Los optimizadores de consultas de bases de datos dependen en gran medida de la estimación de cardinalidad (CE) para predecir el tamaño de los resultados de las consultas y así seleccionar el mejor plan de ejecución. Las estimaciones de cardinalidad inexactas pueden hacer que el rendimiento de las consultas se degrade. Los métodos CE existentes tienen limitaciones, especialmente cuando se trata de consultas complejas. Aunque el modelo de CE de aprendizaje es más preciso, su costo de capacitación es alto y carece de una evaluación comparativa sistemática.
En las bases de datos relacionales modernas, la estimación de cardinalidad (CE) juega un papel crucial. En pocas palabras, la estimación de cardinalidad es una predicción de cuántos resultados intermedios devolverá una consulta de base de datos. Esta predicción tiene un gran impacto en las opciones del plan de ejecución del optimizador de consultas, como decidir el orden de unión, si se utilizan índices y la elección del mejor método de unión. Si la estimación de cardinalidad es inexacta, el plan de ejecución puede verse gravemente comprometido, lo que resulta en velocidades de consulta extremadamente lentas y afecta seriamente el rendimiento general de la base de datos.
Sin embargo, los métodos de estimación de cardinalidad existentes tienen muchas limitaciones. La tecnología CE tradicional se basa en algunas suposiciones simplificadoras y, a menudo, predice con precisión la cardinalidad de consultas complejas, especialmente cuando están involucradas múltiples tablas y condiciones. Aunque el aprendizaje de modelos CE puede proporcionar una mayor precisión, su aplicación está limitada por tiempos de entrenamiento prolongados, la necesidad de grandes conjuntos de datos y la falta de una evaluación comparativa sistemática.
Para llenar este vacío, el equipo de investigación de Google lanzó CardBench, un nuevo marco de evaluación comparativa. CardBench incluye más de 20 bases de datos del mundo real y miles de consultas, superando con creces los puntos de referencia anteriores. Esto permite a los investigadores evaluar y comparar sistemáticamente diferentes modelos de CE de aprendizaje en diversas condiciones. El punto de referencia admite tres configuraciones principales: modelos basados en instancias, modelos de disparo cero y modelos ajustados, adecuados para diferentes necesidades de capacitación.
CardBench también está diseñado para incluir un conjunto de herramientas que pueden calcular las estadísticas necesarias, generar consultas SQL reales y crear gráficos de consultas anotadas para entrenar modelos CE.
El punto de referencia proporciona dos conjuntos de datos de entrenamiento: uno para una consulta de una sola tabla con múltiples predicados de filtro y otro para una consulta de unión binaria que involucra dos tablas. El punto de referencia incluye 9125 consultas de tabla única y 8454 consultas de combinación binaria en uno de los conjuntos de datos más pequeños, lo que garantiza un entorno sólido y desafiante para la evaluación de modelos. La capacitación de etiquetas de datos de Google BigQuery requirió 7 años de CPU de tiempo de ejecución de consultas, lo que destaca la importante inversión computacional en la creación de este punto de referencia. Al proporcionar estos conjuntos de datos y herramientas, CardBench reduce la barrera para que los investigadores desarrollen y prueben nuevos modelos de CE.
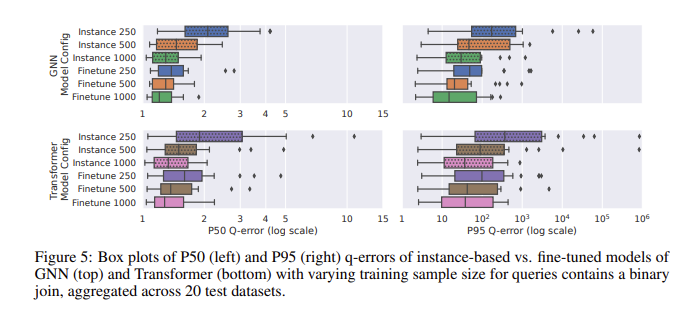
En la evaluación del rendimiento con CardBench, el modelo ajustado tuvo un rendimiento especialmente bueno. Si bien los modelos de disparo cero luchan por mejorar la precisión cuando se aplican a conjuntos de datos invisibles, especialmente en consultas complejas que involucran uniones, los modelos ajustados pueden lograr una precisión comparable a los métodos basados en instancias con muchos menos datos de entrenamiento. Por ejemplo, un modelo de red neuronal gráfica (GNN) ajustado logró un error q mediano de 1,32 y un error q del percentil 95 de 120 en consultas de unión binaria, significativamente mejor que el modelo de disparo cero. Los resultados muestran que incluso con 500 consultas, ajustar el modelo previamente entrenado puede mejorar significativamente su rendimiento. Esto los hace adecuados para aplicaciones prácticas donde los datos de entrenamiento pueden ser limitados.
La introducción de CardBench trae nuevas esperanzas al campo de la estimación de cardinalidad aprendida, permitiendo a los investigadores evaluar y mejorar modelos de manera más efectiva, impulsando así un mayor desarrollo en este importante campo.
Entrada en papel: https://arxiv.org/abs/2408.16170
En resumen, CardBench proporciona un marco de evaluación comparativa completo y poderoso, proporciona herramientas y recursos importantes para la investigación y el desarrollo de modelos de estimación de cardinalidad de aprendizaje y promueve el avance de la tecnología de optimización de consultas de bases de datos. El excelente rendimiento de su modelo perfeccionado es particularmente digno de atención, ya que ofrece nuevas posibilidades para escenarios de aplicación práctica.