El editor de Downcodes lo lleva a través de un interesante experimento de inteligencia artificial: el usuario de Reddit @zefman creó una plataforma para permitir que diferentes modelos de lenguaje (LLM) jueguen ajedrez en tiempo real. Este experimento evalúa la capacidad de cada LLM para jugar al ajedrez de una manera relajada e interesante. Los resultados son inesperados, ¡echemos un vistazo!
Recientemente, el usuario de Reddit @zefman llevó a cabo un experimento interesante, configurando una plataforma para enfrentar diferentes modelos de lenguaje (LLM) contra ajedrez en tiempo real, con el objetivo de brindar a los usuarios una manera fácil y divertida de evaluar el desempeño de estos modelos.
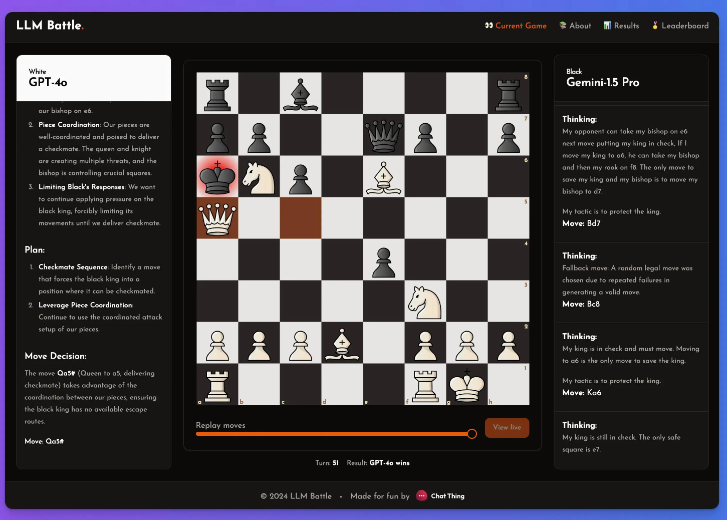
No es ningún secreto que estos modelos no son buenos jugando al ajedrez, pero aun así, sintió que había algunos puntos destacados en este experimento.
En este experimento, @zefman prestó especial atención a varios modelos más recientes, entre los cuales el GPT-4o tuvo un desempeño más destacado y se convirtió sin lugar a dudas en el jugador más fuerte. Al mismo tiempo, @zefman también lo comparó con otros modelos como Claude y Gemini para observar sus diferencias de desempeño y descubrió que el proceso de pensamiento y razonamiento de cada modelo es muy interesante. A través de esta plataforma todos pueden ver detrás de la toma de decisiones de cada paso y cómo el modelo analiza la partida de ajedrez.
El método de visualización del juego de ajedrez diseñado por @zefman es bastante simple. Cuando cada modelo se enfrenta al mismo estado del tablero de ajedrez, dará las mismas indicaciones, incluido el estado actual del juego de ajedrez, FEN (representación de la posición del ajedrez) y sus dos movimientos anteriores. Este enfoque garantiza que las decisiones de cada modelo se basen en la misma información, lo que permite una comparación más justa.
Cada modelo utiliza exactamente el mismo mensaje, que se actualiza con el estado del tablero en ASCI, FEN y sus dos movimientos y pensamientos anteriores. Aquí hay un ejemplo:
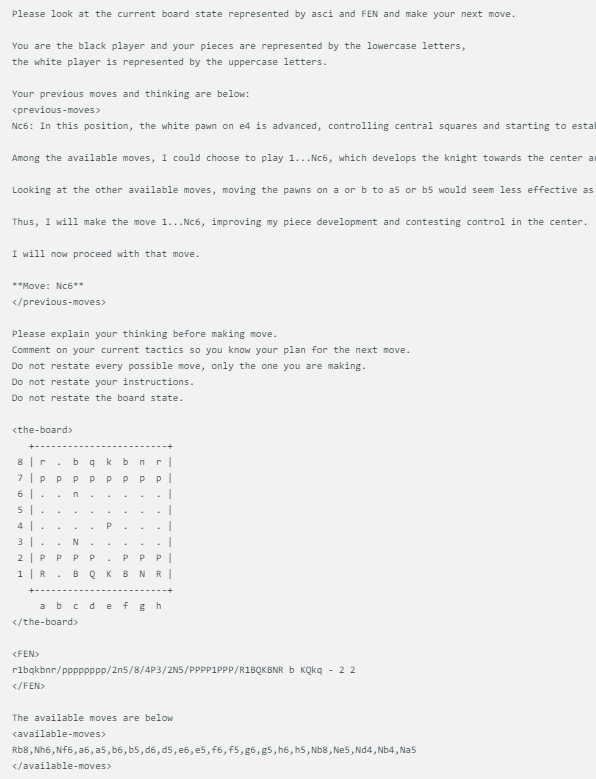
Además, @zefman también notó que en algunos casos, especialmente para algunos modelos más débiles, pueden elegir el movimiento equivocado varias veces. Para resolver este problema, les dio a estos modelos 5 oportunidades para volver a seleccionar. Si aun así no lograban elegir un movimiento válido, seleccionarían aleatoriamente un movimiento válido, manteniendo así el juego.
Concluyó: GTP-4o sigue siendo el más fuerte, superando a Gemini1.5pro en ajedrez.
A través de este experimento, no solo vimos las diferencias entre diferentes LLM en el campo del ajedrez, sino que también vimos el ingenioso diseño y el espíritu experimental de @zefman. ¡Esperamos más experimentos similares en el futuro, que nos brindarán una comprensión más profunda del potencial y las limitaciones del LLM!