El auge de la arquitectura Transformer ha revolucionado el campo del procesamiento del lenguaje natural, pero su elevado coste computacional se ha convertido en un cuello de botella a la hora de procesar textos largos. En respuesta a este problema, este artículo presenta un nuevo método llamado Tree Attention, que reduce efectivamente la complejidad computacional de autoatención del modelo Transformer de contexto largo a través de la reducción de árbol y aprovecha al máximo el poder de los clústeres de GPU modernos. mejora enormemente la eficiencia informática.
En esta era de explosión de información, la inteligencia artificial es como estrellas brillantes que iluminan el cielo nocturno de la sabiduría humana. Entre estas estrellas, la arquitectura Transformer es sin duda la más deslumbrante. Con el mecanismo de autoatención como núcleo, lidera una nueva era en el procesamiento del lenguaje natural. Sin embargo, incluso las estrellas más brillantes tienen rincones de difícil acceso. Para los modelos Transformer de contexto largo, el alto consumo de recursos del cálculo de autoatención se convierte en un problema. Imagine que está intentando que la IA comprenda un artículo que tiene decenas de miles de palabras. Cada palabra debe compararse con todas las demás palabras del artículo. La cantidad de cálculo es, sin duda, enorme.
Para solucionar este problema, un grupo de científicos de Zyphra y EleutherAI propusieron un nuevo método llamado Tree Attention.
La atención propia, como núcleo del modelo Transformer, su complejidad computacional aumenta cuadráticamente a medida que aumenta la longitud de la secuencia. Esto se convierte en un obstáculo insuperable cuando se trata de textos largos, especialmente para modelos de lenguajes grandes (LLM).
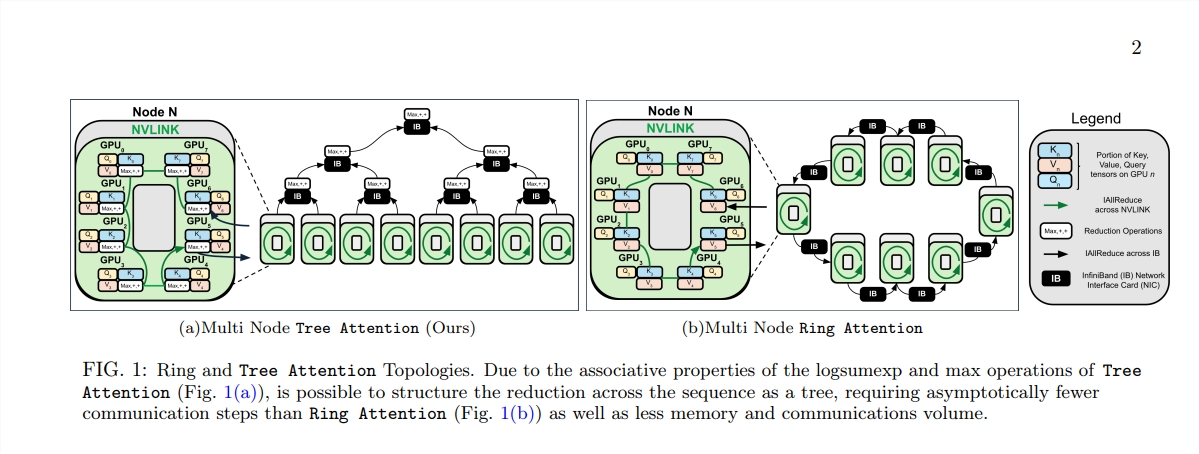
El nacimiento de Tree Attention es como plantar árboles que puedan realizar cálculos eficientes en este bosque computacional. Descompone el cálculo de la autoatención en múltiples tareas paralelas mediante la reducción del árbol. Cada tarea es como una hoja en un árbol, que juntas forman un árbol completo.
Lo que es aún más sorprendente es que los proponentes de Tree Attention también derivaron la función energética de la autoatención, que no solo proporciona una explicación bayesiana para la autoatención, sino que también la conecta estrechamente con modelos energéticos como la red de Hopfield.
Tree Attention también tiene en cuenta especialmente la topología de red de los clústeres de GPU modernos y reduce los requisitos de comunicación entre nodos mediante el uso inteligente de conexiones de gran ancho de banda dentro del clúster, mejorando así la eficiencia informática.
A través de una serie de experimentos, los científicos verificaron el rendimiento de Tree Attention en diferentes longitudes de secuencia y número de GPU. Los resultados muestran que Tree Attention es hasta 8 veces más rápido que los métodos Ring Attention existentes al decodificar en múltiples GPU, al tiempo que reduce significativamente el volumen de comunicación y el uso máximo de memoria.
La propuesta de Tree Attention no solo proporciona una solución eficiente para el cálculo de modelos de atención de contexto largo, sino que también nos brinda una nueva perspectiva para comprender el mecanismo interno del modelo Transformer. A medida que la tecnología de IA continúa avanzando, tenemos motivos para creer que Tree Attention desempeñará un papel importante en futuras investigaciones y aplicaciones de IA.
Dirección del artículo: https://mp.weixin.qq.com/s/U9FaE6d-HJGsUs7u9EKKuQ
La aparición de Tree Attention proporciona una solución eficiente e innovadora para resolver el cuello de botella computacional del procesamiento de textos largos. Tiene una importancia de gran alcance para la comprensión y el desarrollo futuro del modelo Transformer. Este método no solo logra mejoras significativas en el rendimiento, sino que, lo que es más importante, proporciona nuevas ideas y direcciones para investigaciones posteriores, que merecen un estudio y discusión en profundidad.