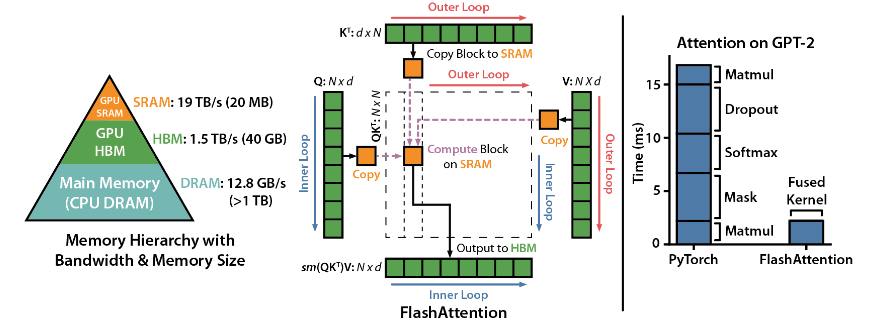
FlashAttention es una biblioteca de código abierto desarrollada por Dao-AILab. Se basa en dos artículos pesados y proporciona una implementación optimizada del mecanismo de atención en modelos de aprendizaje profundo. Esta biblioteca es particularmente adecuada para procesar conjuntos de datos a gran escala y secuencias largas. Existe una relación lineal entre el consumo de memoria y la longitud de la secuencia, que es mucho más eficiente que la relación cuadrática tradicional.
Aspectos destacados técnicos:
Soporte de tecnología avanzada: atención local, retropropagación determinista, ALiBi, etc. Estas tecnologías llevan el poder expresivo y la flexibilidad del modelo a un nivel superior.
Optimización de Hopper GPU: FlashAttention-3 ha optimizado especialmente su soporte para Hopper GPU y el rendimiento se ha mejorado en más de un punto y medio.
Fácil de instalar y usar: admite CUDA11.6 y PyTorch1.12 o superior, fácil de instalar con el comando pip en el sistema Linux. Aunque los usuarios de Windows pueden necesitar más pruebas, definitivamente vale la pena intentarlo.
Funciones principales:
Rendimiento eficiente: el algoritmo optimizado reduce en gran medida los requisitos informáticos y de memoria, especialmente para el procesamiento de datos de secuencia larga, y la mejora del rendimiento es visible a simple vista.
Optimización de la memoria: en comparación con los métodos tradicionales, FlashAttention consume menos memoria y la relación lineal hace que el uso de la memoria ya no sea un problema.
Funciones avanzadas: la integración de una variedad de tecnologías avanzadas mejora enormemente el rendimiento del modelo y el alcance de la aplicación.
Facilidad de uso y compatibilidad: la sencilla guía de instalación y uso, junto con la compatibilidad con múltiples arquitecturas de GPU, permiten que FlashAttention-3 se integre rápidamente en una variedad de proyectos.
Dirección del proyecto: https://github.com/Dao-AILab/flash-attention
Sin duda, la aparición de FlashAttention-3 acelerará la aplicación y el desarrollo de modelos de lenguaje a gran escala y traerá nuevos avances al campo de la inteligencia artificial. Su rendimiento eficiente y facilidad de uso lo convierten en una opción ideal para los desarrolladores. ¡Date prisa y experimentalo!