El último modelo ChatQA2 lanzado por Nvidia AI ha logrado avances significativos en el campo de la generación mejorada de comprensión y recuperación de contexto de texto largo (RAG). Se basa en el potente modelo Llama3, que mejora significativamente las capacidades de seguimiento de instrucciones, el rendimiento de RAG y las capacidades de comprensión de textos largos al ampliar la ventana de contexto a 128 000 tokens y adoptar un ajuste de instrucciones de tres etapas. ChatQA2 es capaz de mantener la coherencia contextual y una alta recuperación al procesar datos de texto masivos y ha demostrado un rendimiento comparable al GPT-4-Turbo en múltiples pruebas comparativas, e incluso lo ha superado en algunos aspectos. Esto marca un avance significativo en la capacidad de los modelos de lenguaje grandes para manejar textos largos.
Avance en el rendimiento: ChatQA2 mejora significativamente las capacidades de seguimiento de instrucciones, el rendimiento de RAG y la comprensión de textos largos al ampliar la ventana de contexto a 128 000 tokens y adoptar un proceso de ajuste de instrucciones de tres etapas. Este avance tecnológico permite que el modelo mantenga la coherencia contextual y un alto nivel de recuperación al procesar conjuntos de datos de hasta mil millones de tokens.
Detalles técnicos: ChatQA2 se desarrolló utilizando soluciones técnicas detalladas y reproducibles. El modelo primero expande la ventana contextual de Llama3-70B de 8K a 128K tokens mediante un entrenamiento previo continuo. A continuación, se aplicó un proceso de ajuste de instrucciones de tres etapas para garantizar que el modelo pudiera manejar eficazmente una variedad de tareas.
Resultados de la evaluación: en la evaluación InfiniteBench, ChatQA2 logró una precisión comparable a GPT-4-Turbo-2024-0409 en tareas como resumen de texto largo, preguntas y respuestas, opción múltiple y diálogo, y lo superó en el punto de referencia RAG. Este logro destaca las capacidades integrales de ChatQA2 en diferentes longitudes de contexto y características.
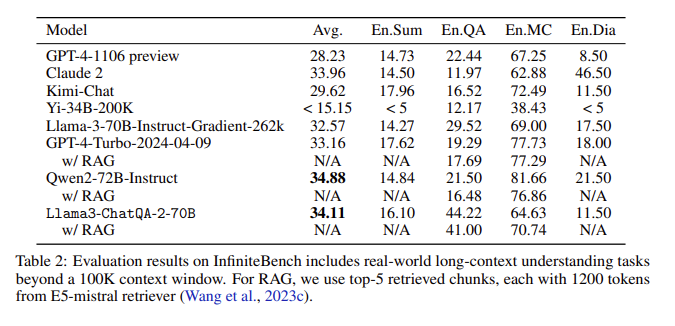
Abordar cuestiones clave: ChatQA2 aborda cuestiones clave en el proceso RAG, como la fragmentación del contexto y la baja recuperación, mediante el uso de un recuperador de texto largo de última generación para mejorar la precisión y la eficiencia de la recuperación.
Al ampliar la ventana de contexto e implementar un proceso de ajuste de instrucciones de tres etapas, ChatQA2 logra una comprensión de textos largos y un rendimiento RAG comparable al GPT-4-Turbo. Este modelo proporciona soluciones flexibles para una variedad de tareas posteriores, equilibrando precisión y eficiencia a través de textos largos avanzados y técnicas de generación mejoradas con recuperación.
Entrada del artículo: https://arxiv.org/abs/2407.14482
La aparición de ChatQA2 ofrece nuevas posibilidades para el procesamiento de textos largos y aplicaciones RAG. Su eficiencia y precisión proporcionan un valor de referencia importante para el desarrollo futuro de la inteligencia artificial. La investigación abierta sobre este modelo también fomenta la colaboración entre el mundo académico y la industria, impulsando un progreso continuo en este campo. Esperamos ver más aplicaciones innovadoras basadas en este modelo en el futuro.