Recientemente, MLCommons publicó los resultados de la inferencia MLPerf v4.1. Participaron varios fabricantes de chips de inferencia de IA y la competencia fue feroz. Por primera vez, esta competencia incluye chips de AMD, Google, UntetherAI y otros fabricantes, así como los últimos chips Blackwell de Nvidia. Además de la comparación de rendimiento, la eficiencia energética también se ha convertido en una dimensión competitiva importante. Varios fabricantes han demostrado sus habilidades especiales y sus respectivas ventajas en diferentes pruebas comparativas, aportando nueva vitalidad al mercado de chips de inferencia de IA.
En el campo del entrenamiento de inteligencia artificial, las tarjetas gráficas de Nvidia casi no tienen rival, pero cuando se trata de inferencia de IA, los competidores parecen estar comenzando a ponerse al día, especialmente en términos de eficiencia energética. A pesar del buen desempeño de los últimos chips Blackwell de Nvidia, no está claro si podrá mantener su liderazgo. Hoy, ML Commons anunció los resultados del último concurso de inferencia de IA: MLPerf Inference v4.1. Por primera vez participan el acelerador Instinct de AMD, el acelerador Trillium de Google, los chips de la startup canadiense UntetherAI y los chips Blackwell de Nvidia. Otras dos empresas, Cerebras y FuriosaAI, han lanzado nuevos chips de inferencia pero no han presentado MLPerf para su prueba.
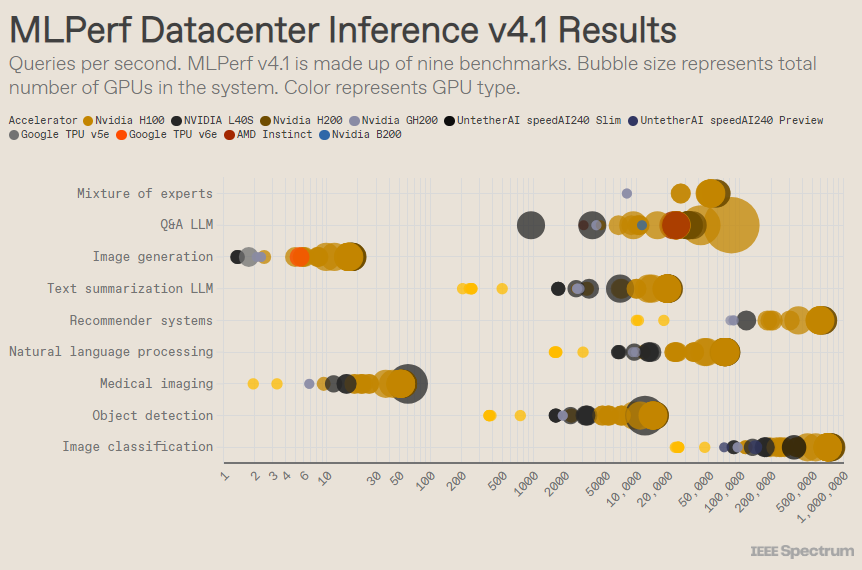
MLPerf está estructurado como una competición olímpica, con múltiples eventos y subeventos. La categoría "Recinto del centro de datos" tuvo la mayor cantidad de entradas. A diferencia de la categoría abierta, la categoría cerrada requiere que los participantes realicen inferencias directamente en un modelo determinado sin modificar significativamente el software. La categoría de centro de datos prueba principalmente la capacidad de procesar solicitudes por lotes, mientras que la categoría de borde se centra en reducir la latencia.
Hay 9 puntos de referencia diferentes en cada categoría, que cubren una variedad de tareas de IA, incluida la generación de imágenes populares (piense en Midjourney) y la respuesta a preguntas con modelos de lenguaje grandes (como ChatGPT), así como algunas tareas importantes pero menos conocidas, como Clasificación de imágenes, detección de objetos y motores de recomendación.
Esta ronda añade un nuevo punto de referencia: el "modelo híbrido experto". Este es un método cada vez más popular de implementación de modelos de lenguaje que divide un modelo de lenguaje en múltiples modelos pequeños independientes, cada uno de ellos ajustado para una tarea específica, como una conversación diaria, resolución de problemas matemáticos o asistencia en programación. Al asignar cada consulta a su modelo pequeño correspondiente, se reduce la utilización de recursos, lo que reduce los costos y aumenta el rendimiento, afirmó Miroslav Hodak, miembro senior del personal técnico de AMD.

En el popular benchmark "centro de datos cerrado", los ganadores siguen siendo los envíos basados en la GPU Nvidia H200 y el superchip GH200, que combinan GPU y CPU en un solo paquete. Sin embargo, una mirada más cercana a los resultados revela algunos detalles interesantes. Algunos competidores utilizaron varios aceleradores, mientras que otros utilizaron solo uno. Los resultados son aún más confusos si normalizamos las consultas por segundo según la cantidad de aceleradores y conservamos los envíos con mejor rendimiento para cada tipo de acelerador. Cabe señalar que este enfoque ignora la función de la CPU y la interconexión.
