En el entrenamiento de modelos de lenguaje grande (LLM), el mecanismo de punto de control es crucial, ya que puede evitar efectivamente grandes pérdidas causadas por interrupciones en el entrenamiento. Sin embargo, los sistemas de puntos de control tradicionales a menudo enfrentan cuellos de botella de E/S y son ineficientes. Para ello, científicos de ByteDance y la Universidad de Hong Kong propusieron un nuevo sistema de puntos de control llamado ByteCheckpoint, que puede mejorar significativamente la eficiencia de la formación LLM.
En un mundo digital dominado por datos y algoritmos, cada paso del crecimiento de la inteligencia artificial es inseparable de un elemento clave: el punto de control. Imagine que cuando está entrenando un modelo de lenguaje a gran escala que puede comprender la mente de las personas y responder preguntas con fluidez, este modelo es extremadamente inteligente, pero también come mucho y requiere recursos informáticos masivos para alimentarlo. Durante el proceso de capacitación, si hay un corte repentino de energía o una falla de hardware, la pérdida será enorme. En este momento, el punto de control es como una máquina del tiempo, permitiendo que todo vuelva al estado seguro anterior y continúe con las tareas pendientes.
Sin embargo, la propia máquina del tiempo también requirió un diseño cuidadoso. Los científicos de ByteDance y la Universidad de Hong Kong nos trajeron un nuevo sistema de puntos de control: ByteCheckpoint en el artículo "ByteCheckpoint: un sistema de puntos de control unificado para el desarrollo de LLM". No es solo una simple herramienta de respaldo, sino también un artefacto que puede mejorar en gran medida la eficiencia del entrenamiento de modelos de lenguaje grandes.
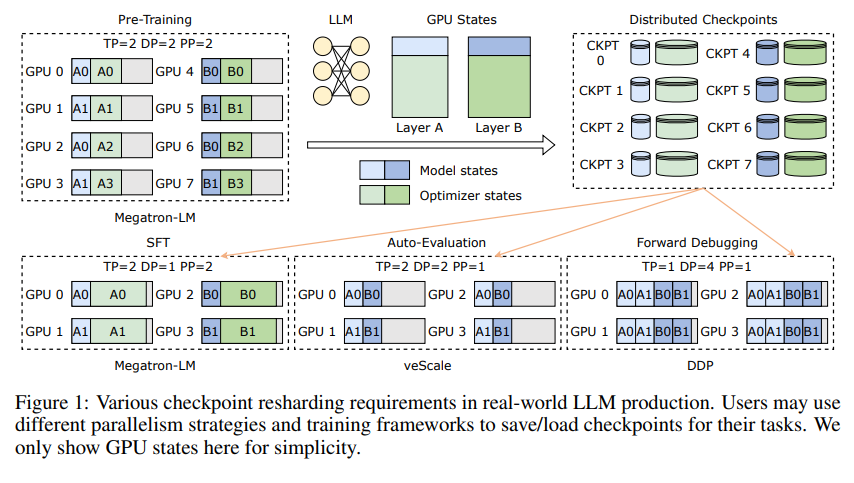
Primero, debemos comprender los desafíos que enfrentan los modelos de lenguajes grandes (LLM). La razón por la que estos modelos son grandes es que necesitan procesar y recordar cantidades masivas de información, lo que trae problemas como altos costos de capacitación, gran consumo de recursos y baja tolerancia a fallas. Una vez que se produce un mal funcionamiento, puede provocar que un largo período de entrenamiento sea insatisfactorio.
El sistema de puntos de control es como una instantánea del modelo: guarda el estado periódicamente durante el proceso de entrenamiento, de modo que incluso si algo sale mal, se puede restaurar rápidamente al estado más reciente y reducir las pérdidas. Sin embargo, los sistemas de puntos de control existentes a menudo sufren de ineficiencias debido a cuellos de botella de E/S (entrada/salida) al procesar modelos grandes.
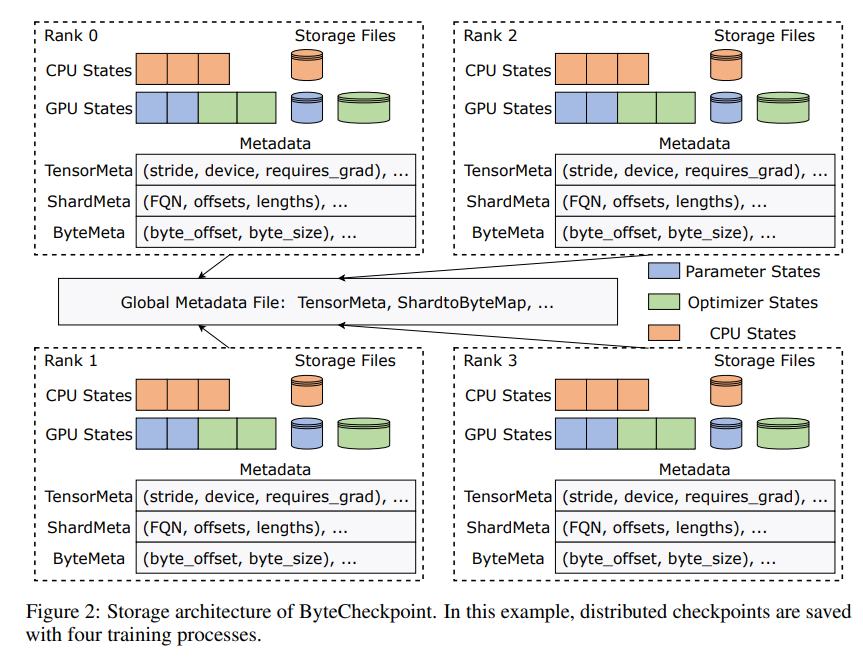
La innovación de ByteCheckpoint radica en la adopción de una arquitectura de almacenamiento novedosa que separa datos y metadatos y maneja de manera más flexible los puntos de control bajo diferentes configuraciones paralelas y marcos de capacitación. Aún mejor, admite la fragmentación automática de puntos de control en línea, que puede ajustar dinámicamente los puntos de control para adaptarse a diferentes entornos de hardware sin interrumpir la capacitación.
