El último proyecto de Meta AI, Llama3, ha atraído una gran atención. El editor de Downcodes le brindará una comprensión profunda de su tecnología central y la dirección de desarrollo futuro. El investigador de Meta AI Thomas Scialom fue entrevistado recientemente, quien compartió los detalles del desarrollo de Llama3 y brindó información única sobre los problemas existentes en el entrenamiento de modelos de lenguaje a gran escala. En particular, enfatizó el importante papel de los datos sintéticos en el entrenamiento de Llama3 y cómo utilizar eficazmente la retroalimentación humana para mejorar el rendimiento del modelo. Este artículo explicará en detalle los métodos de capacitación, las áreas de aplicación y los planes de desarrollo futuros de Llama3, presentando a los lectores una perspectiva integral y profunda.
Thomas Scialom, investigador de Meta AI, compartió recientemente algunas ideas sobre su último proyecto, Llama3, en una entrevista. Señala sin rodeos que las grandes cantidades de texto que hay en la web son de calidad variable y cree que capacitarse sobre estos datos es un desperdicio de recursos. Por lo tanto, el proceso de entrenamiento de Llama3 no se basa en respuestas escritas por humanos, sino que se basa completamente en los datos sintéticos generados por Llama2.
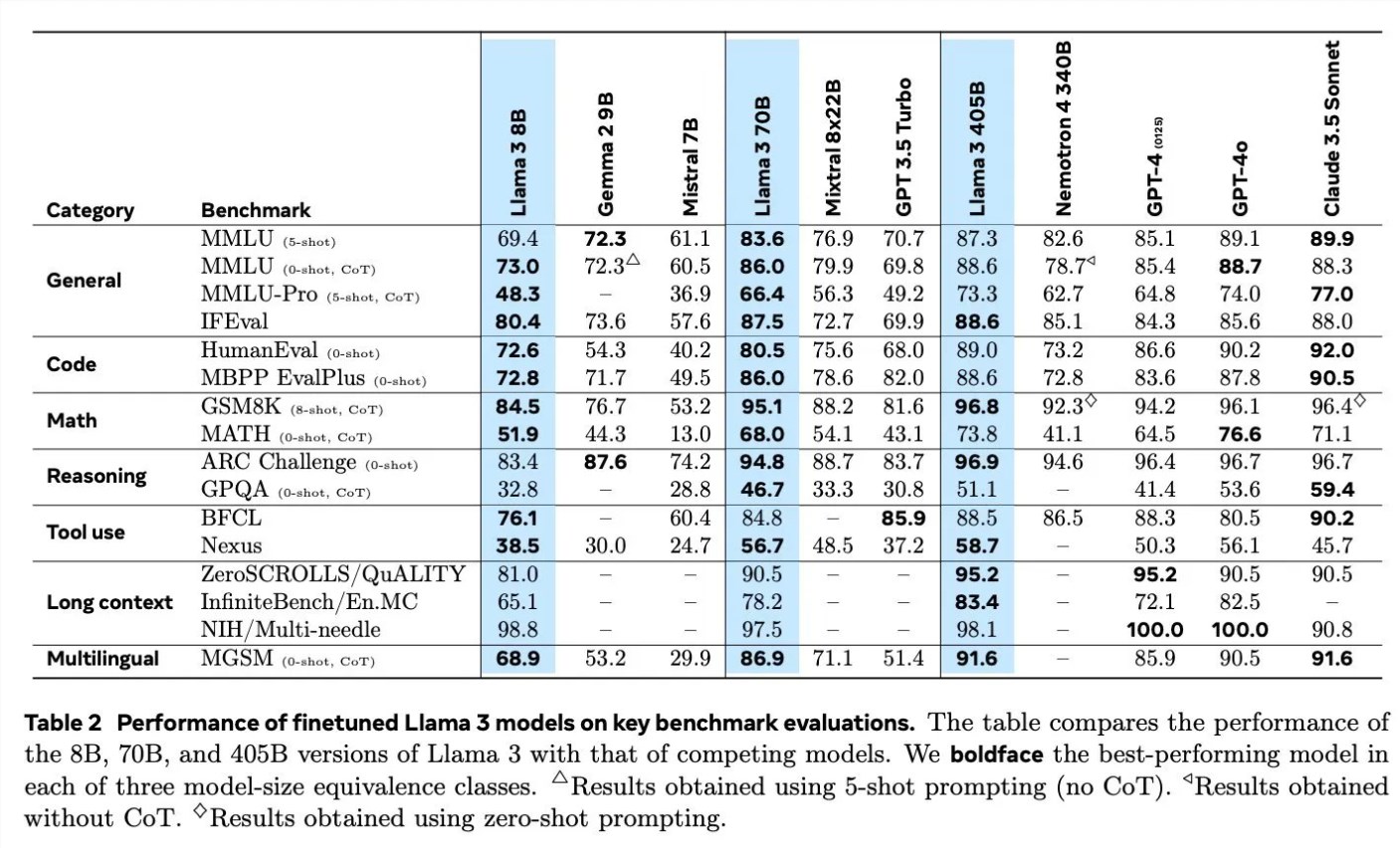
Al discutir los detalles del entrenamiento de Llama3, Scialom detalló la aplicación de datos sintéticos en diferentes campos. Por ejemplo, en términos de generación de código, utilizaron tres métodos diferentes para generar datos sintéticos, incluida la retroalimentación de la ejecución del código, la traducción de lenguajes de programación y la retrotraducción de documentación. En términos de razonamiento matemático, se basaron en el enfoque de investigación de “vamos paso a paso” para la generación de datos. Además, Llama3 continúa entrenándose previamente con un 90% de tokens en varios idiomas para recopilar anotaciones humanas de alta calidad, lo cual es particularmente importante en el procesamiento en varios idiomas.
