NVIDIA lanzó recientemente la serie Minitron de modelos de lenguaje pequeño, incluidas las versiones 4B y 8B. Esta medida tiene como objetivo reducir los costos de capacitación e implementación de modelos de lenguaje grandes y permitir que más desarrolladores utilicen fácilmente esta tecnología avanzada. Mediante tecnologías de "poda" y "destilación de conocimientos", el modelo Minitron reduce significativamente el tamaño del modelo manteniendo un rendimiento comparable al de los modelos grandes, e incluso supera a otros modelos conocidos en algunos indicadores. Esto es de gran importancia para promover la popularización de la tecnología de inteligencia artificial.
Recientemente, NVIDIA ha dado nuevos pasos en el campo de la inteligencia artificial. Han lanzado la serie Minitron de modelos de lenguaje pequeño, incluidas las versiones 4B y 8B. Estos modelos no solo aumentan la velocidad de entrenamiento 40 veces, sino que también facilitan a los desarrolladores su uso para diversas aplicaciones, como traducción, análisis de sentimientos e IA conversacional.
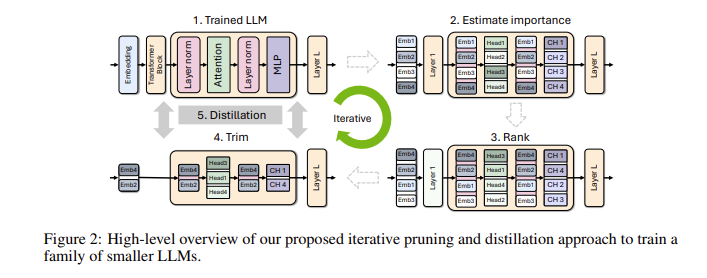
Quizás se pregunte, ¿por qué son tan importantes los modelos de lenguajes pequeños? De hecho, aunque los modelos de lenguajes grandes tradicionales tienen un rendimiento sólido, sus costos de capacitación e implementación son muy altos y, a menudo, requieren una gran cantidad de datos y recursos informáticos. Para que estas tecnologías avanzadas sean asequibles para más personas, el equipo de investigación de NVIDIA ideó una manera brillante: combinar dos tecnologías: "poda" y "destilación de conocimientos" para reducir de manera eficiente el tamaño del modelo.
Específicamente, los investigadores primero partirán de un modelo grande existente y lo podarán. Evalúan la importancia de cada neurona, capa o cabeza de atención en el modelo y eliminan las que son menos importantes. De esta forma, el modelo se vuelve mucho más pequeño y los recursos y el tiempo necesarios para la formación también se reducen considerablemente. A continuación, también utilizarán un conjunto de datos a pequeña escala para realizar un entrenamiento de destilación de conocimientos en el modelo podado para restaurar la precisión del modelo. Sorprendentemente, este proceso no sólo ahorra dinero, sino que también mejora el rendimiento del modelo.
En pruebas reales, el equipo de investigación de NVIDIA logró buenos resultados en la familia de modelos Nemotron-4. Redujeron con éxito el tamaño del modelo de 2 a 4 veces manteniendo un rendimiento similar. Lo que es aún más emocionante es que el modelo 8B supera a otros modelos conocidos como Mistral7B y LLaMa-38B en múltiples indicadores y requiere 40 veces menos datos de entrenamiento durante el proceso de entrenamiento, lo que ahorra 1,8 veces en costos de computación. ¿Imagínese lo que esto significa? ¡Más desarrolladores pueden experimentar potentes capacidades de IA con menos recursos y costos!
NVIDIA hace que estos modelos Minitron optimizados sean de código abierto en Huggingface para que todos puedan usarlos libremente.
Entrada de demostración: https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
Reflejos:
** Velocidad de entrenamiento mejorada **: La velocidad de entrenamiento del modelo Minitron es 40 veces más rápida que la de los modelos tradicionales, lo que permite a los desarrolladores ahorrar tiempo y esfuerzo.
**Ahorro de costos**: a través de la tecnología de poda y destilación de conocimientos, los recursos informáticos y el volumen de datos necesarios para la capacitación se reducen significativamente.
? **Compartir código abierto**: el modelo Minitron ha sido de código abierto en Huggingface, por lo que más personas pueden acceder a él y utilizarlo fácilmente, promoviendo la popularización de la tecnología de inteligencia artificial.
El código abierto del modelo Minitron marca un avance importante en la aplicación práctica de modelos de lenguaje pequeño. También indica que la tecnología de inteligencia artificial se volverá más popular y más fácil de usar, lo que empoderará a más desarrolladores y escenarios de aplicaciones. En el futuro, podemos esperar más innovaciones similares para promover el desarrollo continuo de la tecnología de inteligencia artificial.