La investigación del equipo de Mamba ha logrado un gran avance. "Destilaron" con éxito el modelo Llama de gran tamaño en un modelo Mamba más eficiente. Esta investigación combina inteligentemente tecnologías como la destilación progresiva, el ajuste fino supervisado y la optimización de preferencias direccionales, y diseña un nuevo algoritmo de decodificación de inferencia basado en la estructura única del modelo Mamba, que mejora significativamente la velocidad de inferencia del modelo sin garantizar una mejora sustancial. en eficiencia se ha logrado sin pérdidas. Esta investigación no solo reduce el costo del entrenamiento de modelos a gran escala, sino que también proporciona nuevas ideas para la optimización futura de modelos, lo que tiene una importancia académica y un valor de aplicación importantes.
Recientemente, la investigación del equipo de Mamba es llamativa: investigadores de universidades como Cornell y Princeton han "destilado" con éxito Llama, un gran modelo de Transformer, en Mamba, y han diseñado un nuevo algoritmo de decodificación de inferencia que ha mejorado significativamente la velocidad de inferencia del modelo.
El objetivo de los investigadores es convertir a Llama en Mamba. ¿Por qué hacer esto? Porque entrenar un modelo grande desde cero es costoso y Mamba ha recibido una gran atención desde sus inicios, pero pocos equipos entrenan ellos mismos modelos de Mamba a gran escala. Aunque existen algunas variantes de buena reputación en el mercado, como Jamba de AI21 y Hybrid Mamba2 de NVIDIA, hay una gran cantidad de conocimientos integrados en los muchos modelos exitosos de Transformer. Si pudiéramos conservar este conocimiento y ajustar el Transformer a Mamba, el problema se resolvería.
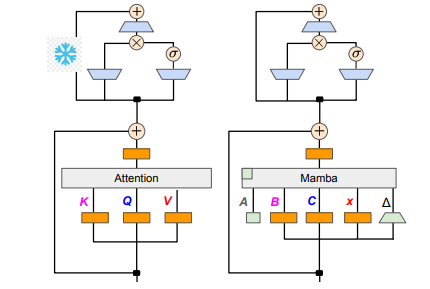
El equipo de investigación logró este objetivo combinando varios métodos, como la destilación progresiva, el ajuste fino supervisado y la optimización de preferencias direccionales. Vale la pena señalar que la velocidad también es crucial sin comprometer el rendimiento. Mamba tiene ventajas obvias en el razonamiento de secuencia larga, y Transformer también tiene soluciones de aceleración del razonamiento, como la decodificación especulativa. Dado que la estructura única de Mamba no puede aplicar directamente estas soluciones, los investigadores diseñaron especialmente un nuevo algoritmo y lo combinaron con características de hardware para implementar la decodificación especulativa basada en Mamba.
Finalmente, los investigadores convirtieron con éxito Zephyr-7B y Llama-38B en modelos RNN lineales y su rendimiento fue comparable al del modelo estándar antes de la destilación. Todo el proceso de capacitación solo utiliza 20 mil millones de tokens y los resultados son comparables al modelo Mamba7B entrenado desde cero con tokens de 1,2 T y al modelo NVIDIA Hybrid Mamba2 entrenado con tokens de 3,5 T.
En términos de detalles técnicos, el RNN lineal y la atención lineal están conectados, por lo que los investigadores pueden reutilizar directamente la matriz de proyección en el mecanismo de atención y completar la construcción del modelo mediante la inicialización de parámetros. Además, el equipo de investigación congeló los parámetros de la capa MLP en Transformer, reemplazó gradualmente el cabezal de atención con una capa RNN lineal (es decir, Mamba) y procesó la atención de consultas grupales para claves y valores compartidos entre los cabezales.
Durante el proceso de destilación se adopta una estrategia de sustitución gradual de las capas de atención. El ajuste fino supervisado incluye dos métodos principales: uno se basa en la divergencia KL a nivel de palabra y el otro es la destilación del conocimiento a nivel de secuencia. En la fase de ajuste de las preferencias del usuario, el equipo utilizó el método de Optimización Directa de Preferencias (DPO) para garantizar que el modelo pueda satisfacer mejor las expectativas del usuario al generar contenido comparándolo con el resultado del modelo del profesor.
A continuación, los investigadores comenzaron a aplicar la decodificación especulativa de Transformer al modelo Mamba. La decodificación especulativa puede entenderse simplemente como el uso de un modelo pequeño para generar múltiples resultados y luego el uso de un modelo grande para verificar estos resultados. Los modelos pequeños se ejecutan rápidamente y pueden generar rápidamente múltiples vectores de salida, mientras que los modelos grandes son responsables de evaluar la precisión de estos resultados, aumentando así la velocidad de inferencia general.
Para implementar este proceso, los investigadores diseñaron un conjunto de algoritmos que utilizan un modelo pequeño para generar K borradores de resultados cada vez, y luego el modelo grande devuelve el resultado final y el caché de los estados intermedios mediante verificación. Este método ha logrado buenos resultados en GPU Mamba2.8B logró 1,5 veces la aceleración de inferencia y la tasa de aceptación alcanzó el 60%. Aunque los efectos varían en las GPU de diferentes arquitecturas, el equipo de investigación optimizó aún más integrando núcleos y ajustando los métodos de implementación, y finalmente logró el efecto de aceleración ideal.
En la fase experimental, los investigadores utilizaron Zephyr-7B y Llama-3Instruct8B para realizar un entrenamiento de destilación en tres etapas. Al final, solo tomó de 3 a 4 días ejecutarlo en un 80G A100 de 8 tarjetas para reproducir con éxito los resultados de la investigación. Esta investigación no solo muestra la transformación entre Mamba y Llama, sino que también proporciona nuevas ideas para mejorar la velocidad de inferencia y el rendimiento de modelos futuros.
Dirección del artículo: https://arxiv.org/pdf/2408.15237
Esta investigación proporciona una valiosa experiencia y soluciones técnicas para mejorar la eficiencia de los modelos de lenguaje a gran escala. Se espera que los resultados se apliquen a más campos y promuevan un mayor desarrollo de la tecnología de inteligencia artificial. Proporcionar la dirección del artículo facilita que los lectores tengan una comprensión más profunda de los detalles de la investigación.