El procesamiento de textos largos también es un foco de Llama3, y se basan en datos sintéticos para manejar respuestas a preguntas de textos largos, resúmenes de documentos largos e inferencias de base de código. En términos de uso de herramientas, Llama3 recibió capacitación en los intérpretes Brave Search, Wolfram Alpha y Python para implementar llamadas a funciones únicas, anidadas, paralelas y de múltiples rondas.
Scialom también mencionó la importancia del aprendizaje reforzado con retroalimentación humana (RLHF) en el entrenamiento de Llama3. Hicieron un uso extensivo de datos de preferencias humanas para entrenar el modelo, enfatizando la capacidad de los humanos para tomar decisiones (como elegir cuál de dos poemas preferir) en lugar de comenzar desde cero.
Meta comenzó el entrenamiento de Llama4 en junio, y Scialom reveló que un enfoque principal de Llama4 estará en torno al agente inteligente. Además, también mencionó una versión multimodal de Llama, que tendrá más parámetros y cuyo lanzamiento está previsto en un futuro próximo.
La entrevista de Scialom revela los últimos avances de Meta AI y las direcciones de desarrollo futuro en el campo de la inteligencia artificial, especialmente en cómo utilizar datos sintéticos y comentarios humanos para mejorar el rendimiento del modelo.
A través de la entrevista de Scialom, conocimos las innovaciones de Llama3 en la utilización de datos y el entrenamiento de modelos, así como la exploración continua de Meta AI en el campo de los modelos de lenguaje a gran escala. La exitosa experiencia de Llama3 proporciona una referencia valiosa para el desarrollo de futuros modelos de inteligencia artificial y también indica que la tecnología de inteligencia artificial se desarrollará en una dirección más precisa y eficiente. El editor de Downcodes espera con ansias el lanzamiento de Llama4 y Llama multimodal, y continúa prestando atención al gran progreso de Meta AI en el campo de la inteligencia artificial.