Hoy en día, con el rápido desarrollo de la tecnología de inteligencia artificial, los modelos de lenguaje pequeño (SLM) han atraído mucha atención debido a su capacidad para ejecutarse en dispositivos con recursos limitados. El equipo de Nvidia lanzó recientemente Llama-3.1-Minitron4B, un excelente modelo de lenguaje pequeño basado en la compresión del modelo Llama 3. Utiliza tecnologías de destilación y poda de modelos para competir con modelos más grandes en rendimiento, al tiempo que tiene ventajas de implementación y entrenamiento eficientes, lo que brinda nuevas posibilidades a las aplicaciones de IA. El editor de Downcodes lo llevará a comprender en profundidad este avance tecnológico.
En una era en la que las empresas de tecnología persiguen la inteligencia artificial en los dispositivos, están surgiendo cada vez más modelos de lenguaje pequeño (SLM) que pueden ejecutarse en dispositivos con recursos limitados. Recientemente, el equipo de investigación de Nvidia utilizó tecnología de destilación y poda de modelos de vanguardia para lanzar Llama-3.1-Minitron4B, una versión comprimida del modelo Llama3. Este nuevo modelo no sólo es comparable en rendimiento a modelos más grandes, sino que también compite con modelos más pequeños del mismo tamaño, al tiempo que es más eficiente en entrenamiento e implementación.
La poda y la destilación son dos técnicas clave para crear modelos de lenguaje más pequeños y eficientes. La poda se refiere a la eliminación de partes sin importancia del modelo, incluida la "poda en profundidad", que elimina capas enteras, y la "poda en ancho", que elimina elementos específicos como neuronas y cabezas de atención. La destilación de modelos, por otro lado, transfiere conocimientos y capacidades de un modelo grande (es decir, "modelo de profesor") a un "modelo de estudiante" más pequeño y simple.
Hay dos métodos principales de destilación: el primero es a través del "entrenamiento SGD", que permite al modelo de estudiante aprender las entradas y respuestas del modelo de maestro. El segundo es la "destilación de conocimientos clásicos". el modelo de estudiante también necesita la activación interna del modelo de profesor de aprendizaje.
En un estudio anterior, los investigadores de Nvidia redujeron con éxito el modelo Nemotron15B a un modelo de 800 millones de parámetros mediante poda y destilación y, finalmente, lo redujeron aún más a 400 millones de parámetros. Este proceso no solo mejora el rendimiento en un 16 % en el famoso punto de referencia MMLU, sino que también requiere 40 veces menos datos de entrenamiento que entrenar desde cero.
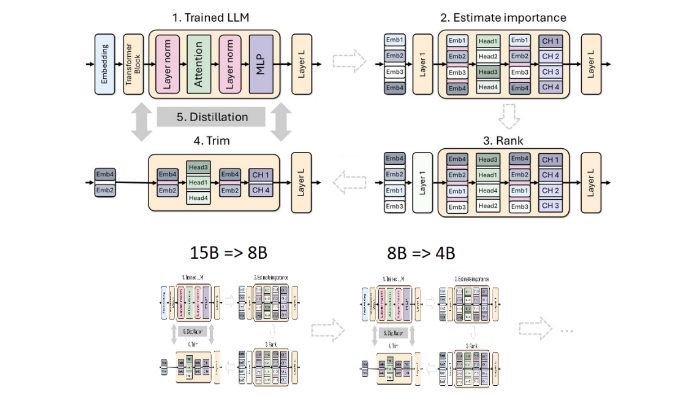
Esta vez, el equipo de Nvidia utilizó el mismo método para crear un modelo de 400 millones de parámetros basado en el modelo Llama3.18B. Primero, ajustaron el modelo 8B no podado en un conjunto de datos que contenía 94 mil millones de tokens para hacer frente a las diferencias de distribución entre los datos de entrenamiento y el conjunto de datos destilados. Luego, se utilizaron dos métodos de poda en profundidad y poda en ancho, y finalmente se obtuvieron dos versiones diferentes de Llama-3.1-Minitron4B.
Los investigadores ajustaron el modelo podado a través de NeMo-Aligner y evaluaron sus capacidades en seguimiento de instrucciones, juegos de roles, generación de aumento de recuperación (RAG) y llamada de funciones.
