Écosystème de couche intermédiaire de base de données distribuée Apache ShardingSphere v5.5.0
5.5.0
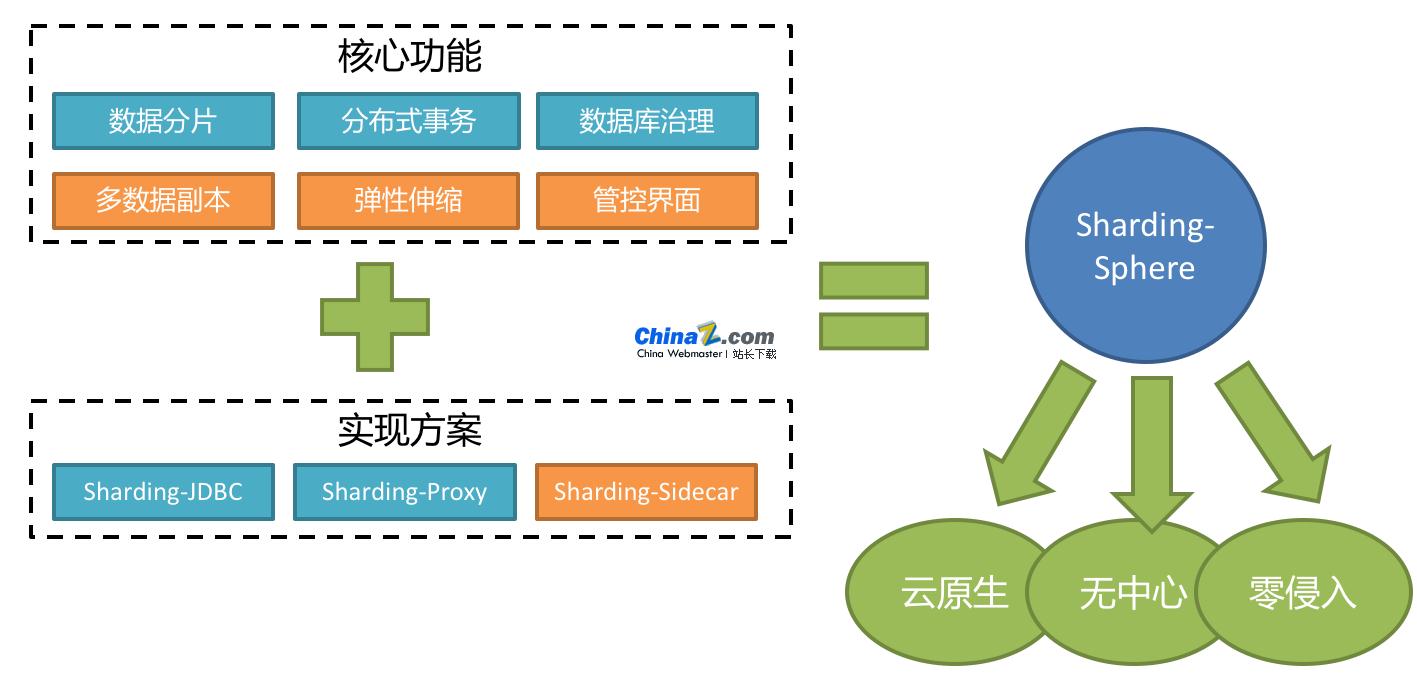
Apache ShardingSphere est un écosystème composé d'un ensemble de solutions middleware de bases de données distribuées open source. Il se compose de JDBC, Proxy et Sidecar (en cours de planification), trois produits indépendants les uns des autres mais pouvant être déployés et utilisés ensemble. Ils fournissent tous des fonctions standardisées de partage de données, de transactions distribuées et de gestion de bases de données, et peuvent être appliqués à divers scénarios d'application tels que l'isomorphisme Java, les langages hétérogènes, le cloud natif, etc.
Apache ShardingSphere se positionne comme un middleware de base de données relationnelle, visant à utiliser pleinement et raisonnablement les capacités de calcul et de stockage des bases de données relationnelles dans des scénarios distribués, plutôt que de mettre en œuvre une nouvelle base de données relationnelle. Il capture l’essence des choses en se concentrant sur l’immuable. Les bases de données relationnelles occupent encore aujourd'hui un marché énorme et constituent la pierre angulaire du cœur de métier de chaque entreprise. Elles seront difficiles à ébranler à l'avenir. À ce stade, nous nous concentrons davantage sur les incréments basés sur les fondations d'origine que sur la subversion.
