Kunlun Technology anunció recientemente que dos modelos de recompensa que desarrolló, Skywork-Reward-Gemma-2-27B y Skywork-Reward-Llama-3.1-8B, lograron excelentes resultados en RewardBench, con el modelo 27B encabezando la lista. Esto indica que Kunlun Wanwei ha logrado un gran avance en el campo de la inteligencia artificial, especialmente en la investigación y el desarrollo de modelos de recompensa, y proporciona nuevo soporte técnico para la capacitación de modelos de lenguaje a gran escala. Los modelos de recompensa son cruciales en el aprendizaje por refuerzo, ya que pueden guiar el aprendizaje de modelos y generar contenido que esté más acorde con las preferencias humanas. El modelo de Kunlun Wanwei tiene ventajas únicas en la selección de datos y el entrenamiento del modelo, lo que hace que funcione bien en aspectos como el diálogo y la seguridad, y muestra especialmente fuertes capacidades al procesar muestras difíciles.
Kunlun Wanwei Technology Co., Ltd. anunció recientemente que dos nuevos modelos de recompensa desarrollados por la empresa, Skywork-Reward-Gemma-2-27B y Skywork-Reward-Llama-3.1-8B, obtuvieron buenos resultados en RewardBench, el modelo de recompensa con autoridad internacional. Entre ellos, el modelo Skywork-Reward-Gemma-2-27B ganó el primer lugar y fue altamente reconocido por los funcionarios de RewardBench.
El modelo de recompensa ocupa una posición central en el aprendizaje por refuerzo, evalúa el desempeño del agente en diferentes estados y proporciona señales de recompensa para guiar el proceso de aprendizaje del agente, de modo que pueda tomar la decisión óptima en un entorno específico. En el entrenamiento de modelos de lenguaje grandes, el modelo de recompensa juega un papel particularmente crítico, ya que ayuda al modelo a comprender y generar contenido con mayor precisión que se ajuste a las preferencias humanas.
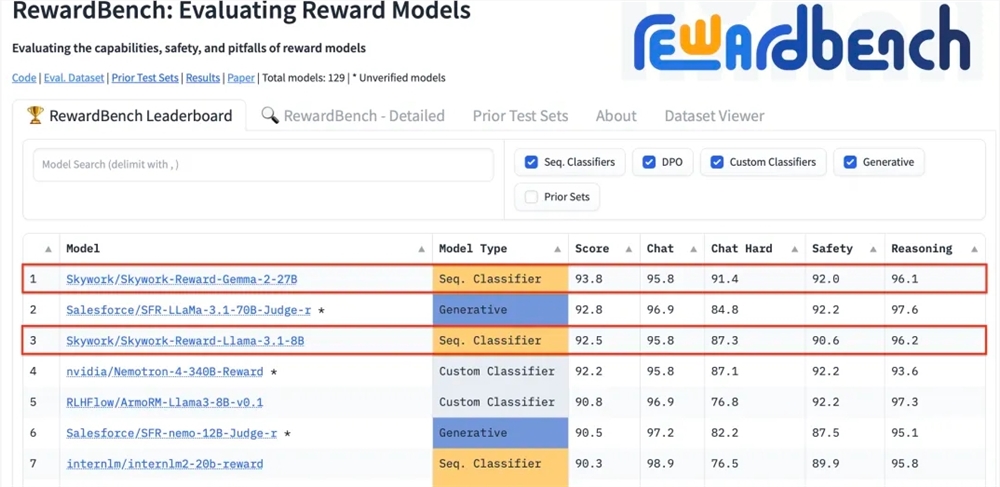
RewardBench es una lista de referencia que evalúa específicamente la efectividad de los modelos de recompensa en modelos de lenguaje grandes. Evalúa de manera integral los modelos a través de múltiples tareas, incluido el diálogo, el razonamiento y la seguridad. El conjunto de datos de prueba de esta lista consta de triples que consisten en palabras de aviso, respuestas seleccionadas y respuestas rechazadas. Se utiliza para probar si el modelo de recompensa puede clasificar correctamente las respuestas seleccionadas entre las respuestas rechazadas dadas las palabras de aviso antes de rechazar la respuesta. .
El modelo Skywork-Reward de Kunlun Wanwei se desarrolla a través de conjuntos de datos parcialmente ordenados cuidadosamente seleccionados y modelos base relativamente pequeños. En comparación con los modelos de recompensa existentes, sus datos parcialmente ordenados solo provienen de datos públicos en Internet y se filtran mediante filtros específicos para obtener altos niveles. -Conjuntos de datos de preferencia de calidad. Los datos cubren una amplia gama de temas, incluida la seguridad, las matemáticas y el código, y se verifican manualmente para garantizar la objetividad de los datos y la importancia de las brechas de recompensa.
Después de las pruebas, el modelo de recompensa de Kunlun Wanwei mostró un rendimiento excelente en campos como el diálogo y la seguridad, especialmente cuando se enfrenta a muestras difíciles, solo el modelo Skywork-Reward-Gemma-2-27B dio predicciones correctas. Este logro marca la fortaleza técnica y las capacidades de innovación de Kunlun Wanwei en el campo global de la IA, y también brinda nuevas posibilidades para el desarrollo y la aplicación de la tecnología de IA.
Dirección del modelo 27B:
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
Dirección del modelo 8B:
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
El excelente desempeño de Kunlun Wanwei en RewardBench demuestra su tecnología líder y sus capacidades de innovación en el campo de la inteligencia artificial. También proporciona nuevas direcciones y posibilidades para el desarrollo futuro de grandes modelos de lenguaje. Esperamos que traiga más avances en el futuro.