El equipo de UCSC-VLAA publicó el enorme conjunto de datos médicos multimodal MedTrinity-25M, que contiene 25 millones de imágenes médicas y anotaciones detalladas, lo que marca un gran salto en los recursos de datos en el campo médico. La anotación multigranular de este conjunto de datos permite a los investigadores comprender y aplicar datos médicos más profundamente y proporciona una base sólida para entrenar grandes modelos médicos multimodales avanzados. El proceso de construcción de MedTrinity-25M incorpora una variedad de tecnologías, incluido el procesamiento sofisticado de datos, la integración de metadatos, la generación de descripciones asistidas por modelos de lenguaje a gran escala (MLLM), etc., lo que mejora significativamente la usabilidad y el valor de investigación de los datos.
Se lanza oficialmente el conjunto de datos multimodales a gran escala "MedTrinity-25M" del equipo UCSC-VLAA. Este conjunto de datos contiene 25 millones de imágenes médicas y anotaciones detalladas. Puede describirse como una innovación importante en el campo médico. Tiene anotaciones multigranulares que pueden ayudar a los investigadores a comprender y aplicar mejor los datos médicos y usarse para entrenar grandes modelos médicos multimodales.
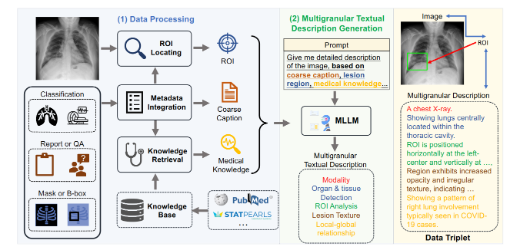
El proceso de construcción de MedTrinity-25M es bastante complicado. Después de un cuidadoso procesamiento de datos, el equipo extrajo información clave obtenida de varios tipos de datos, integró metadatos, generó títulos aproximados, localizó áreas de interés y recopiló conocimientos médicos. Lo que es más interesante es que utilizaron esta información para generar descripciones detalladas utilizando modelos de lenguaje a gran escala (MLLM). Este enfoque no sólo mejora la disponibilidad de datos sino que también abre nuevas direcciones para la investigación médica.
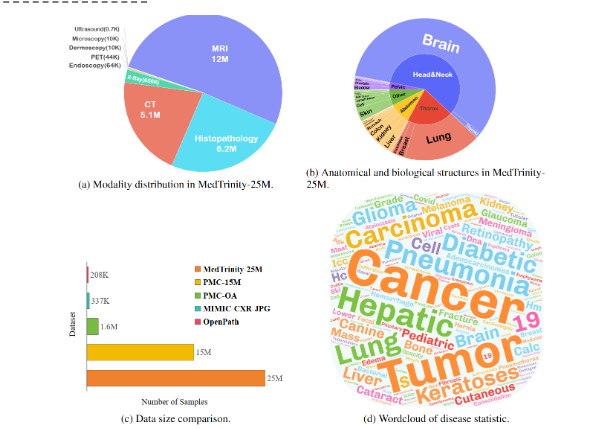
Hablando del proceso de publicación, vale la pena mencionar que el conjunto de datos de demostración de MedTrinity-25M estuvo en línea ya en junio de 2024, mientras que el conjunto de datos completo se publicó oficialmente el 21 de julio y, más recientemente, el 7 de agosto. papeles relacionados.
Además del conjunto de datos en sí, el equipo también proporciona una serie de modelos previamente entrenados, como LLaVA-Med++, que funcionan bien en múltiples tareas médicas. Los investigadores pueden utilizar estas herramientas para completar mejor sus proyectos, mejorando enormemente la eficiencia de la investigación médica.
MedTrinity-25M proporciona un recurso valioso para la comunidad médica. Espero que todos puedan aprovechar al máximo este conjunto de datos para promover el desarrollo de la investigación médica.
Entrada al proyecto: https://top.aibase.com/tool/medtrinity-25m
La publicación del conjunto de datos MedTrinity-25M y sus modelos de apoyo proporciona un poderoso impulso para la investigación en inteligencia artificial médica. Esperamos que este conjunto de datos promueva avances en el análisis de imágenes médicas, el diagnóstico de enfermedades y otros campos y, en última instancia, beneficie a más pacientes. Los investigadores pueden visitar el portal del proyecto para obtener más información y utilizar este valioso recurso.