Apache ShardingSphere 5.x a commencé à se concentrer sur une architecture enfichable, et les composants fonctionnels du projet peuvent être étendus de manière flexible de manière enfichable. Actuellement, des fonctions telles que le partage de données, la séparation en lecture-écriture, les copies de données multiples, le cryptage des données et les tests de résistance des bases de données fantômes, ainsi que la prise en charge de SQL et de protocoles tels que MySQL, PostgreSQL, SQLServer et Oracle, sont toutes intégrées dans le projet via des plug-ins. Les développeurs peuvent personnaliser leur propre système, tout comme en utilisant des blocs de construction. Apache ShardingSphere fournit actuellement des dizaines de SPI comme points d'extension système, et d'autres sont encore en cours d'ajout.
ShardingSphere-JDBC
Positionné comme un framework Java léger, il fournit des services supplémentaires dans la couche JDBC de Java. Il utilise le client pour se connecter directement à la base de données et fournit des services sous forme de packages jar sans déploiement ni dépendances supplémentaires. Il peut être compris comme une version améliorée du pilote JDBC et est entièrement compatible avec JDBC et divers frameworks ORM.
Applicable à tout framework ORM basé sur JDBC, tel que : JPA, Hibernate, Mybatis, Spring JDBC Template ou utilisez directement JDBC.
Prend en charge tout pool de connexions à des bases de données tierces, tels que : DBCP, C3P0, BoneCP, Druid, HikariCP, etc.
Prend en charge toute base de données qui implémente la spécification JDBC. Actuellement, il prend en charge MySQL, Oracle, SQLServer, PostgreSQL et toute base de données qui suit la norme SQL92.
ShardingSphere-Proxy
Positionné comme un agent de base de données transparent, il fournit un serveur qui encapsule le protocole binaire de la base de données pour prendre en charge des langages hétérogènes. Actuellement, MySQL et PostgreSQL sont fournis. Il peut utiliser n'importe quel client d'accès compatible avec le protocole MySQL/PostgreSQL (tel que MySQL Command Client, MySQL Workbench, Navicat, etc.) pour exploiter les données, ce qui les rend plus conviviaux pour les administrateurs de base de données.
Il est totalement transparent pour l'application et peut être utilisé directement comme serveur MySQL/PostgreSQL.
Applicable à tout client compatible avec le protocole MySQL/PostgreSQL.
ShardingSphere-Side-car (TODO)
Positionné comme proxy de base de données cloud natif pour Kubernetes, il proxy tous les accès à la base de données sous la forme de Sidecar. Une solution sans centre et sans intrusion fournit une couche d'engagement qui interagit avec la base de données, à savoir Database Mesh, également connue sous le nom de grille de base de données.
L'objectif de Database Mesh est de savoir comment connecter de manière organique les applications d'accès aux données distribuées et les bases de données. Il se concentre davantage sur l'interaction et le tri efficace des interactions entre les applications et les bases de données désordonnées. En utilisant Database Mesh, les applications et les bases de données qui accèdent à la base de données formeront à terme un énorme système de grille. Il suffit d'enregistrer les applications et les bases de données dans le système de grille. Ce sont tous des objets gérés par la couche de maillage.
architecture hybride
ShardingSphere-JDBC adopte une architecture décentralisée et convient aux applications OLTP légères hautes performances développées en Java ; ShardingSphere-Proxy fournit une entrée statique et une prise en charge de langages hétérogènes et convient aux applications OLAP ainsi qu'à la gestion et à l'exploitation de bases de données fragmentées.
Apache ShardingSphere est un écosystème composé de plusieurs terminaux d'accès. En mélangeant ShardingSphere-JDBC et ShardingSphere-Proxy et en utilisant le même centre d'enregistrement pour configurer uniformément les stratégies de partitionnement, des systèmes d'application adaptés à différents scénarios peuvent être construits de manière flexible, permettant aux architectes d'ajuster plus librement le meilleur système à l'architecture actuelle de l'entreprise.
1. Fragmentation des données
Sous-bibliothèque et sous-table
Séparation en lecture et en écriture
Personnalisation de la stratégie de partage
Clé primaire distribuée non centralisée
2. Transactions distribuées
Interface de transaction standardisée
Transactions XA fortement cohérentes
Affaires flexibles
3. Gestion de la base de données
Gouvernance distribuée
Mise à l'échelle élastique
Observabilité (traçage distribué, métriques)
Cryptage et décryptage des données
Test de pression au manomètre