¡El editor de Downcodes te trae grandes novedades! Cerebras Systems lanzó el servicio de inferencia de IA más rápido del mundo: Cerebras Inference, que ha cambiado por completo las reglas del juego en el campo de la inferencia de IA con su asombrosa velocidad y su precio extremadamente competitivo. Funciona bien en el procesamiento de varios modelos de IA, especialmente modelos de lenguaje grande (LLM), y es 20 veces más rápido que los sistemas GPU tradicionales a un precio tan bajo como una décima o incluso una centésima. ¿Cómo afectará esto al desarrollo futuro de las aplicaciones de IA? Echemos un vistazo más de cerca.
Cerebras Systems, pionera en informática de rendimiento con IA, ha introducido una solución innovadora que revolucionará la inferencia de IA. El 27 de agosto de 2024, la compañía anunció el lanzamiento de Cerebras Inference, el servicio de inferencia de IA más rápido del mundo. Los indicadores de rendimiento de Cerebras Inference eclipsan a los sistemas tradicionales basados en GPU, proporcionando 20 veces la velocidad a un costo extremadamente bajo, estableciendo un nuevo punto de referencia para la informática de IA.
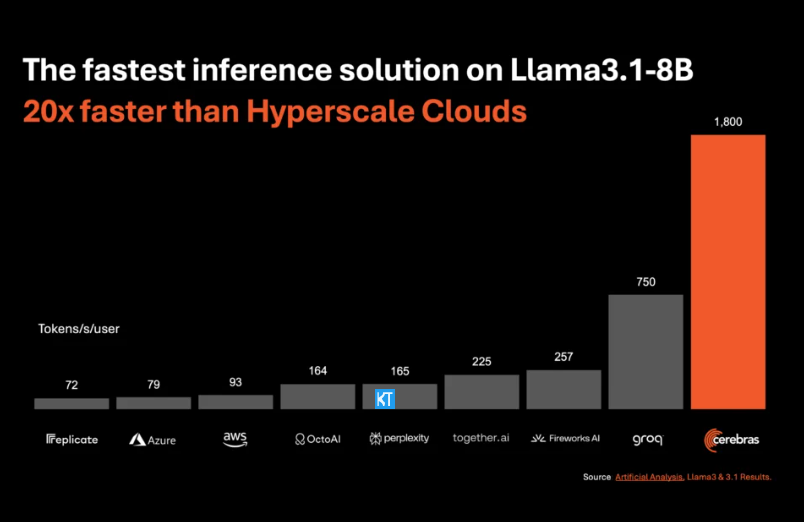
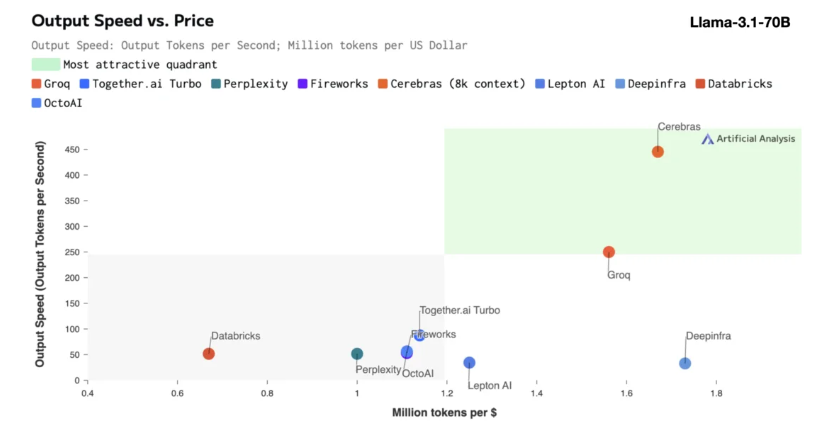
La inferencia de Cerebras es particularmente adecuada para procesar varios tipos de modelos de IA, especialmente los "modelos de lenguaje grande" (LLM) en rápido desarrollo. Tomando como ejemplo el último modelo Llama3.1, su versión 8B puede procesar 1.800 tokens por segundo, mientras que la versión 70B puede procesar 450 tokens. Esto no sólo es 20 veces más rápido que las soluciones de GPU de NVIDIA, sino que también tiene un precio más competitivo. El precio de Cerebras Inference comienza en sólo 10 centavos por millón de tokens, y la versión 70B es de 60 centavos. En comparación con los productos GPU existentes, la relación precio/rendimiento se mejora 100 veces.
Es impresionante que Cerebras Inference alcance esta velocidad manteniendo una precisión líder en la industria. A diferencia de otras soluciones que priorizan la velocidad, Cerebras siempre realiza inferencias en el dominio de 16 bits, lo que garantiza que las mejoras de rendimiento no se produzcan a expensas de la calidad de salida del modelo de IA. Micha Hill-Smith, directora ejecutiva de Artificial Analytics, dijo que Cerebras logró una velocidad de más de 1.800 tokens de salida por segundo en el modelo Llama3.1 de Meta, estableciendo un nuevo récord.
La inferencia de IA es el segmento de más rápido crecimiento de la informática de IA y representa aproximadamente el 40% de todo el mercado de hardware de IA. La inferencia de IA de alta velocidad, como la proporcionada por Cerebras, es como el surgimiento de Internet de banda ancha, que abre nuevas oportunidades y marca el comienzo de una nueva era para las aplicaciones de IA. Los desarrolladores pueden utilizar Cerebras Inference para crear aplicaciones de IA de próxima generación que requieren un rendimiento complejo en tiempo real, como agentes inteligentes y sistemas inteligentes.
Cerebras Inference ofrece tres niveles de servicio a precios razonables: nivel gratuito, nivel de desarrollador y nivel empresarial. El nivel gratuito proporciona acceso a la API con límites de uso generosos, lo que lo hace ideal para una amplia gama de usuarios. El nivel de desarrollador proporciona opciones flexibles de implementación sin servidor, mientras que el nivel empresarial proporciona servicios personalizados y soporte para organizaciones con cargas de trabajo continuas.
En términos de tecnología central, Cerebras Inference utiliza el sistema CerebrasCS-3, impulsado por el Wafer Scale Engine3 (WSE-3) líder en la industria. Este procesador de IA no tiene paralelo en escala y velocidad y proporciona 7000 veces más ancho de banda de memoria que el NVIDIA H100.
Cerebras Systems no solo lidera la tendencia en el campo de la computación con IA, sino que también desempeña un papel importante en múltiples industrias como la médica, energética, gubernamental, informática científica y servicios financieros. Al avanzar continuamente en la innovación tecnológica, Cerebras está ayudando a organizaciones de diversos campos a abordar desafíos complejos de IA.
Destacar:
La velocidad del servicio de Cerebras Systems se multiplica por 20, su precio es más competitivo y abre una nueva era de razonamiento de IA.
Admite varios modelos de IA, y funciona especialmente bien en modelos de lenguajes grandes (LLM).
Se proporcionan tres niveles de servicio para facilitar que los desarrolladores y usuarios empresariales elijan con flexibilidad.
En definitiva, la aparición de Cerebras Inference marca un hito importante en el campo de la inferencia de IA. Su excelente rendimiento y economía promoverán la popularización generalizada y el desarrollo innovador de las aplicaciones de IA, ¡y merece la atención y anticipación de la industria! El editor de Downcodes seguirá brindándole más información sobre tecnología de punta.