En los últimos años, han surgido una tras otra innovaciones en modelos de lenguajes grandes (LLM), que desafían constantemente los límites de las arquitecturas existentes. El editor de Downcodes se enteró de que investigadores de Stanford, UCSD, UC Berkeley y Meta propusieron conjuntamente una nueva arquitectura llamada TTT (Test-Time-Training Layers) que se espera que cambie por completo nuestra comprensión del lenguaje. El modelo es reconocido y aplicado. Al combinar inteligentemente las ventajas de RNN y Transformer, la arquitectura TTT mejora significativamente la capacidad expresiva del modelo al tiempo que garantiza la complejidad lineal. Funciona particularmente bien al procesar textos largos, aportando nuevos conocimientos a campos como la posibilidad de modelado de videos largos.
En el mundo de la IA, los cambios siempre llegan inesperadamente. Recientemente, surgió una nueva arquitectura llamada TTT, propuesta conjuntamente por investigadores de Stanford, UCSD, UC Berkeley y Meta. Subvirtió a Transformer y Mamba de la noche a la mañana y trajo cambios revolucionarios a los modelos de lenguaje.
TTT, el nombre completo de las capas Test-Time-Training, es una arquitectura completamente nueva que comprime el contexto mediante el descenso de gradientes y reemplaza directamente el mecanismo de atención tradicional. Este enfoque no solo mejora la eficiencia, sino que también desbloquea una arquitectura de complejidad lineal con memoria expresiva, lo que nos permite entrenar LLM que contienen millones o incluso miles de millones de tokens en contexto.

La propuesta de la capa TTT se basa en un conocimiento profundo de las arquitecturas RNN y Transformer existentes. Aunque RNN es muy eficiente, está limitado por su capacidad expresiva; mientras que Transformer tiene una gran capacidad expresiva, su costo computacional aumenta linealmente con la longitud del contexto. La capa TTT combina inteligentemente las ventajas de ambas, manteniendo la complejidad lineal y mejorando las capacidades expresivas.
En experimentos, ambas variantes, TTT-Linear y TTT-MLP, demostraron un rendimiento excelente, superando a Transformer y Mamba tanto en contextos cortos como largos. Especialmente en escenarios de contexto prolongado, las ventajas de la capa TTT son más obvias, lo que proporciona un enorme potencial para escenarios de aplicación como el modelado de videos prolongados.
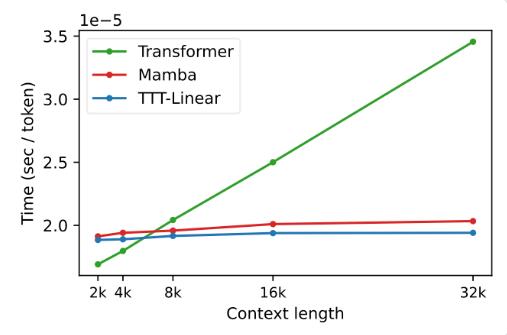
La propuesta de la capa TTT no sólo es innovadora en teoría, sino que también muestra un gran potencial en aplicaciones prácticas. En el futuro, se espera que la capa TTT se aplique al modelado de video largo para proporcionar información más rica mediante un muestreo denso de cuadros. Esto es una carga para Transformer, pero es una bendición para la capa TTT.
Esta investigación es el resultado de cinco años de arduo trabajo por parte del equipo y se ha estado gestando desde el período postdoctoral del Dr. Yu Sun. Persistieron en explorar e intentar, y finalmente lograron este resultado revolucionario. El éxito de la capa TTT es el resultado de los incansables esfuerzos y el espíritu innovador del equipo.
La llegada de la capa TTT ha aportado nueva vitalidad y posibilidades al campo de la IA. No sólo cambia nuestra comprensión de los modelos lingüísticos, sino que también abre un nuevo camino para futuras aplicaciones de IA. Esperemos con ansias la aplicación y el desarrollo futuros de la capa TTT y seamos testigos del progreso y los avances de la tecnología de IA.
Dirección del artículo: https://arxiv.org/abs/2407.04620
Sin duda, el surgimiento de la arquitectura TTT ha inyectado un impulso al campo de la IA. Su avance revolucionario en el procesamiento de textos largos indica que las futuras aplicaciones de IA tendrán capacidades de procesamiento más potentes y perspectivas de aplicación más amplias. Esperemos y veamos cómo la arquitectura TTT cambiará aún más nuestro mundo.