Por acelerador, Blackwell de Nvidia se destacó en tareas de preguntas y respuestas de modelos de lenguaje grandes, ofreciendo una aceleración de 2,5 veces con respecto a las iteraciones de chips anteriores, el único punto de referencia al que se sometió. El chip de vista previa speedAI240 de Untether AI funcionó casi tan bien como el H200 en la única tarea de reconocimiento de imágenes a la que se le envió. Trillium de Google tiene un rendimiento ligeramente inferior a H100 y H200 en tareas de generación de imágenes, mientras que Instinct de AMD tiene un rendimiento equivalente a H100 en tareas de preguntas y respuestas de modelos de lenguaje grandes.
Parte del éxito de Blackwell se debe a su capacidad para ejecutar grandes modelos de lenguaje utilizando precisión de punto flotante de 4 bits. Nvidia y sus competidores han estado trabajando para reducir la cantidad de bits representados en modelos de transformación como ChatGPT para acelerar los cálculos. Nvidia introdujo matemáticas de 8 bits en el H100 y esta presentación es la primera demostración de matemáticas de 4 bits en el punto de referencia MLPerf.
El mayor desafío al trabajar con números de tan baja precisión es mantener la precisión, dijo Dave Salvator, director de marketing de productos de Nvidia. Para mantener una alta precisión en los envíos de MLPerf, el equipo de Nvidia ha realizado numerosas innovaciones en el software.
Además, el ancho de banda de la memoria del Blackwell casi se duplica a 8 terabytes por segundo, en comparación con los 4,8 terabytes del H200.
La presentación Blackwell de Nvidia utiliza un solo chip, pero Salvator dice que está diseñado para redes y escalabilidad, y funcionará mejor cuando se combine con la interconexión NVLink de Nvidia. Las GPU Blackwell admiten hasta 18 conexiones NVLink de 100 GB por segundo, con un ancho de banda total de 1,8 terabytes por segundo, casi el doble del ancho de banda de interconexión del H100.
Salvator cree que a medida que los modelos de lenguajes grandes sigan escalando, incluso la inferencia requerirá plataformas de múltiples GPU para satisfacer la demanda, y Blackwell está diseñado para esta situación. "Havel es una plataforma", dijo Salvator.
Nvidia envió su sistema de chip Blackwell a la subcategoría Vista previa, lo que significa que aún no está disponible, pero se espera que esté disponible antes del próximo lanzamiento de MLPerf, que será dentro de seis meses.
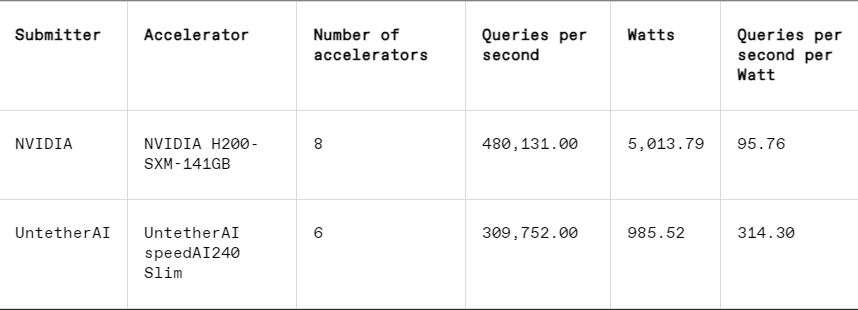
En cada punto de referencia, MLPerf también incluye una sección de medición de energía que prueba sistemáticamente el consumo de energía real de cada sistema mientras realiza las tareas. La competencia principal de esta ronda (Categoría de energía cerrada para centros de datos) tuvo solo dos participantes, Nvidia y Untether AI. Si bien Nvidia participó en todos los puntos de referencia, Untether solo presentó resultados en la tarea de reconocimiento de imágenes.
Untether AI sobresale en este sentido, logrando con éxito una excelente eficiencia energética. Su chip utiliza un enfoque llamado "computación en memoria". El chip de Untether AI está formado por un banco de celdas de memoria con un pequeño procesador cerca. Cada procesador funciona en paralelo, procesando datos simultáneamente con unidades de memoria adyacentes, lo que reduce significativamente el tiempo y la energía gastados en transferir datos del modelo entre la memoria y los núcleos informáticos.
"Descubrimos que cuando se ejecutan cargas de trabajo de IA, el 90% del consumo de energía se debe a mover datos de la DRAM a las unidades de procesamiento de caché", afirmó Robert Beachler, vicepresidente de producto de Untether AI. "Entonces, lo que hace Untether es acercar el cálculo a los datos, en lugar de mover los datos a la unidad de cálculo".
Este enfoque funciona particularmente bien en otra subcategoría de MLPerf: el cierre de bordes. Esta categoría se centra en casos de uso más prácticos, como la inspección de máquinas en fábricas, robots de visión guiada y vehículos autónomos, aplicaciones que tienen requisitos estrictos de eficiencia energética y procesamiento rápido, explicó Beachler.