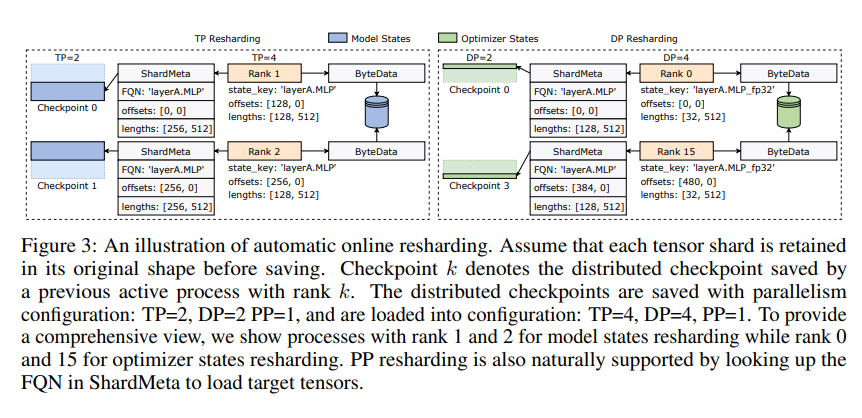
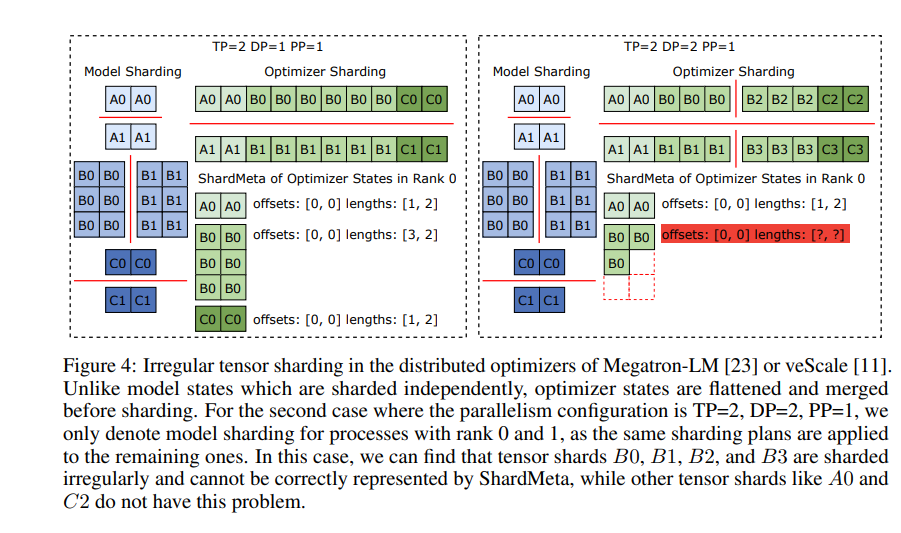
ByteCheckpoint también presenta una tecnología clave: la fusión de tensores asíncronos. Esto puede manejar de manera eficiente tensores que están distribuidos de manera desigual en diferentes GPU, lo que garantiza que la integridad y la coherencia del modelo no se vean afectadas cuando se vuelven a fragmentar los puntos de control.
Para mejorar la velocidad de guardado y carga de los puntos de control, ByteCheckpoint también integra una serie de medidas de optimización del rendimiento de E/S, como una sofisticada canalización de guardado/carga, grupo de memoria Ping-Pong, guardado equilibrado de carga de trabajo y carga sin redundancia, etc. , lo que reduce en gran medida el tiempo de espera durante el proceso de formación.
A través de la verificación experimental, en comparación con los métodos tradicionales, las velocidades de carga y guardado del punto de control de ByteCheckpoint aumentan docenas o incluso cientos de veces respectivamente, lo que mejora significativamente la eficiencia del entrenamiento de modelos de lenguaje grandes.
ByteCheckpoint no es solo un sistema de puntos de control, sino también un poderoso asistente en el proceso de capacitación de modelos de lenguaje grandes. Es la clave para una capacitación de IA más eficiente y estable.
Dirección del artículo: https://arxiv.org/pdf/2407.20143
El editor de Downcodes resume: La aparición de ByteCheckpoint resuelve el problema de la baja eficiencia de los puntos de control en la formación de LLM y proporciona un sólido soporte técnico para el desarrollo de la IA. ¡Vale la pena prestarle atención!