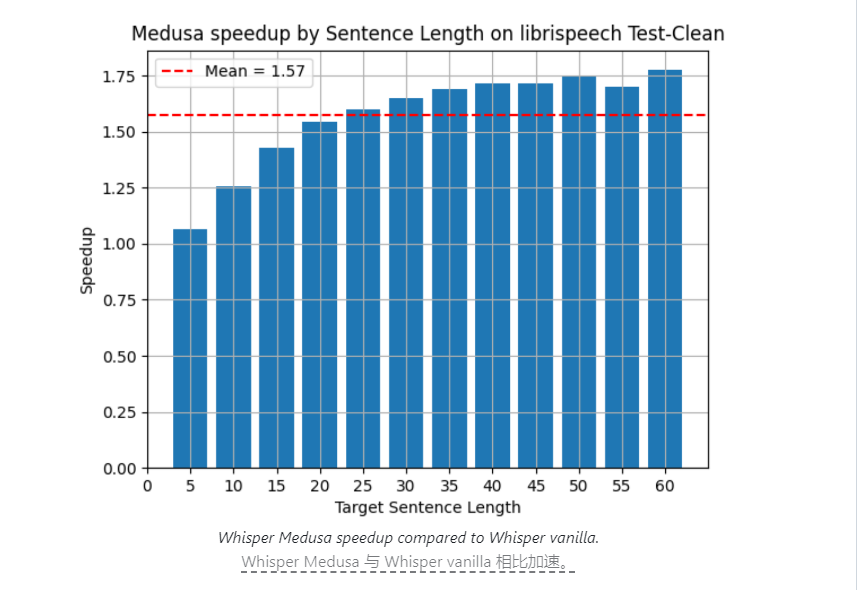
La empresa israelí de inteligencia artificial aiOla lanzó recientemente un modelo de reconocimiento de voz de código abierto llamado Whisper Medusa. El modelo ha logrado un avance significativo en velocidad y su velocidad de procesamiento es un 50% más rápida que el modelo Whisper de OpenAI. Este avance ha atraído una amplia atención en la industria y su núcleo radica en un mejor diseño arquitectónico y métodos de capacitación innovadores. Whisper Medusa no sólo es más rápido, sino que también mantiene un alto nivel de precisión y estabilidad, lo que aporta nuevas posibilidades al desarrollo de la tecnología de reconocimiento de voz.
La empresa israelí de inteligencia artificial aiOla ha logrado recientemente un gran avance en el campo de la tecnología de reconocimiento de voz y ha lanzado un modelo de reconocimiento de voz de código abierto llamado Whisper Medusa. La velocidad de procesamiento de este nuevo modelo es un 50% más rápida que la del modelo Whisper de OpenAI, que ha atraído una amplia atención en la industria.
La principal innovación de Whisper Medusa es su diseño arquitectónico mejorado. aiOla modificó la arquitectura original de Whisper e introdujo un mecanismo de atención de múltiples cabezales. Este mecanismo permite que el modelo se centre simultáneamente en información de diferentes subespacios de representación mediante el uso de múltiples cabezas de atención en paralelo. Esta innovación permite que el modelo prediga diez tokens a la vez en lugar del tradicional token a la vez, lo que mejora significativamente la velocidad de predicción de voz y el tiempo de ejecución de generación.
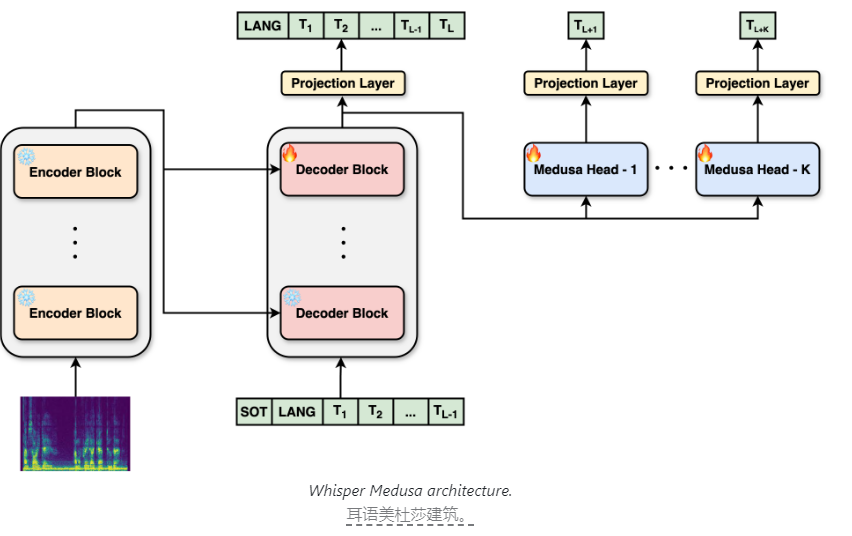
Vale la pena señalar que Whisper Medusa aumenta la velocidad sin sacrificar el rendimiento. Esto se debe al hecho de que su sistema principal todavía se basa en Whisper, lo que garantiza la precisión y estabilidad del modelo. Durante el proceso de formación, aiOla utiliza un método de aprendizaje automático llamado supervisión débil. Específicamente, congelaron los componentes principales de Whisper y utilizaron las transcripciones de audio generadas por el modelo como etiquetas para entrenar módulos de predicción de tokens adicionales. Este innovador método de entrenamiento mejora aún más la eficiencia y precisión del aprendizaje del modelo.
El lanzamiento de código abierto de Whisper Medusa podría tener un profundo impacto en el desarrollo de la tecnología de reconocimiento de voz. No sólo proporciona a los investigadores y desarrolladores una nueva y poderosa herramienta, sino que también puede impulsar el desarrollo de aplicaciones de procesamiento de voz más rápidas y eficientes. En el contexto de la creciente demanda de interacción por voz, este avance tecnológico sin duda abrirá nuevas posibilidades para la aplicación de la inteligencia artificial en el campo del reconocimiento de voz.
Con el lanzamiento de Whisper Medusa, podemos esperar ver aplicaciones más innovadoras basadas en este modelo, desde asistentes inteligentes hasta traducción en tiempo real y sistemas de control de voz, todo lo cual puede obtener como resultado mejoras significativas en el rendimiento. Este progreso no sólo marca un hito importante en la tecnología de reconocimiento de voz, sino que también dibuja un modelo más eficiente y fluido para el futuro de la interacción entre la inteligencia artificial y los humanos.
Dirección del proyecto: https://github.com/aiola-lab/whisper-medusa
abrazando cara: https://huggingface.co/aiola/whisper-medusa-v1
El código abierto y el alto rendimiento de Whisper Medusa indican que la tecnología de reconocimiento de voz marcará el comienzo de una nueva ola de desarrollo, brindando una experiencia más fluida y eficiente a diversas aplicaciones de voz y promoviendo la aplicación de tecnología de inteligencia artificial en más campos. Esperamos ver surgir más aplicaciones innovadoras basadas en este modelo.