La experiencia de Meta en el entrenamiento del modelo de lenguaje a gran escala Llama 3.1 nos ha mostrado desafíos y oportunidades sin precedentes en el desarrollo de la IA. El enorme grupo de 16.384 GPU experimentó una falla promedio cada 3 horas durante el período de entrenamiento de 54 días. Esto no solo destacó el rápido crecimiento de la escala del modelo de IA, sino que también expuso el enorme cuello de botella en la estabilidad de la supercomputación. sistema. Este artículo profundizará en los desafíos que Meta encontró durante el proceso de capacitación de Llama 3.1, las estrategias que adoptaron para enfrentar estos desafíos y analizará sus implicaciones para toda la industria de la IA.
En el mundo de la inteligencia artificial, cada avance va acompañado de datos asombrosos. Imagine que se están ejecutando 16.384 GPU al mismo tiempo. Esta no es una escena de una película de ciencia ficción, sino una representación real de Meta mientras entrena el último modelo Llama3.1. Sin embargo, detrás de este festín tecnológico se esconde una falla que ocurre en promedio cada 3 horas. Esta asombrosa cifra no sólo demuestra la velocidad del desarrollo de la IA, sino que también expone los enormes desafíos que enfrenta la tecnología actual.
De las 2.028 GPU utilizadas en Llama1 a las 16.384 GPU utilizadas en Llama3.1, este crecimiento vertiginoso no es solo un cambio en la cantidad, sino también un desafío extremo para la estabilidad del sistema de supercomputación existente. Los datos de la investigación de Meta muestran que durante el ciclo de entrenamiento de 54 días de Llama3.1, ocurrieron un total de 419 fallas inesperadas en componentes, aproximadamente la mitad de las cuales estaban relacionadas con la GPU H100 y su memoria HBM3. Estos datos nos hacen pensar: mientras se buscan avances en el rendimiento de la IA, ¿ha mejorado también simultáneamente la confiabilidad del sistema?
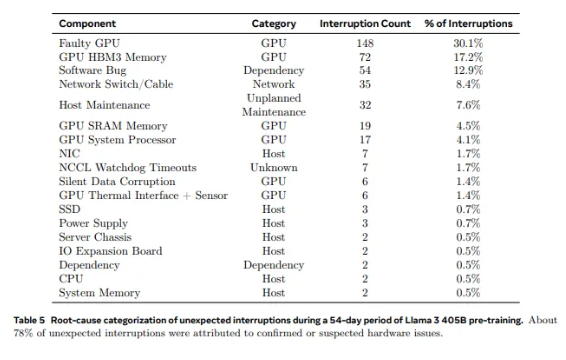
De hecho, hay un hecho indiscutible en el campo de la supercomputación: cuanto mayor es la escala, más difícil es evitar fallos. El grupo de entrenamiento Llama 3.1 de Meta consta de decenas de miles de procesadores, cientos de miles de otros chips y cientos de kilómetros de cables, un nivel de complejidad comparable al de la red neuronal de una pequeña ciudad. En un gigante de estas características, las averías parecen ser algo común.
Ante frecuentes fallos, el equipo Meta no estaba indefenso. Adoptaron una serie de estrategias de afrontamiento: reducir los tiempos de inicio del trabajo y de los puntos de control, desarrollar herramientas de diagnóstico patentadas, aprovechar el registrador de vuelo NCCL de PyTorch, etc. Estas medidas no sólo mejoran la tolerancia a fallos del sistema, sino que también mejoran las capacidades de procesamiento automatizado. Los ingenieros de Meta son como los bomberos de hoy en día, preparados para apagar cualquier incendio que pueda interrumpir el proceso de formación.
Sin embargo, los desafíos no provienen sólo del hardware en sí. Los factores ambientales y las fluctuaciones del consumo de energía también plantean desafíos inesperados a los clústeres de supercomputación. El equipo de Meta descubrió que los cambios de temperatura diurnos y nocturnos y las fluctuaciones drásticas en el consumo de energía de la GPU tendrán un impacto significativo en el rendimiento del entrenamiento. Este descubrimiento nos recuerda que mientras buscamos avances tecnológicos, no podemos ignorar la importancia de la gestión ambiental y del consumo de energía.
El proceso de formación de Llama3.1 puede considerarse una prueba definitiva de la estabilidad y fiabilidad del sistema de supercomputación. Las estrategias adoptadas por el equipo de Meta para afrontar los desafíos y las herramientas automatizadas desarrolladas brindan valiosa experiencia e inspiración para toda la industria de la IA. A pesar de las dificultades, tenemos motivos para creer que con el continuo avance de la tecnología, los futuros sistemas de supercomputación serán más potentes y estables.
En esta era de rápido desarrollo de la tecnología de inteligencia artificial, el intento de Meta es sin duda una aventura valiente. No solo amplía los límites de rendimiento de los modelos de IA, sino que también nos muestra los desafíos reales que enfrentamos al alcanzar los límites. Esperemos con ansias las infinitas posibilidades que ofrece la tecnología de inteligencia artificial y, al mismo tiempo, elogiemos a los ingenieros que trabajan incansablemente a la vanguardia de la tecnología. Cada intento, cada fracaso y cada avance que logran allana el camino para el progreso tecnológico humano.
Referencias:
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training- una falla cada tres horas para el clúster de entrenamiento de gpu metas 16384
El caso de capacitación de Llama 3.1 nos brindó lecciones valiosas y señaló la dirección futura del desarrollo de los sistemas de supercomputación: mientras buscamos el rendimiento, debemos otorgar gran importancia a la estabilidad y confiabilidad del sistema, y explorar activamente estrategias para lidiar con diversas fallas. Sólo así podremos garantizar el desarrollo continuo y estable de la tecnología de IA y beneficiar a la humanidad.