En los últimos años, el rendimiento de los modelos de idiomas grandes (LLM) ha atraído mucha atención. Este artículo presenta una investigación emocionante. Esta investigación desafía el concepto de "modelos más grandes y mejores" tradicionales, proporciona nuevas ideas y direcciones para el desarrollo futuro de LLM, y también proporciona más posibilidades para investigadores y desarrolladores con recursos limitados. Revela el enorme potencial de las estrategias de búsqueda para mejorar las capacidades de razonamiento del modelo y desencadenar en el pensamiento profundo de la relación entre la computación de los recursos y los parámetros del modelo.
Recientemente, un nuevo estudio ha sido emocionante y demuestra que los modelos de idiomas grandes (LLM) pueden mejorar significativamente el rendimiento a través de la función de búsqueda. En particular, el modelo LLAMA3.1 con un volumen de parámetros de solo 800 millones pasó a través de 100 búsquedas, y no fue comparable al GPT-4O en el código Python.
Esta idea parece recordarle a la gente al pionero del aprendizaje, la publicación clásica de blog de Rich Sutton "The Bitter Less" en 2019. Mencionó que con la mejora del poder informático, necesitamos reconocer el poder de los métodos generales. En particular, los dos métodos de "búsqueda" y "aprendizaje" parecen ser una excelente opción que puede continuar expandiéndose.
Aunque Sutton enfatiza la importancia del aprendizaje, es decir, los modelos más grandes generalmente pueden aprender más conocimiento, pero a menudo ignoramos el potencial de la búsqueda en el proceso de razonamiento. Recientemente, los investigadores de Stanford, Oxford y DeepMind descubrieron que aumentar el número de tiempos de muestreo repetidos durante la etapa de razonamiento puede mejorar significativamente el rendimiento de los modelos en los campos de las matemáticas, el razonamiento y la generación de códigos.
Después de inspirarse en estos estudios, los dos ingenieros decidieron realizar experimentos. Descubrieron que usar 100 modelos de LLAMA para búsqueda puede superar e incluso unir GPT-4O en las tareas de programación de Python. Utilizan metáforas vívidas para describir: "En el pasado, una Malasia de Malasia podría alcanzar alguna habilidad. Ahora, solo 100 patitos pueden completar lo mismo".
Para lograr un mayor rendimiento, utilizaron la biblioteca VLLM para realizar un razonamiento por lotes y se ejecutaron en 10 GPU A100-40GB. El autor eligió la prueba de referencia de Humaneval porque puede ejecutar el código generado ejecutando la evaluación de la prueba, que es más objetiva y precisa.
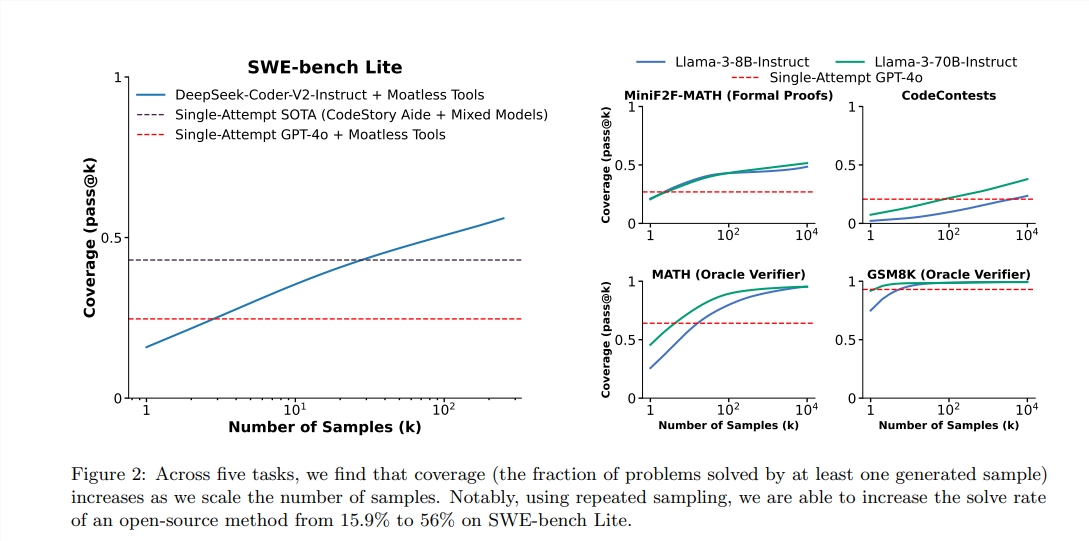
Según el informe, el puntaje PASS@1 de GPT-4O es del 90.2%en el razonamiento de la muestra cero. A través de los métodos anteriores, el puntaje Pass@K de Llama3.18b también ha mejorado significativamente. Cuando el número de muestreo repetido es de 100, la puntuación de LLAMA alcanzó el 90.5%;
Vale la pena mencionar que, aunque este experimento no es una reproducción estricta de la investigación original, enfatiza que cuando el método de búsqueda mejora la etapa de razonamiento, el modelo más pequeño también puede superar la posibilidad de grandes modelos dentro del rango previsible.
La búsqueda es fuerte porque puede expandirse "transparentemente" con el aumento en el cálculo y transferir los recursos de la memoria al cálculo, logrando así el equilibrio de recursos. Recientemente, DeepMind ha hecho importantes progresos en el campo de las matemáticas, lo que demuestra el poder de la búsqueda.
Sin embargo, el éxito de la búsqueda primero necesita realizar una evaluación de alta calidad de los resultados. El modelo DeepMind ha logrado una supervisión efectiva al convertir los problemas matemáticos en el lenguaje natural para formar una expresión formal. En otras áreas, las tareas de PNL abiertas, como el "correo electrónico resumido", son mucho más difíciles de realizar una búsqueda efectiva.
Este estudio muestra que la mejora del rendimiento de los modelos generadores en campos específicos está relacionado con su evaluación y capacidades de búsqueda, y las investigaciones futuras pueden explorar cómo mejorar estas capacidades a través de un entorno digital repetido.
Dirección de tesis: https: //arxiv.org/pdf/2407.21787
En general, esta investigación proporciona una nueva perspectiva para la mejora del rendimiento de los modelos de idiomas grandes. En el futuro, cómo combinar de manera efectiva las estrategias de aprendizaje y búsqueda será una dirección importante para el desarrollo de LLM. También se ha proporcionado el vinculado vinculado de este estudio, y los lectores interesados pueden comprenderlo.