Llama 3.1, este modelo gigante de lenguaje de código abierto con 405 mil millones de parámetros, causó un gran impacto en el campo de la IA debido a filtraciones sin lanzamiento oficial. Su rendimiento es tan potente que incluso supera al GPT-4o en algunas pruebas comparativas, estableciendo un nuevo punto de referencia para los modelos de código abierto. La acalorada discusión en Reddit demuestra aún más su impacto en la comunidad de IA. Este artículo profundizará en el rendimiento, los aspectos más destacados y las medidas de seguridad de Llama 3.1 y desvelará este misterioso modelo.
¡Se filtró Llama3.1! Lo escuchaste bien, este modelo de código abierto con 405 mil millones de parámetros ha causado revuelo en Reddit. Este es probablemente el modelo de código abierto más cercano a GPT-4o hasta la fecha, e incluso lo supera en algunos aspectos.
Llama3.1 es un modelo de lenguaje grande desarrollado por Meta (anteriormente Facebook). Aunque aún no hay un lanzamiento oficial, la versión filtrada ya ha causado revuelo en la comunidad. Este modelo incluye no sólo el modelo base, sino también resultados de referencia de 8B, 70B y el parámetro máximo de 405B.
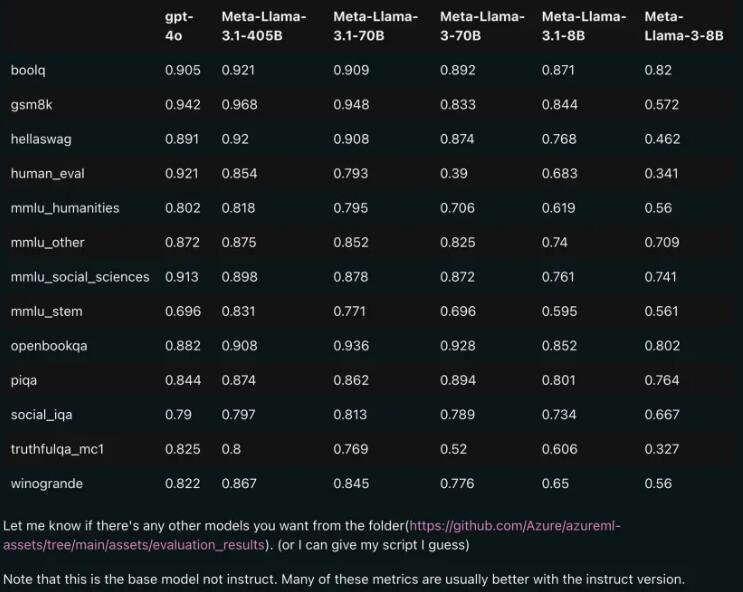
Comparación de rendimiento: Llama3.1 vs GPT-4o
A juzgar por los resultados de la comparación filtrados, incluso la versión 70B de Llama3.1 superó al GPT-4o en múltiples pruebas comparativas. Esta es la primera vez que un modelo de código abierto alcanza el nivel SOTA (State of the Art, la tecnología más avanzada) en múltiples puntos de referencia. La gente no puede evitar suspirar: ¡El poder del código abierto es realmente poderoso!
Aspectos destacados del modelo: soporte en varios idiomas, datos de entrenamiento más completos
El modelo Llama3.1 utiliza más de 15T de tokens de fuentes públicas para la capacitación, y la fecha límite para los datos previos a la capacitación es diciembre de 2023. No sólo admite inglés, sino también francés, alemán, hindi, italiano, portugués, español y tailandés. Esto lo hace excelente en casos de uso de conversaciones multilingües.

El equipo de investigación de Llama3.1 concede gran importancia a la seguridad del modelo. Utilizaron un enfoque de recopilación de datos multifacético que combinaba datos sintéticos y generados por humanos para mitigar posibles riesgos de seguridad. Además, el modelo también introduce avisos de límites y avisos contradictorios para mejorar el control de calidad de los datos.
Fuente de la tarjeta modelo: https://pastebin.com/9jGkYbXY#google_vignette
La filtración de Llama 3.1 sin duda tendrá un profundo impacto en el campo de la IA. No sólo demuestra el enorme potencial de los modelos de código abierto, sino que también desencadena una mayor reflexión sobre la seguridad de los modelos y las cuestiones éticas. En el futuro, seguiremos prestando atención a Llama 3.1 y su desarrollo posterior, y esperamos que traiga más sorpresas al avance de la tecnología de IA.