Recientemente, un estudio publicado en la revista Cureus mostró que el modelo GPT-4 de OpenAI pasó con éxito el Examen Nacional Japonés de Fisioterapia sin formación adicional. Los investigadores probaron GPT-4 utilizando 1.000 preguntas que abarcaban memoria, comprensión, aplicación, análisis y evaluación. Los resultados mostraron que tenía una tasa de precisión del 73,4% y pasó las cinco partes de la prueba. Esta investigación plantea preocupaciones sobre el potencial de GPT-4 para aplicaciones médicas, al tiempo que revela sus limitaciones para abordar tipos específicos de problemas, como problemas prácticos y aquellos que contienen tablas con imágenes.
Un estudio reciente revisado por pares publicado en la revista Cureus muestra que el modelo de lenguaje GPT-4 de OpenAI aprobó con éxito el Examen Nacional de Fisioterapia de Japón sin ninguna capacitación adicional.
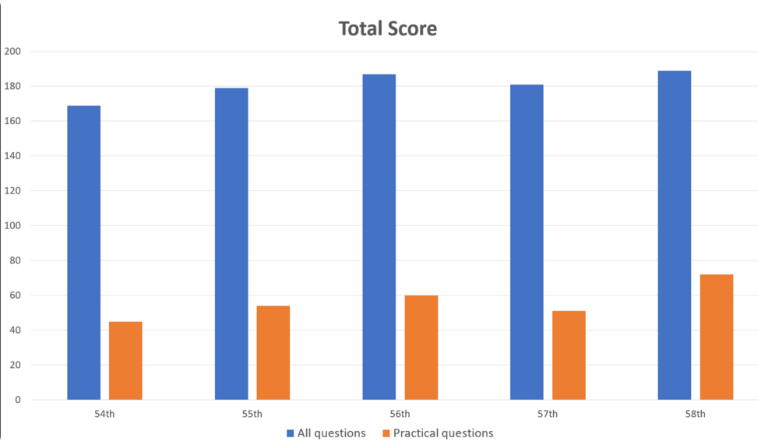
Los investigadores alimentaron 1.000 preguntas en GPT-4, cubriendo áreas como memoria, comprensión, aplicación, análisis y evaluación. Los resultados mostraron que GPT-4 respondió correctamente el 73,4% de las preguntas en general, pasando las cinco partes de la prueba. Sin embargo, las investigaciones también han revelado las limitaciones de la IA en algunas áreas.

GPT-4 funcionó bien en problemas generales, con una precisión del 80,1%, pero sólo del 46,6% en problemas prácticos. Del mismo modo, responde mucho mejor a las preguntas que contienen solo texto (80,5 % de aciertos) que las preguntas con imágenes y tablas (35,4 % de aciertos). Este hallazgo es consistente con investigaciones anteriores sobre las limitaciones de la comprensión visual de GPT-4.
Vale la pena señalar que la dificultad de las preguntas y la longitud del texto tienen poco impacto en el rendimiento de GPT-4. Aunque el modelo se entrenó principalmente utilizando datos en inglés, también funcionó bien al manejar datos en japonés.
Los investigadores señalaron que, si bien este estudio demuestra el potencial de GPT-4 en la rehabilitación clínica y la educación médica, debe considerarse con cautela. Destacaron que GPT-4 no responde correctamente a todas las preguntas y que serán necesarias futuras evaluaciones de nuevas versiones y de las capacidades del modelo en pruebas escritas y de razonamiento.
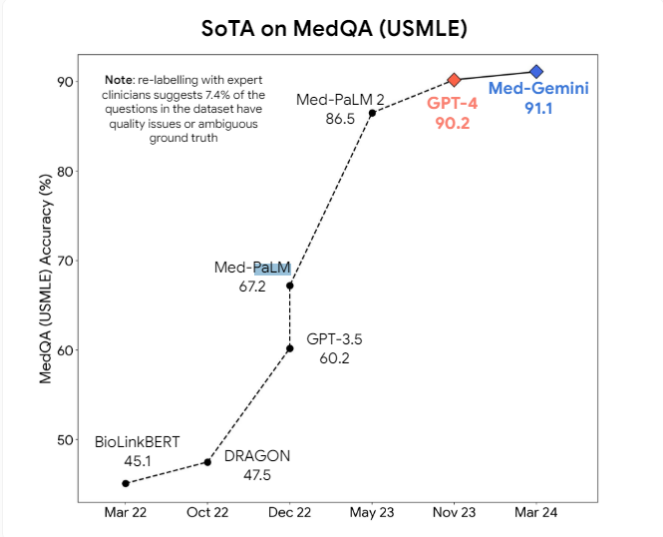
Además, los investigadores propusieron que los modelos multimodales como GPT-4v pueden aportar más mejoras en la comprensión visual. Actualmente, se están desarrollando activamente modelos médicos profesionales de IA, como Med-PaLM2 y Med-Gemini de Google, así como el modelo médico de Meta basado en Llama3, con el objetivo de superar los modelos de propósito general en tareas médicas.
Sin embargo, los expertos creen que puede pasar mucho tiempo antes de que los modelos médicos de IA se utilicen ampliamente en la práctica. El espacio de error de los modelos actuales sigue siendo demasiado grande en entornos médicos y se requieren avances significativos en las capacidades de inferencia para integrar de forma segura estos modelos en la práctica médica diaria.
Aunque este estudio demuestra el potencial de GPT-4 en el campo médico, también nos recuerda que la tecnología de IA aún necesita mejorarse continuamente antes de que realmente pueda aplicarse a escenarios médicos complejos. En el futuro, los modelos multimodales y capacidades de razonamiento más potentes serán mejoras clave para garantizar la seguridad y confiabilidad de la IA en la atención médica.