El modelo de lenguaje Zamba2-2.7B recientemente lanzado por Zyphra está causando sensación en el campo de los modelos de lenguaje pequeños. Este modelo reduce significativamente los requisitos de recursos de inferencia y al mismo tiempo mantiene un rendimiento comparable al del modelo 7B, lo que lo hace ideal para aplicaciones de dispositivos móviles. Zamba2-2.7B ha mejorado significativamente la velocidad de respuesta, el uso de memoria y la latencia, lo cual es crucial para aplicaciones que requieren interacción en tiempo real, como asistentes virtuales y chatbots. Su mecanismo mejorado de atención compartida entrelazada y su proyector LoRA garantizan un procesamiento eficiente de tareas complejas.
Recientemente, Zyphra lanzó el nuevo modelo de lenguaje Zamba2-2.7B. Este lanzamiento es de gran importancia en la historia del desarrollo de modelos de lenguaje pequeños. El nuevo modelo logra mejoras significativas en rendimiento y eficiencia, y su conjunto de datos de entrenamiento alcanza aproximadamente 3 billones de tokens, lo que lo hace comparable en rendimiento al Zamba1-7B y otros modelos 7B líderes.
Lo más sorprendente es que los requisitos de recursos de Zamba2-2.7B durante la inferencia se reducen significativamente, lo que la convierte en una solución eficiente para aplicaciones de dispositivos móviles.
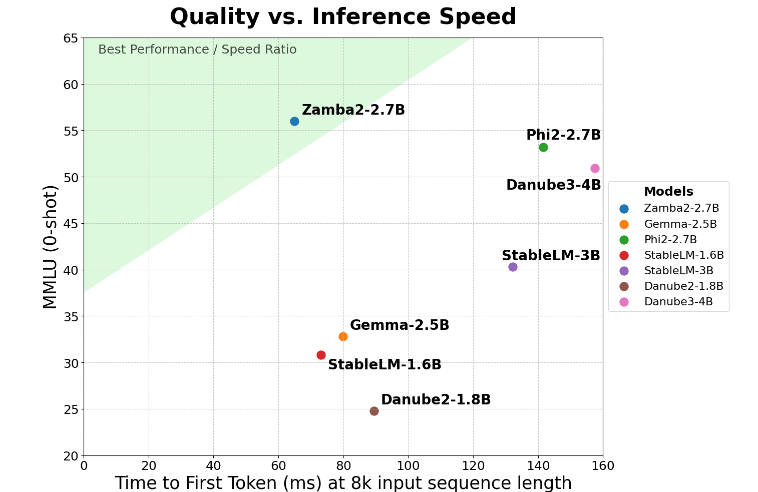
Zamba2-2.7B logra una mejora doble en la métrica clave de "tiempo de respuesta de primera generación", lo que significa que puede generar respuestas iniciales más rápido que la competencia. Esto es fundamental para aplicaciones como asistentes virtuales y chatbots que requieren interacción en tiempo real.
Además de la mejora de la velocidad, Zamba2-2.7B también hace un excelente trabajo en el uso de la memoria. Reduce la sobrecarga de memoria en un 27 %, lo que lo hace ideal para la implementación en dispositivos con recursos de memoria limitados. Esta gestión de memoria inteligente garantiza que el modelo pueda ejecutarse eficazmente en entornos con recursos informáticos limitados, ampliando su alcance de aplicación en diversos dispositivos y plataformas.
Zamba2-2.7B también tiene la importante ventaja de una menor latencia de compilación. En comparación con Phi3-3.8B, su latencia se reduce 1,29 veces, lo que hace que la interacción sea más fluida. La baja latencia es especialmente importante en aplicaciones que requieren una comunicación continua y fluida, como los robots de servicio al cliente y las herramientas educativas interactivas. Por lo tanto, Zamba2-2.7B es sin duda la primera opción para los desarrolladores en términos de mejorar la experiencia del usuario.
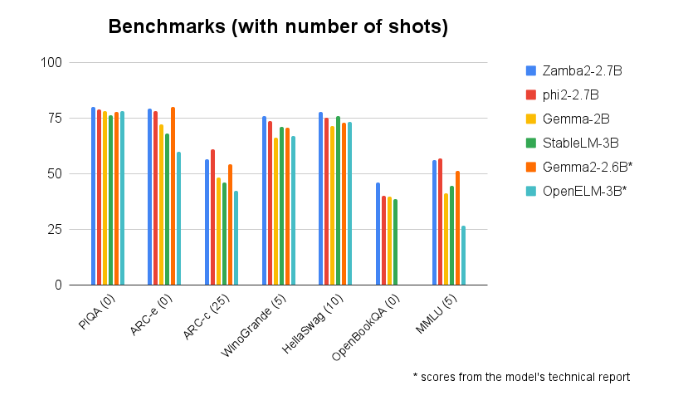
Zamba2-2.7B supera consistentemente en comparaciones de referencia con otros modelos de tamaño similar. Su rendimiento superior demuestra la innovación y los esfuerzos de Zyphra para promover el desarrollo de la tecnología de inteligencia artificial. Este modelo utiliza un mecanismo de atención compartida entrelazada mejorado y está equipado con un proyector LoRA en un módulo MLP compartido para garantizar un resultado de alto rendimiento al procesar tareas complejas.
Entrada modelo: https://huggingface.co/Zyphra/Zamba2-2.7B
Reflejos:
El modelo Zamba2-27B duplica el tiempo de primera respuesta, lo que lo hace adecuado para aplicaciones interactivas en tiempo real.
? Este modelo reduce la sobrecarga de memoria en un 27% y es adecuado para dispositivos con recursos limitados.
En términos de retraso de generación, Zamba2-2.7B supera a modelos similares, mejorando la experiencia del usuario.
En resumen, Zamba2-2.7B ha establecido un nuevo punto de referencia para los modelos de lenguajes pequeños con su excelente rendimiento y eficiencia, proporcionando a los desarrolladores herramientas de inteligencia artificial más potentes y flexibles, y se espera que desempeñe un papel importante en las aplicaciones móviles. Su utilización eficiente de los recursos y su fluida experiencia de usuario lo convierten en una fuerza impulsora clave para el desarrollo de futuras aplicaciones de IA.