Mejorar la eficiencia de los grandes modelos lingüísticos siempre ha sido un punto candente de investigación en el campo de la inteligencia artificial. Recientemente, equipos de investigación de Aleph Alpha, la Universidad Técnica de Darmstadt y otras instituciones han desarrollado un nuevo método llamado T-FREE, que mejora significativamente la eficiencia operativa de grandes modelos de lenguaje. Este método reduce la cantidad de parámetros de la capa de incrustación mediante el uso de triples de caracteres para una activación escasa y modela de manera efectiva la similitud morfológica entre palabras. Reduce en gran medida el consumo de recursos informáticos al tiempo que garantiza el rendimiento del modelo. Esta innovadora tecnología ofrece nuevas posibilidades para la aplicación de grandes modelos de lenguaje.
El equipo de investigación introdujo recientemente un método nuevo e interesante llamado T-FREE, que permite disparar la eficiencia operativa de modelos de lenguaje grandes. Científicos de Aleph Alpha, TU Darmstadt, hessian.AI y el Centro Alemán de Investigación de Inteligencia Artificial (DFKI) han lanzado conjuntamente esta asombrosa tecnología, cuyo nombre completo es "Representación dispersa sin etiquetas, es posible una incrustación eficiente en la memoria".
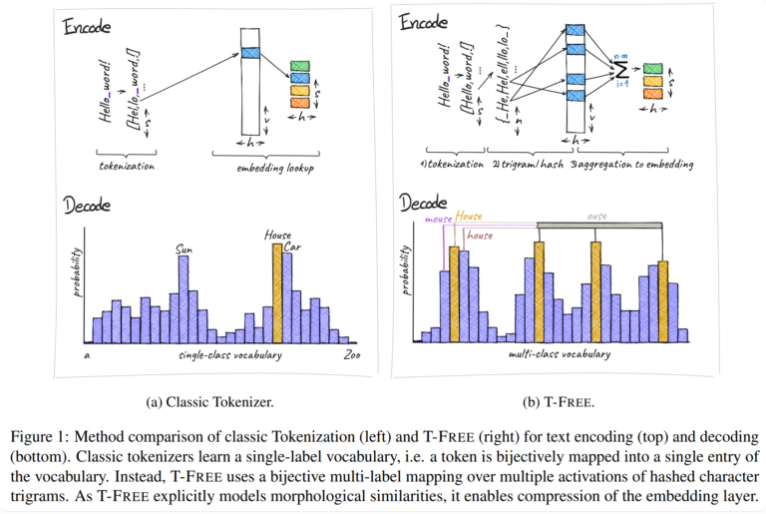
Tradicionalmente, utilizamos tokenizadores para convertir texto a una forma numérica que las computadoras puedan entender, pero T-FREE ha elegido un camino diferente. Utiliza triples de caracteres, lo que llamamos "triples", para incrustar palabras directamente en el modelo mediante activación dispersa. Como resultado de este movimiento innovador, la cantidad de parámetros en la capa de incrustación se redujo en un sorprendente 85% o más, mientras que el rendimiento del modelo no se vio afectado en absoluto al manejar tareas como la clasificación de texto y la respuesta a preguntas.
Otro punto a destacar de T-FREE es que modela de manera muy inteligente las similitudes morfológicas entre palabras. Al igual que las palabras "casa", "casa" y "doméstico" que encontramos a menudo en la vida diaria, T-FREE puede representar más eficazmente estas palabras similares en el modelo. Los investigadores creen que palabras similares deberían integrarse más cerca unas de otras para lograr tasas de compresión más altas. Por lo tanto, T-FREE no solo reduce el tamaño de la capa de incrustación, sino que también reduce la longitud promedio de codificación del texto en un 56%.
Lo que es más digno de mencionar es que T-FREE funciona particularmente bien en la transferencia de aprendizaje entre diferentes idiomas. En un experimento, los investigadores utilizaron un modelo con 3 mil millones de parámetros, entrenado primero en inglés y luego en alemán, y descubrieron que T-FREE era mucho más adaptable que los métodos tradicionales basados en etiquetado.
Sin embargo, los investigadores siguen siendo modestos acerca de sus resultados actuales. Admiten que hasta ahora los experimentos se han limitado a modelos con hasta 3 mil millones de parámetros, y en el futuro están previstas más evaluaciones con modelos y conjuntos de datos más grandes.
La aparición del método T-FREE proporciona nuevas ideas para mejorar la eficiencia de modelos de lenguaje grandes. Sus ventajas para reducir los costos computacionales y mejorar el rendimiento del modelo son dignas de atención. Las direcciones de investigación futuras se centrarán en la verificación de modelos y conjuntos de datos a mayor escala para ampliar aún más el alcance de la aplicación de T-FREE y promover el desarrollo continuo de la tecnología de modelos de lenguaje a gran escala. Se cree que T-FREE desempeñará un papel importante en más campos en el futuro próximo.