Nous Research lanza el revolucionario optimizador de entrenamiento de IA DisTrO, rompiendo la situación en la que el entrenamiento de grandes modelos de IA se limita a los grandes gigantes corporativos. DisTrO puede reducir significativamente la cantidad de transmisión de datos entre múltiples GPU y puede entrenar modelos de IA de manera eficiente incluso en entornos de red ordinarios. Esto reducirá en gran medida el umbral para el entrenamiento de modelos de IA y permitirá que más personas e instituciones participen en el desarrollo de la tecnología de IA. y desarrollo en curso. Se espera que esta tecnología innovadora cambie por completo el modelo de investigación y desarrollo en el campo de la IA y promueva la popularización y el desarrollo de la tecnología de IA.
Recientemente, el equipo de investigación de Nous Research trajo noticias interesantes al círculo tecnológico. Lanzaron un nuevo optimizador llamado DisTrO (Distributed Internet Training). El nacimiento de esta tecnología significa que los potentes modelos de IA no son sólo patentes de las grandes empresas, sino que la gente corriente también tiene la posibilidad de utilizar sus propios ordenadores para realizar un entrenamiento eficaz en casa.
La magia de DisTrO es que puede reducir significativamente la cantidad de información que debe transferirse entre múltiples unidades de procesamiento de gráficos (GPU) al entrenar un modelo de IA. A través de esta innovación, se pueden entrenar potentes modelos de IA en condiciones de red ordinarias e incluso permitir que personas o instituciones de todo el mundo unan fuerzas para desarrollar conjuntamente tecnología de IA.
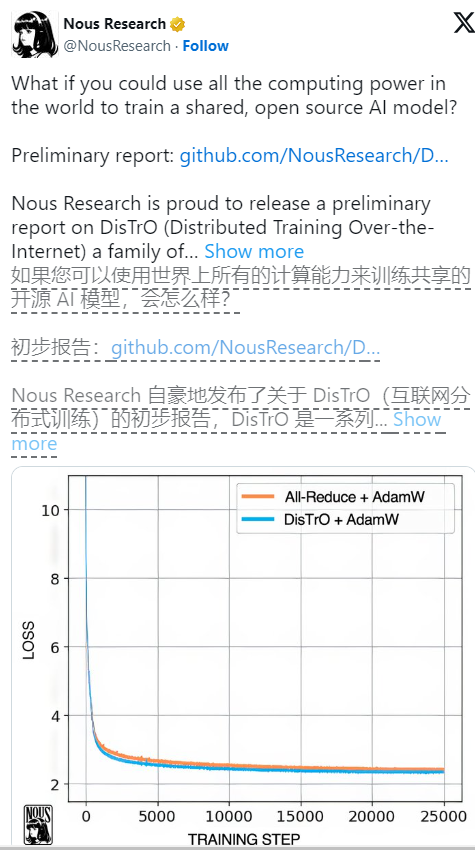
Según un artículo técnico de Nous Research, la mejora de la eficiencia de DisTrO es sorprendente. La eficiencia del entrenamiento que lo utiliza es 857 veces mayor que la del algoritmo común All-Reduce. Al mismo tiempo, la cantidad de información transmitida en cada entrenamiento. El paso también se reduce de 74,4 GB a 74,4 GB. Estas mejoras no sólo hacen que la formación sea más rápida y barata, sino que también significan que más personas tienen la oportunidad de participar en este campo.
Nous Research afirmó en su plataforma social que a través de DisTrO, investigadores e instituciones ya no necesitan depender de una determinada empresa para gestionar y controlar el proceso de formación, lo que les proporciona más libertad para innovar y experimentar. Este entorno competitivo abierto ayuda a promover el progreso tecnológico y, en última instancia, beneficia a toda la sociedad.
En el entrenamiento de IA, los requisitos de hardware suelen ser prohibitivos. En particular, las GPU de Nvidia de alto rendimiento se han vuelto cada vez más escasas y costosas en esta era, y sólo algunas empresas bien financiadas pueden afrontar la carga de dicha capacitación. Sin embargo, la filosofía de Nous Research es exactamente la contraria: apuestan por abrir al público la formación de modelos de IA a un coste menor y esforzarse por permitir la participación de más personas.
DisTrO funciona reduciendo la sobrecarga de comunicación entre cuatro y cinco órdenes de magnitud al reducir la necesidad de sincronización de gradiente completa entre GPU. Esta innovación permite entrenar modelos de IA en conexiones a Internet más lentas, siendo suficientes las velocidades de descarga de 100 Mbps y de carga de 10 Mbps fácilmente accesibles para muchos hogares.
En pruebas preliminares en el modelo de lenguaje grande Llama2 de Meta, DisTrO mostró resultados de entrenamiento comparables a los de los métodos tradicionales y, al mismo tiempo, redujo significativamente la cantidad de comunicación requerida. Los investigadores también dijeron que, aunque hasta ahora solo se han probado en modelos más pequeños, especulan tentativamente que a medida que aumenta el tamaño del modelo, la reducción en los requisitos de comunicación puede ser más significativa, llegando incluso de 1.000 a 3.000 veces.
Vale la pena señalar que, aunque DisTrO hace que el entrenamiento sea más flexible, todavía depende del soporte de GPU, pero ahora estas GPU no necesitan estar reunidas en el mismo lugar, sino que pueden distribuirse por todo el mundo y colaborar a través de Internet común. Vimos que DisTrO pudo igualar el método tradicional AdamW+All-Reduce en términos de velocidad de convergencia cuando se probó rigurosamente con 32 GPU H100, pero redujo significativamente los requisitos de comunicación.
DisTrO no solo es adecuado para modelos de lenguaje grandes, sino que también puede usarse para entrenar otros tipos de IA, como modelos de generación de imágenes. Las perspectivas de aplicación futuras son interesantes. Además, al mejorar la eficiencia de la capacitación, DisTrO también puede reducir el impacto ambiental de la capacitación en IA porque optimiza el uso de la infraestructura existente y reduce la necesidad de grandes centros de datos.
A través de DisTrO, Nous Research no sólo promueve avances tecnológicos en la formación de IA, sino que también promueve un ecosistema de investigación más abierto y flexible, que abre posibilidades ilimitadas para el futuro desarrollo de la IA.
Referencia: https://venturebeat.com/ai/this-could-change-everything-nous-research-unveils-new-tool-to-train-powerful-ai-models-with-10000x-efficiency/
El surgimiento de DisTrO presagia el proceso de democratización del entrenamiento en IA, reduce el umbral de participación, promueve el rápido desarrollo y la aplicación generalizada de la tecnología de IA y aporta nueva vitalidad y posibilidades ilimitadas al campo de la IA. En el futuro, esperamos que DisTrO traiga más sorpresas al desarrollo de la IA.