La competencia en el campo de la inteligencia artificial es feroz y el auge de los modelos de código abierto está desafiando el dominio de los gigantes tecnológicos. Recientemente, la startup de hardware de inteligencia artificial Groq lanzó dos modelos de lenguaje de código abierto: Llama-3-Groq-70B-Tool-Use y Llama3Groq Tool Use 8B, y logró resultados impresionantes en Berkeley Function Call Ranking (BFCL). Entre ellos, el parámetro 70B La versión superó los modelos propietarios de OpenAI, Google, Anthropic y otras empresas. El éxito de estos modelos radica no solo en su potente rendimiento, sino también en el uso de datos sintéticos generados éticamente durante el proceso de formación, lo que resuelve eficazmente problemas como la privacidad de los datos y el sobreajuste, y proporciona nuevas oportunidades para el desarrollo sostenible del campo. de inteligencia artificial.
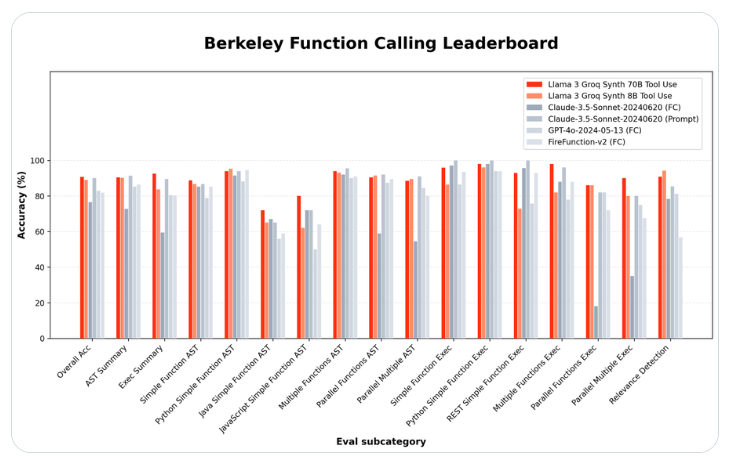
La startup de hardware de inteligencia artificial Groq ha lanzado dos modelos de lenguaje de código abierto que superan a los gigantes tecnológicos en su capacidad para utilizar herramientas especializadas. El nuevo modelo Llama-3-Groq-70B-Tool-Use ha capturado el primer puesto en el Berkeley Function Call Ranking (BFCL), superando a productos propietarios de empresas como OpenAI, Google y Anthropic.
El líder del proyecto Groq, Rick Lamers, anunció el avance en un artículo de X.com. Dijo: “Estoy orgulloso de anunciar la herramienta Llama3Groq que utiliza los modelos 8B y 70B. Esta es una versión completamente ajustada de la herramienta de código abierto de Llama3 que ha alcanzado la posición número uno en BFCL, superando a todos los demás modelos, incluidos los modelos propietarios. Como Claude Sonnet3.5, GPT-4Turbo, GPT-4o y Gemini1.5Pro”.
Datos sintéticos e IA ética: un nuevo paradigma en el entrenamiento de modelos
La versión de parámetros 70B más grande logró una precisión general del 90,76 % en BFCL, mientras que el modelo 8B más pequeño obtuvo una puntuación del 89,06 %, ubicándose en tercer lugar en general. Estos resultados muestran que los modelos de código abierto pueden igualar o incluso superar el rendimiento de las alternativas de código cerrado en tareas específicas.
Groq desarrolló los modelos en asociación con la empresa de investigación de inteligencia artificial Glaive, utilizando un ajuste completo y optimización de preferencia directa (DPO) en el modelo base Llama-3 de Meta. El equipo enfatiza que solo utilizan datos sintéticos generados éticamente para la capacitación, abordando preocupaciones comunes sobre la privacidad de los datos y el sobreajuste.
Estos modelos ahora están disponibles a través de la API Groq y la plataforma Hugging Face. Esta accesibilidad puede acelerar la innovación en áreas que requieren el uso de herramientas complejas y llamadas de funciones, como codificación automatizada, análisis de datos y asistentes interactivos de IA.
Groq también lanzó una demostración pública de Hugging Face Spaces, que permite a los usuarios interactuar con el modelo y probar sus capacidades de herramientas de primera mano. Al igual que Gradio, que Hugging Face adquirió en diciembre de 2021, muchas de las demostraciones de Hugging Face Spaces se crean de esta manera. La comunidad de IA ha respondido con entusiasmo y muchos investigadores y desarrolladores están ansiosos por explorar las capacidades de estos modelos.
Reflejos:
⭐ El modelo de IA de código abierto lanzado por Groq supera a los modelos propietarios del gigante tecnológico en tareas específicas
⭐ Al utilizar datos sintéticos para la capacitación, Groq desafía los problemas comunes de privacidad de datos y sobreajuste en el desarrollo de modelos de IA.
⭐ El lanzamiento de modelos de código abierto puede cambiar el camino de desarrollo del campo de la IA y promover una accesibilidad más amplia a la IA y el cultivo de ecosistemas innovadores.
El éxito del modelo de código abierto de Groq ha inyectado nueva vitalidad al desarrollo del campo de la inteligencia artificial y también indica que los modelos de código abierto desempeñarán un papel cada vez más importante en el futuro. Su aplicación de datos sintéticos proporciona nuevas ideas para resolver problemas como la privacidad de los datos y el sesgo del modelo, lo que merece un estudio en profundidad y una referencia por parte de la industria. Esperamos con ansias la aparición de más modelos de código abierto excelentes en el futuro para promover el progreso continuo de la tecnología de inteligencia artificial.