¡El editor de Downcodes revelará contigo la verdad sobre los modelos de lenguaje visual (VLM)! ¿Crees que los VLM pueden "comprender" imágenes como los humanos? La verdad no es tan simple. Este artículo explorará en profundidad las limitaciones de los VLM en la comprensión de imágenes y, a través de una serie de resultados experimentales, mostrará la enorme brecha entre ellos y las capacidades visuales humanas. ¿Estás listo para cambiar tu comprensión de los VLM?
Todo el mundo debería haber oído hablar de los modelos de lenguaje visual (VLM). Estos pequeños expertos en el campo de la IA no sólo pueden leer texto, sino también "ver" imágenes. Pero este no es el caso, hoy echemos un vistazo a sus “calzoncillos” para ver si realmente pueden “ver” y comprender imágenes como nosotros los humanos.
En primer lugar, tengo que brindarles algo de divulgación científica sobre qué son los VLM. En pocas palabras, son modelos de lenguaje de gran tamaño, como GPT-4o y Gemini-1.5Pro, que funcionan muy bien en el procesamiento de imágenes y texto, e incluso logran puntuaciones altas en muchas pruebas de comprensión visual. Pero no te dejes engañar por estas puntuaciones altas, hoy veremos si realmente son tan impresionantes.
Los investigadores diseñaron un conjunto de pruebas llamado BlindTest, que contiene siete tareas que son extremadamente simples para los humanos. Por ejemplo, determine si dos círculos se superponen, si dos líneas se cruzan o cuente cuántos círculos hay en el logotipo olímpico. ¿Parece que estas tareas pueden ser realizadas fácilmente por niños de jardín de infantes? Pero déjame decirte que el rendimiento de estos VLM no es tan impresionante.
Los resultados son impactantes. La precisión promedio de estos llamados modelos avanzados en BlindTest es de sólo 56,20%, y el mejor Sonnet-3.5 tiene una precisión de 73,77%. Esto es como un estudiante destacado que dice poder ingresar a la Universidad de Tsinghua y a la Universidad de Pekín, pero resulta que ni siquiera puede resolver correctamente las preguntas de matemáticas de la escuela primaria.

¿Por qué sucede esto? Los investigadores analizaron que puede deberse a que los VLM son como miopes al procesar imágenes y no pueden ver los detalles con claridad. Aunque pueden ver de forma aproximada la tendencia general de la imagen, cuando se trata de información espacial precisa, como si dos gráficos se cruzan o se superponen, se confunden.
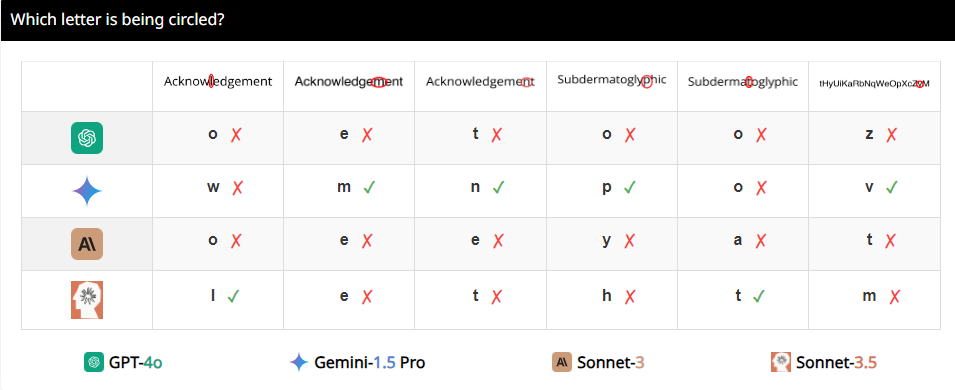
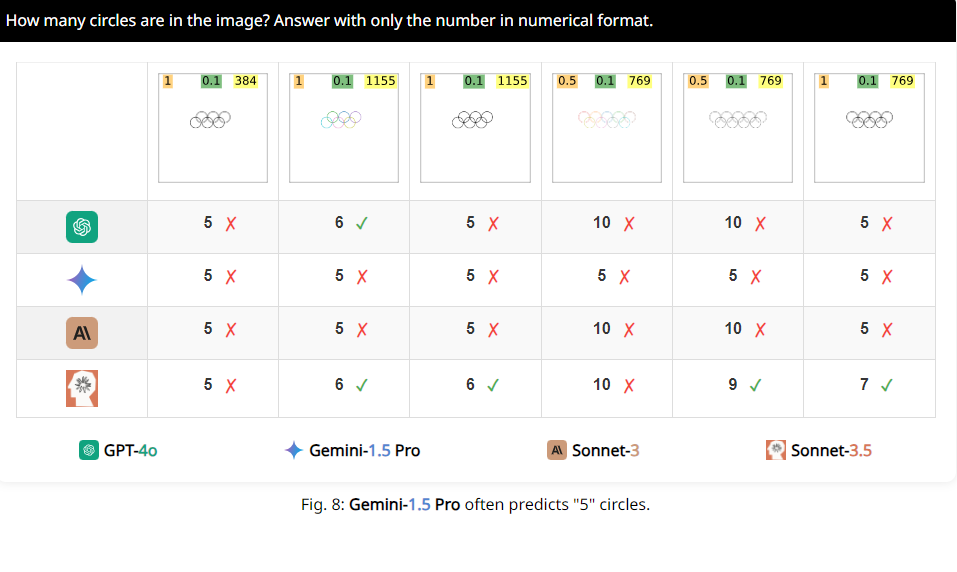
Por ejemplo, los investigadores pidieron a los VLM que determinaran si dos círculos se superponían y descubrieron que incluso si los dos círculos fueran tan grandes como sandías, estos modelos aún no podían responder la pregunta con un 100% de precisión. Además, cuando se les pidió que contaran el número de círculos en el logotipo olímpico, su desempeño fue difícil de describir.
Más interesante aún, los investigadores también descubrieron que estos VLM parecían tener una preferencia especial por el número 5 al contar. Por ejemplo, cuando el número de círculos en el logo olímpico excede 5, tienden a responder "5". Esto puede deberse a que hay 5 círculos en el logo olímpico y están particularmente familiarizados con este número.
Bien, dicho todo esto, ¿tienen una nueva comprensión de estos VLM aparentemente altos? De hecho, todavía tienen muchas limitaciones en la comprensión visual, que están lejos de alcanzar nuestro nivel humano. Entonces, la próxima vez que escuches a alguien decir que la IA puede reemplazar completamente a los humanos, puedes reírte.
Dirección del artículo: https://arxiv.org/pdf/2407.06581
Página del proyecto: https://vlmsareblind.github.io/
En resumen, aunque los VLM han logrado avances significativos en el campo del reconocimiento de imágenes, sus capacidades de razonamiento espacial preciso todavía tienen importantes deficiencias. Este estudio nos recuerda que la evaluación de la tecnología de IA no puede basarse únicamente en puntuaciones altas, sino que también requiere una comprensión profunda de sus limitaciones para evitar un optimismo ciego. ¡Esperamos que los VLM logren avances en la comprensión visual en el futuro!