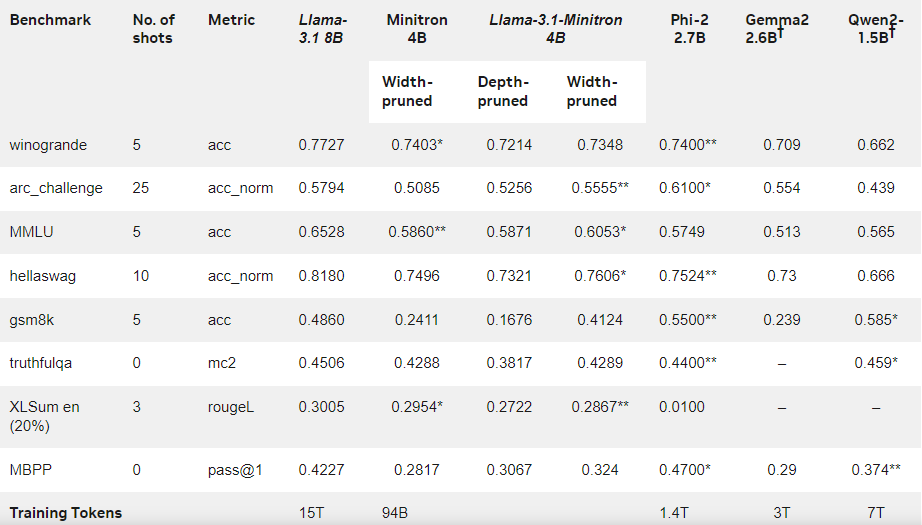
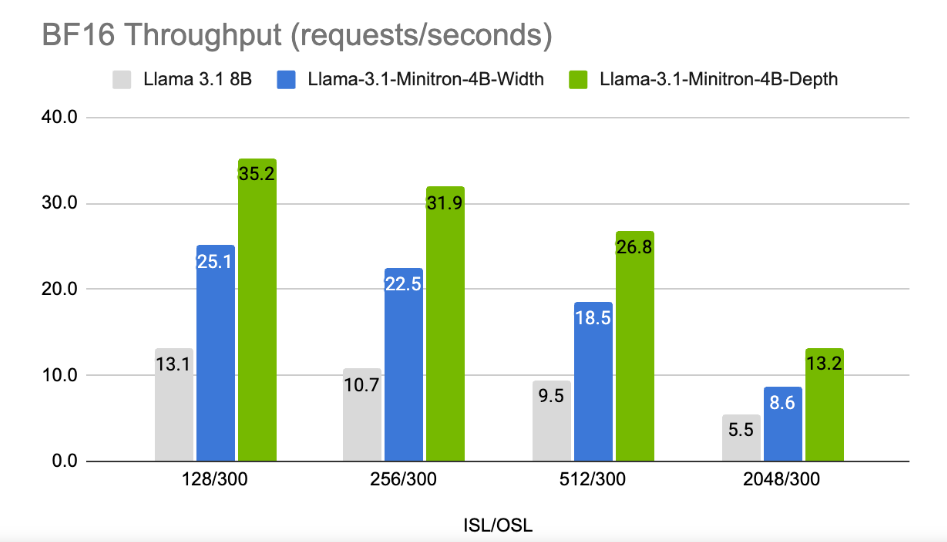
Los resultados muestran que a pesar de la pequeña cantidad de datos de entrenamiento, el rendimiento de Llama-3.1-Minitron4B todavía se acerca al de otros modelos pequeños y funciona bien. La versión reducida en ancho del modelo se lanzó en Hugging Face, lo que permite el uso comercial para ayudar a más usuarios y desarrolladores a beneficiarse de su eficiencia y excelente rendimiento.
Blog oficial: https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model /
Destacar:
Llama-3.1-Minitron4B es un modelo de lenguaje pequeño lanzado por Nvidia basado en tecnología de poda y destilación, con capacidades eficientes de capacitación e implementación.
La cantidad de marcadores utilizados en el proceso de entrenamiento de este modelo se reduce 40 veces en comparación con el entrenamiento desde cero, pero el rendimiento mejora significativamente.
? La versión de poda de ancho se lanzó en Hugging Face para facilitar el uso y desarrollo comercial de los usuarios.
Con todo, la aparición de Llama-3.1-Minitron4B marca un nuevo hito en el desarrollo de modelos de lenguajes pequeños. Su rendimiento eficiente y su conveniente método de implementación traerán buenas noticias a más desarrolladores y usuarios y acelerarán la popularización y aplicación de la tecnología de inteligencia artificial. El editor de Downcodes espera más innovaciones similares en el futuro.