Jina AI ha lanzado Reader-LM, un modelo de lenguaje liviano diseñado específicamente para convertir HTML en Markdown limpio. Puede eliminar de manera eficiente contenido desordenado de páginas web, como anuncios y scripts, para generar archivos Markdown claramente estructurados sin expresiones regulares complejas ni operaciones manuales. Reader-LM está disponible en dos versiones: Reader-LM-0.5B y Reader-LM-1.5B, ambos optimizados para ejecutarse de manera eficiente incluso en entornos con recursos limitados y admitir contextos de hasta 256 000 tokens.
Jina AI ha lanzado dos pequeños modelos de lenguaje diseñados específicamente para convertir contenido HTML original en un formato Markdown limpio y ordenado, lo que nos permite deshacernos del tedioso procesamiento de datos de páginas web.
Lo más destacado de este modelo llamado Reader-LM es que puede convertir de forma rápida y eficiente contenido web en archivos Markdown.
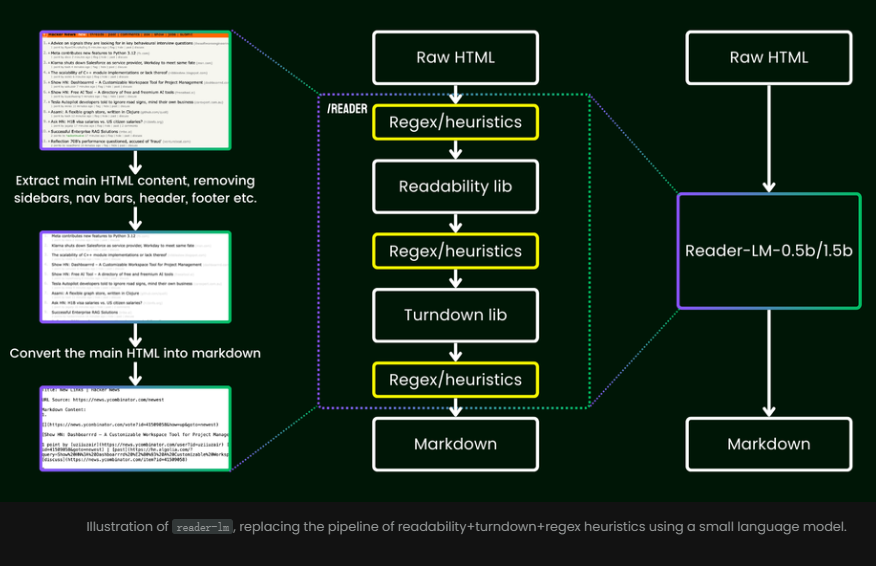
La ventaja de usarlo es que ya no necesita depender de reglas complejas o expresiones regulares laboriosas. Estos modelos eliminan de forma inteligente y automática el contenido desordenado de las páginas web, como anuncios, scripts y barras de navegación, y finalmente presentan un formato Markdown claro y organizado.
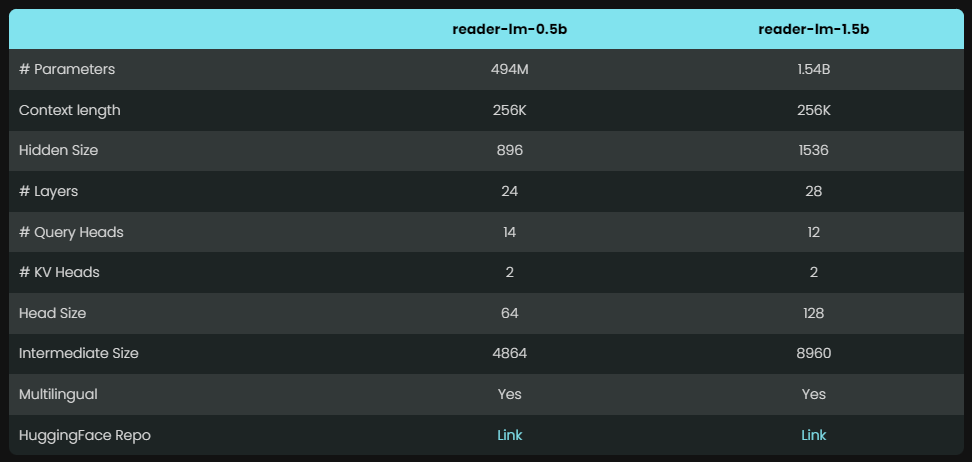
Reader-LM proporciona dos modelos con parámetros diferentes, a saber, Reader-LM-0.5B y Reader-LM-1.5B. Aunque la cantidad de parámetros de estos dos modelos no es enorme, están optimizados para la tarea de convertir HTML a Markdown. Los resultados son sorprendentes y su rendimiento supera a muchos modelos de lenguaje grandes.
