El editor de Downcodes lo llevará a conocer una investigación innovadora de Google DeepMind: Mixture of Experts (MoE). Esta investigación ha logrado un progreso revolucionario en la arquitectura Transformer. Su núcleo radica en un mecanismo de recuperación experto eficiente en parámetros que utiliza tecnología clave de producto para equilibrar el costo computacional y la cantidad de parámetros, mejorando así en gran medida el potencial del modelo mientras se mantiene la eficiencia. Esta investigación no solo explora entornos extremos de MoE, sino que también demuestra por primera vez que la estructura del índice de aprendizaje puede dirigirse de manera efectiva a más de un millón de expertos, aportando nuevas posibilidades al campo de la IA.
El modelo Mixture de un millón de expertos propuesto por Google DeepMind es una investigación que ha dado pasos revolucionarios en la arquitectura Transformer.
Imagine un modelo que pueda realizar una recuperación escasa de un millón de microexpertos. ¿Suena esto un poco como la trama de una novela de ciencia ficción? Pero eso es exactamente lo que muestra la última investigación de DeepMind. El núcleo de esta investigación es un mecanismo de recuperación experto eficiente en parámetros que utiliza tecnología clave de producto para desacoplar el costo computacional del recuento de parámetros, liberando así el mayor potencial de la arquitectura Transformer mientras se mantiene la eficiencia computacional.
Lo más destacado de este trabajo es que no solo explora entornos extremos del MoE, sino que también demuestra por primera vez que una estructura de índice aprendida se puede enviar de manera eficiente a más de un millón de expertos. Esto es como encontrar rápidamente algunos expertos que puedan resolver el problema entre una gran multitud, y todo esto se hace bajo la premisa de costos informáticos controlables.
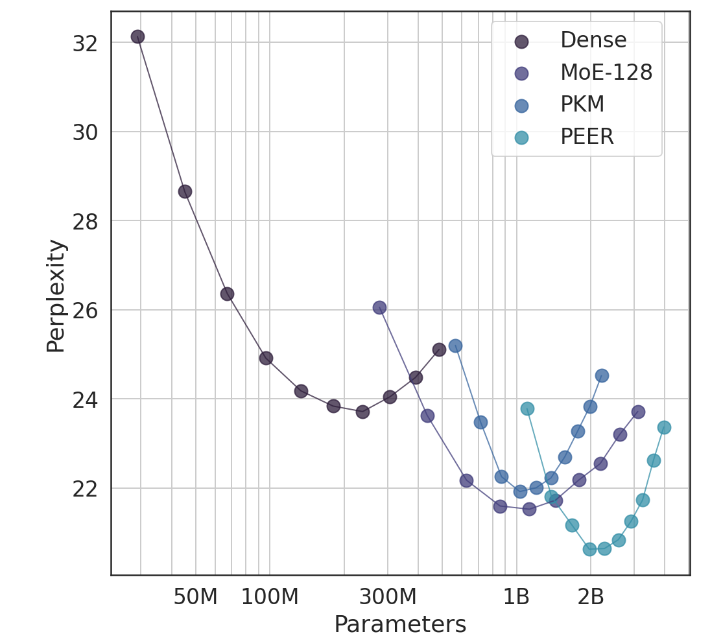
En experimentos, la arquitectura PEER demostró un rendimiento informático superior y fue más eficiente que las capas densas de FFW, MoE de grano grueso y memoria de clave de producto (PKM). Esto no es sólo una victoria teórica, sino también un gran salto en la aplicación práctica. A través de los resultados empíricos, podemos ver el desempeño superior de PEER en tareas de modelado de lenguaje. No solo tiene menor perplejidad, sino también en el experimento de ablación, al ajustar el número de expertos y el número de expertos activos, el desempeño de PEER. El modelo ha sido mejorado significativamente.
El autor de este estudio, Xu He (Owen), es un científico investigador de Google DeepMind. Sin duda, su exploración en solitario ha aportado nuevas revelaciones al campo de la IA. Como demostró, a través de métodos personalizados e inteligentes, podemos mejorar significativamente las tasas de conversión y retener a los usuarios, lo cual es especialmente importante en el campo AIGC.
Dirección del artículo: https://arxiv.org/abs/2407.04153
En definitiva, la investigación de modelos híbridos de un millón de expertos de Google DeepMind proporciona nuevas ideas para la construcción de modelos de lenguaje a gran escala. Su eficiente mecanismo de recuperación experto y sus excelentes resultados experimentales indican un gran potencial para el desarrollo futuro de modelos de IA. ¡El editor de Downcodes espera obtener más resultados de investigación innovadores similares!