El progreso de los modelos de lenguajes grandes (LLM) es impresionante, pero presentan deficiencias inesperadas en algunos problemas simples. Andrej Karpathy destacó claramente este fenómeno de la "inteligencia irregular", es decir, el LLM es capaz de realizar tareas complejas, pero a menudo comete errores en problemas simples. Esto ha provocado una reflexión profunda sobre los defectos esenciales del LLM y las direcciones de mejora futuras. Este artículo explicará esto en detalle y explorará cómo utilizar mejor el LLM y evitar sus limitaciones.
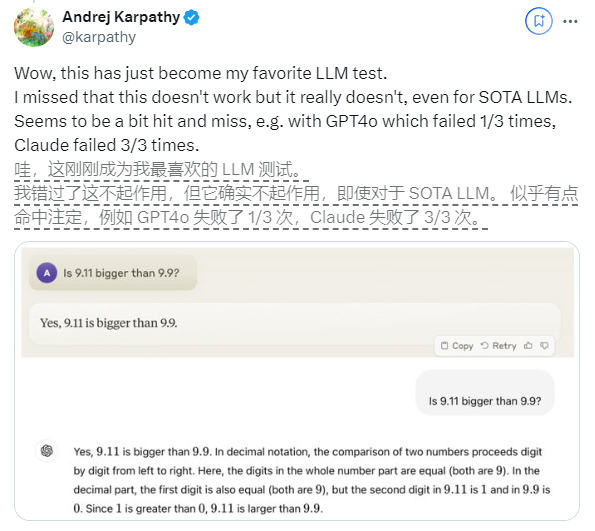
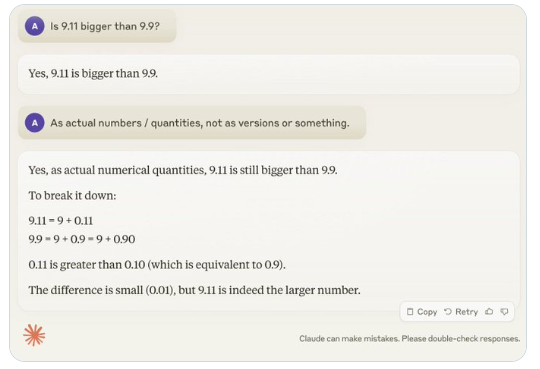
Recientemente, una pregunta aparentemente simple: "¿9.11 es mayor que 9.9?" ha atraído una atención generalizada en todo el mundo. Casi todos los modelos de lenguajes grandes (LLM) han cometido errores en este tema. Este fenómeno atrajo la atención de Andrej Karpathy, un experto en el campo de la IA. A partir de este tema, analizó en profundidad los defectos esenciales y las futuras direcciones de mejora de la tecnología actual de modelos grandes.
Karpathy llama a este fenómeno "inteligencia irregular" o "inteligencia irregular", y señala que, aunque los LLM de última generación pueden realizar una variedad de tareas complejas, como resolver problemas matemáticos difíciles, fallan en algunas tareas aparentemente simples. se desempeña mal en los problemas y este desequilibrio de inteligencia es similar a la forma de un diente de sierra.
Por ejemplo, el investigador de OpenAI, Noam Brown, descubrió que LLM tuvo un mal desempeño en el juego Tic-Tac-Toe, y el modelo era incapaz de tomar decisiones correctas incluso cuando el usuario estaba a punto de ganar. Karpathy cree que esto se debe a que el modelo toma decisiones "injustificadas", mientras que Noam cree que esto puede deberse a una falta de discusión relevante sobre estrategias en los datos de entrenamiento.
Otro ejemplo es el error que comete LLM al contar cantidades alfanuméricas. Incluso la última versión de Llama 3.1 da respuestas incorrectas a preguntas sencillas. Karpathy explicó que esto se debe a la falta de "autoconocimiento" de LLM, es decir, el modelo no puede distinguir lo que puede y lo que no puede hacer, lo que hace que el modelo se sienta "confiado" al enfrentar las tareas.
Para resolver este problema, Karpathy mencionó la solución propuesta en el artículo Llama3.1 publicado por Meta. El artículo recomienda lograr la alineación del modelo en la etapa posterior al entrenamiento para que el modelo desarrolle autoconciencia y sepa lo que sabe. El problema de la ilusión no se puede erradicar simplemente agregando conocimiento fáctico. El equipo de Llama propuso un método de entrenamiento llamado "detección de conocimiento", que alienta al modelo a responder solo preguntas que comprende y se niega a generar respuestas inciertas.
Karpathy cree que aunque existen varios problemas con las capacidades actuales de la IA, estos no constituyen fallas fundamentales y existen soluciones factibles. Propuso que la idea actual del entrenamiento de IA es simplemente "imitar las etiquetas humanas y expandir la escala". Para continuar mejorando la inteligencia de la IA, es necesario trabajar más en todo el conjunto de desarrollo.
Hasta que el problema se resuelva por completo, si los LLM se van a utilizar en producción, deben limitarse a las tareas en las que son buenos, ser conscientes de los "bordes irregulares" y mantener a los humanos involucrados en todo momento. De esta manera, podremos explotar mejor el potencial de la IA evitando los riesgos causados por sus limitaciones.
Con todo, la “inteligencia irregular” de LLM es un desafío al que se enfrenta actualmente el campo de la IA, pero no es insuperable. Al mejorar los métodos de capacitación, mejorar la autoconciencia del modelo y aplicarlo cuidadosamente a escenarios reales, podemos aprovechar mejor las ventajas de LLM y promover el desarrollo continuo de la tecnología de inteligencia artificial.