Gracias a su diseño compacto, estos modelos pueden funcionar de manera eficiente en entornos con recursos limitados. Lo que es aún más digno de elogio es que Reader-LM no sólo admite varios idiomas, sino que también puede manejar datos de contexto de hasta 256 000 tokens, lo que permite manejar incluso archivos HTML complejos con facilidad.
A diferencia de los métodos tradicionales que se basan en expresiones regulares o configuraciones manuales, Reader-LM proporciona una solución de un extremo a otro que limpia automáticamente los datos HTML y extrae información clave.
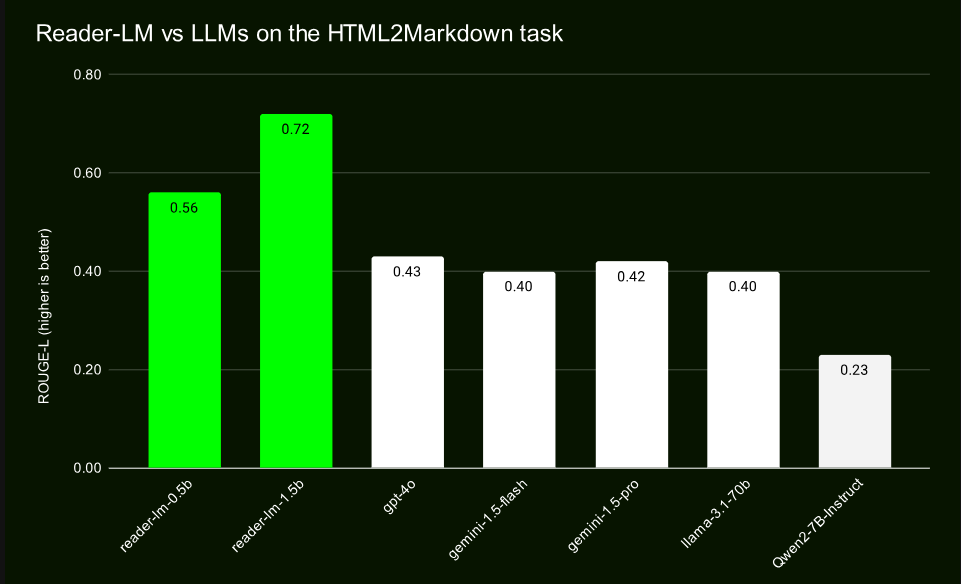
A través de pruebas comparativas con modelos a gran escala como GPT-4 y Gemini, Reader-LM ha demostrado un rendimiento excelente, especialmente en términos de preservación de estructura y uso de la sintaxis Markdown. Reader-LM-1.5B se desempeña particularmente bien en varios indicadores, con una puntuación ROUGE-L de 0,72, lo que demuestra su alta precisión en la generación de contenido, y su tasa de error también es significativamente menor que la de productos similares.
Debido al diseño compacto de Reader-LM, es más liviano en términos de uso de recursos de hardware, especialmente el modelo 0.5B, que puede funcionar sin problemas en entornos de baja configuración como Google Colab. A pesar de su pequeño tamaño, Reader-LM todavía tiene poderosas capacidades de procesamiento de contexto largo y puede procesar de manera eficiente contenido web grande y complejo sin afectar el rendimiento.
En términos de capacitación, Reader-LM adopta un proceso de varias etapas y se enfoca en extraer contenido Markdown de HTML original y ruidoso.
El proceso de capacitación incluye el emparejamiento de una gran cantidad de páginas web reales y datos sintéticos, asegurando la eficiencia y precisión del modelo. Después de una capacitación en dos etapas cuidadosamente diseñada, Reader-LM mejoró gradualmente su capacidad para procesar archivos HTML complejos y evitó efectivamente el problema de la generación repetida.
Introducción oficial: https://jina.ai/news/reader-lm-small-language-models-for-cleaning-and-converting-html-to-markdown/
Considerándolo todo, Reader-LM proporciona una solución eficiente, conveniente y precisa para la conversión de HTML a Markdown. Su diseño liviano facilita su ejecución en varios entornos, lo que lo convierte en una opción ideal para procesar datos de páginas web. Para obtener más información, visite el enlace de introducción oficial.