Andrej Karpathy, una autoridad en el campo de la IA, cuestionó recientemente el aprendizaje por refuerzo basado en la retroalimentación humana (RLHF), creyendo que no es la única forma de lograr una verdadera IA a nivel humano, lo que ha provocado una preocupación generalizada y acalorados debates en la industria. . Él cree que RLHF es más una medida provisional que una solución definitiva, y tomó AlphaGo como ejemplo para comparar las diferencias en la resolución de problemas entre el aprendizaje por refuerzo real y RLHF. Sin duda, las opiniones de Karpathy brindan una nueva perspectiva sobre las direcciones actuales de la investigación en IA y también plantean nuevos desafíos para el desarrollo futuro de la IA.
Recientemente, Andrej Karpathy, un conocido investigador en la industria de la inteligencia artificial, presentó un punto de vista controvertido. Cree que el aprendizaje por refuerzo basado en la tecnología de retroalimentación humana (RLHF), actualmente ampliamente elogiado, puede no ser la única forma de lograrlo. verdaderas capacidades de resolución de problemas a nivel humano. Sin duda, esta declaración arrojó una pesada bomba en el campo actual de la investigación de la IA.
RLHF alguna vez fue considerado un factor clave en el éxito de los modelos de lenguaje a gran escala (LLM) como ChatGPT, y fue aclamado como el arma secreta que brinda a la IA capacidades de comprensión, obediencia y interacción natural. En el proceso tradicional de entrenamiento de IA, RLHF se usa generalmente como el último enlace después del entrenamiento previo y el ajuste fino supervisado (SFT). Sin embargo, Karpathy comparó el RLHF con un cuello de botella y una medida provisional, creyendo que está lejos de ser la solución definitiva para la evolución de la IA.
Karpathy comparó inteligentemente RLHF con AlphaGo de DeepMind. AlphaGo utilizó lo que él llama verdadera tecnología RL (aprendizaje por refuerzo) y, al jugar constantemente contra sí mismo y maximizar su tasa de victorias, finalmente superó a los mejores jugadores de ajedrez humanos sin intervención humana. Este enfoque logra niveles de rendimiento sobrehumanos al optimizar las redes neuronales para aprender directamente de los resultados del juego.
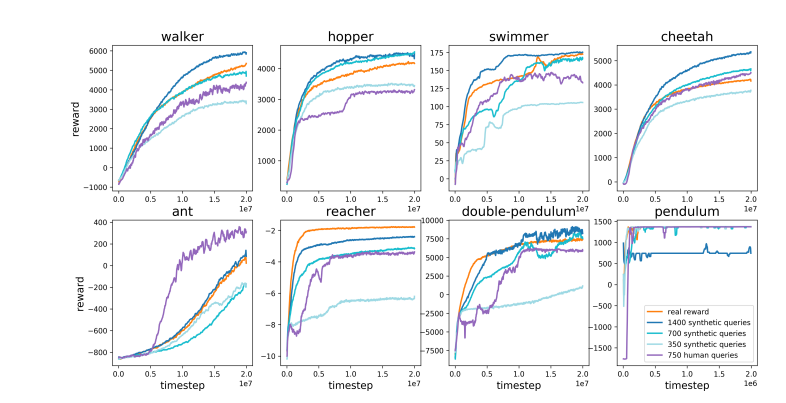
Por el contrario, Karpathy cree que RLHF se trata más de imitar las preferencias humanas que de resolver problemas. Imaginó que si AlphaGo adopta el método RLHF, los evaluadores humanos necesitarán comparar una gran cantidad de estados del juego y elegir preferencias. Este proceso puede requerir hasta 100.000 comparaciones para entrenar un modelo de recompensa que imite la verificación de la atmósfera humana. Sin embargo, tales juicios basados en la atmósfera pueden producir resultados engañosos en un juego riguroso como el Go.
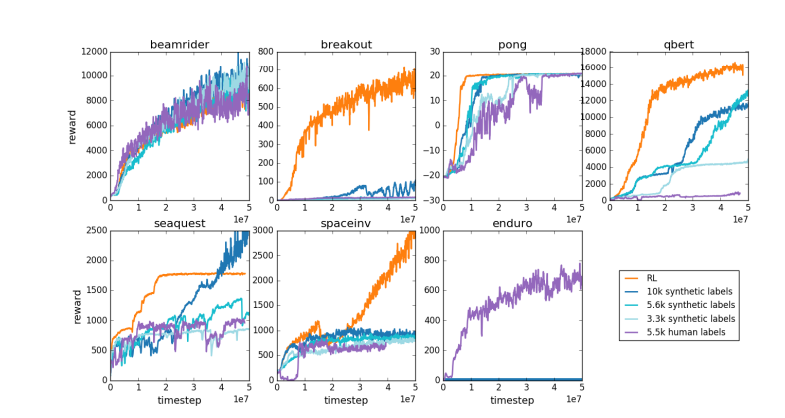
Por la misma razón, el modelo de recompensa LLM actual funciona de manera similar: tiende a clasificar respuestas altas que los evaluadores humanos estadísticamente parecen preferir. Se trata más de un agente que atiende a preferencias humanas superficiales que de un reflejo de una verdadera capacidad de resolución de problemas. Lo que es aún más preocupante es que los modelos pueden aprender rápidamente a explotar esta función de recompensa en lugar de mejorar sus capacidades.
Karpathy señala que, si bien el aprendizaje por refuerzo funciona bien en entornos cerrados como Go, el verdadero aprendizaje por refuerzo sigue siendo difícil de alcanzar para tareas de lenguaje abierto. Esto se debe principalmente a que es difícil definir objetivos claros y mecanismos de recompensa en las tareas abiertas. ¿Cómo otorgar recompensas objetivas por tareas como resumir un artículo, responder una pregunta vaga sobre la instalación de pip, contar un chiste o reescribir código Java en Python? Karpathy plantea esta pregunta reveladora, e ir en esta dirección no es un principio. ¿Es imposible? pero tampoco es fácil y requiere algo de pensamiento creativo.

Aun así, Karpathy cree que si se puede resolver este difícil problema, los modelos de lenguaje tienen el potencial de igualar o incluso superar las capacidades humanas de resolución de problemas. Esta visión coincide con un artículo reciente publicado por Google DeepMind, que señalaba que la apertura es la base de la inteligencia artificial general (AGI).
Como uno de los varios expertos senior en IA que dejaron OpenAI este año, Karpathy está trabajando actualmente en su propia startup educativa de IA. Sin duda, sus comentarios inyectaron una nueva dimensión de pensamiento en el campo de la investigación de la IA y proporcionaron información valiosa sobre la dirección futura del desarrollo de la IA.
Las opiniones de Karpathy provocaron un debate generalizado en la industria. Sus partidarios creen que revela una cuestión clave en la investigación actual de la IA: cómo hacer que la IA sea realmente capaz de resolver problemas complejos en lugar de limitarse a imitar el comportamiento humano. A los opositores les preocupa que el abandono prematuro del RLHF pueda conducir a una desviación en la dirección del desarrollo de la IA.
Dirección del artículo: https://arxiv.org/pdf/1706.03741
Las opiniones de Karpathy desencadenaron debates en profundidad sobre la dirección futura del desarrollo de la IA. Sus dudas sobre el RLHF llevaron a los investigadores a reexaminar los métodos actuales de entrenamiento de la IA y explorar caminos más efectivos, con el objetivo final de lograr una verdadera inteligencia artificial.