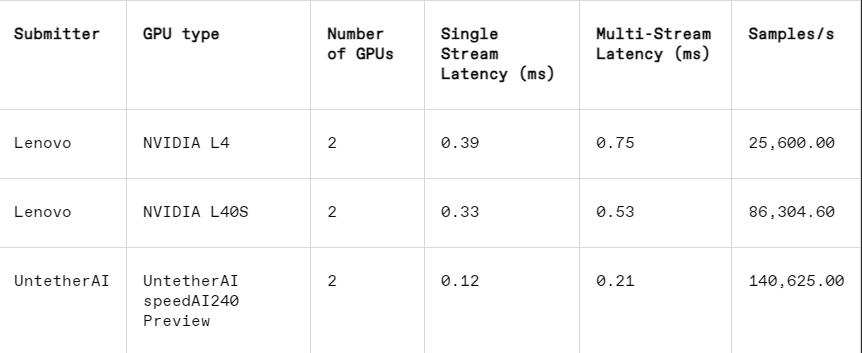
En la tarea de reconocimiento de imágenes, el rendimiento de latencia del chip de vista previa speedAI240 de Untether AI es 2,8 veces más rápido que el del L40S de Nvidia, y el rendimiento (número de muestras por segundo) también aumenta 1,6 veces. La startup también presentó resultados de consumo de energía en esta categoría, pero los competidores de Nvidia no, lo que dificulta las comparaciones directas. Sin embargo, el chip de vista previa speedAI240 de Untether AI tiene un consumo de energía nominal de 150 vatios, mientras que el L40S de Nvidia tiene 350 vatios, lo que muestra una ventaja de 2,3 veces en el consumo de energía y un mejor rendimiento de latencia.
Aunque Cerebras y Furiosa no participaron en MLPerf, también lanzaron nuevos chips respectivamente. Cerebras presentó su servicio de inferencia en la conferencia IEEE Hot Chips en la Universidad de Stanford. Cerebras, con sede en Sunny Valley, California, fabrica chips gigantes que son tan grandes como lo permiten las obleas de silicio, evitando así interconexiones entre chips y aumentando considerablemente el ancho de banda de memoria del dispositivo. Se utilizan principalmente para entrenar redes neuronales gigantes. Ahora han actualizado su última computadora, CS3, para admitir la inferencia.
Aunque Cerebras no presentó un MLPerf, la compañía afirma que su plataforma supera al H100 en 7 veces y al chip Groq de la competencia en 2 veces en la cantidad de tokens LLM generados por segundo. "Hoy estamos en la era del acceso telefónico a la IA generativa", dijo Andrew Feldman, director ejecutivo y cofundador de Cerebras. "Todo esto se debe a que hay un cuello de botella en el ancho de banda de la memoria. Ya sea el H100 de Nvidia o el MI300 o TPU de AMD, todos usan la misma memoria externa, lo que resulta en las mismas limitaciones. Rompemos esa barrera porque lo hacemos en el diseño de nivel de oblea. "
En la conferencia Hot Chips, Furiosa de Seúl también demostró su chip RNGD de segunda generación (que se pronuncia "rebelde"). El nuevo chip de Furiosa presenta su arquitectura Tensor Contraction Processor (TCP). En las cargas de trabajo de IA, la función matemática básica es la multiplicación de matrices, a menudo implementada en hardware como una primitiva. Sin embargo, el tamaño y la forma de la matriz, es decir, el tensor más ancho, pueden variar significativamente. RNGD implementa esta multiplicación de tensores más general como una primitiva. "Durante la inferencia, los tamaños de los lotes varían mucho, por lo que es fundamental aprovechar al máximo el paralelismo inherente y la reutilización de datos de una forma de tensor determinada", dijo June Paik, fundadora y directora ejecutiva de Furiosa, en Hot Chips.
Aunque Furiosa no tiene MLPerf, compararon el chip RNGD con el punto de referencia resumido LLM de MLPerf en pruebas internas, y los resultados fueron comparables al chip L40S de Nvidia, pero solo consumieron 185 vatios en comparación con los 320 vatios del L40S. Paik dijo que el rendimiento mejorará con mayores optimizaciones del software.
IBM también anunció el lanzamiento de su nuevo chip Spyre, que está diseñado para que las empresas generen cargas de trabajo de IA y se espera que esté disponible en el primer trimestre de 2025.
Claramente, el mercado de chips de inferencia de IA estará muy activo en el futuro previsible.
Referencia: https://spectrum.ieee.org/new-inference-chips
Con todo, los resultados de MLPerf v4.1 muestran que la competencia en el mercado de chips de inferencia de IA es cada vez más feroz. Aunque Nvidia todavía mantiene el liderazgo, no se puede ignorar el ascenso de fabricantes como AMD, Google y Untether AI. En el futuro, la eficiencia energética se convertirá en un factor competitivo clave y las nuevas tecnologías, como la computación en memoria, también desempeñarán un papel importante. Las innovaciones tecnológicas de varios fabricantes seguirán promoviendo la mejora de las capacidades de razonamiento de la IA y dando un fuerte impulso a la popularización y el desarrollo de aplicaciones de IA.