bitnet.cpp est le cadre d'inférence officiel pour les LLM 1 bit (par exemple, BitNet b1.58). Il propose une suite de noyaux optimisés, qui prennent en charge l'inférence rapide et sans perte de modèles 1,58 bits sur CPU (avec la prise en charge NPU et GPU prochainement).
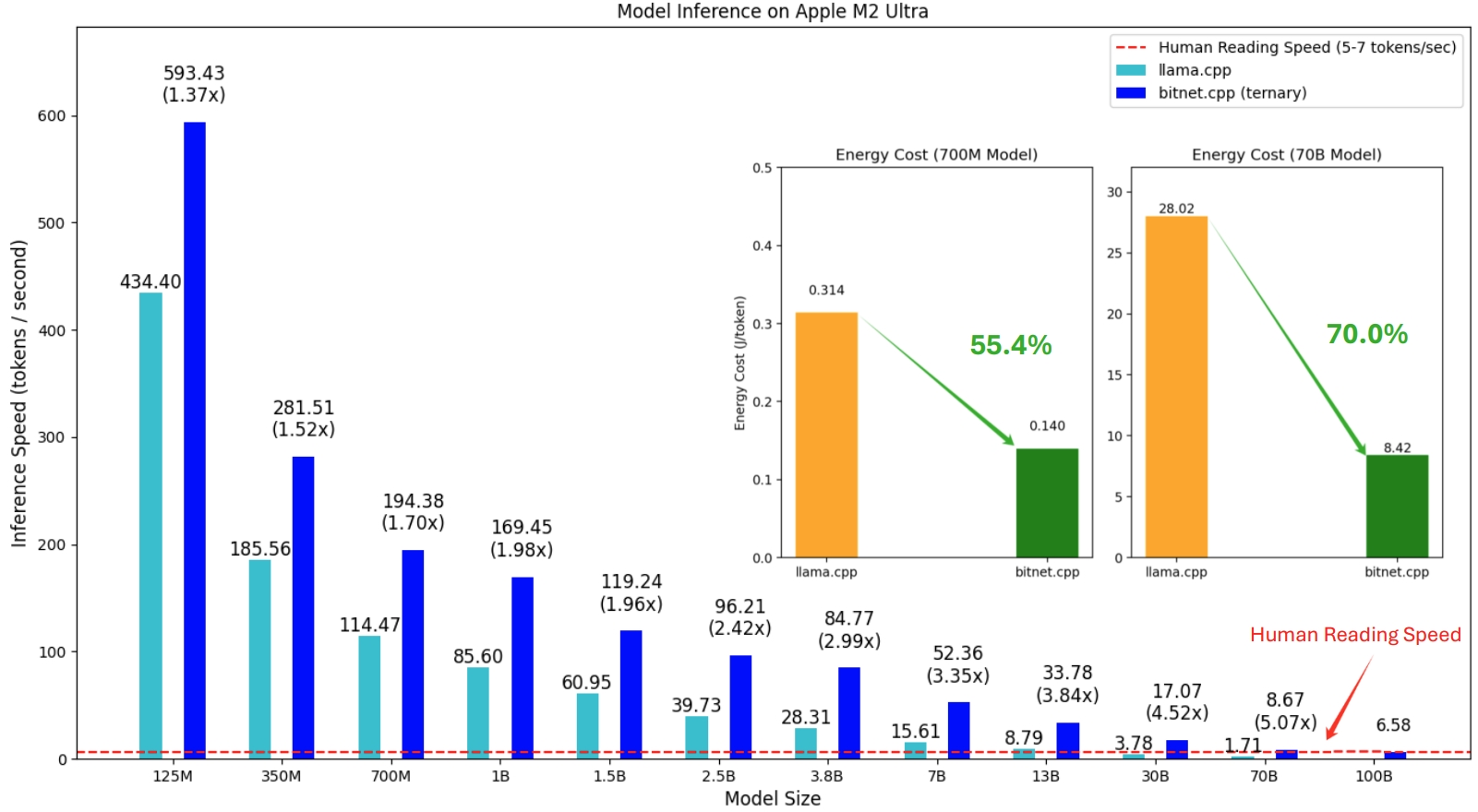
La première version de bitnet.cpp est destinée à prendre en charge l'inférence sur les processeurs. bitnet.cpp atteint des accélérations de 1,37x à 5,07x sur les processeurs ARM, les modèles plus grands bénéficiant de gains de performances plus importants. De plus, il réduit la consommation d'énergie de 55,4 % à 70,0 % , augmentant ainsi l'efficacité globale. Sur les processeurs x86, les accélérations vont de 2,37x à 6,17x avec des réductions d'énergie comprises entre 71,9 % et 82,2 % . De plus, bitnet.cpp peut exécuter un modèle BitNet b1.58 de 100 B sur un seul processeur, atteignant des vitesses comparables à la lecture humaine (5 à 7 jetons par seconde), améliorant considérablement le potentiel d'exécution de LLM sur des appareils locaux. Veuillez vous référer au rapport technique pour plus de détails.


Les modèles testés sont des configurations factices utilisées dans un contexte de recherche pour démontrer les performances d'inférence de bitnet.cpp.
Une démo de bitnet.cpp exécutant un modèle BitNet b1.58 3B sur Apple M2 :
21/10/2024 AI Infra 1 bit : partie 1.1, inférence BitNet b1.58 rapide et sans perte sur les processeurs
17/10/2024 sortie de bitnet.cpp 1.0.
21/03/2024 L'ère des LLM 1 bit__Training_Tips_Code_FAQ
27/02/2024 L'ère des LLM 1 bit : tous les grands modèles de langage sont en 1,58 bits
17/10/2023 BitNet : mise à l'échelle des transformateurs 1 bit pour les grands modèles de langage
Ce projet est basé sur le framework llama.cpp. Nous tenons à remercier tous les auteurs pour leurs contributions à la communauté open source. De plus, les noyaux de bitnet.cpp sont construits sur les méthodologies de table de recherche mises au point dans T-MAC. Pour l'inférence de LLM généraux à faible bit au-delà des modèles ternaires, nous recommandons d'utiliser T-MAC.
❗️ Nous utilisons les LLM 1 bit existants disponibles sur Hugging Face pour démontrer les capacités d'inférence de bitnet.cpp. Ces modèles ne sont ni formés ni publiés par Microsoft. Nous espérons que la sortie de bitnet.cpp inspirera le développement de LLM 1 bit dans des contextes à grande échelle en termes de taille de modèle et de jetons de formation.
| Modèle | Paramètres | Processeur | Noyau | ||
|---|---|---|---|---|---|
| I2_S | TL1 | TL2 | |||
| bitnet_b1_58-large | 0,7B | x86 | ✔ | ✘ | ✔ |
| BRAS | ✔ | ✔ | ✘ | ||
| bitnet_b1_58-3B | 3.3B | x86 | ✘ | ✘ | ✔ |
| BRAS | ✘ | ✔ | ✘ | ||
| Lama3-8B-1.58-100B-jetons | 8.0B | x86 | ✔ | ✘ | ✔ |
| BRAS | ✔ | ✔ | ✘ | ||
python>=3.9
cmake>=3.22
bruit>=18
Développement de bureau avec C++
Outils C++-CMake pour Windows
Git pour Windows
Compilateur C++-Clang pour Windows
Prise en charge MS-Build pour LLVM-Toolset (clang)
Pour les utilisateurs Windows, installez Visual Studio 2022. Dans le programme d'installation, activez au moins les options suivantes (cela installe également automatiquement les outils supplémentaires requis comme CMake) :
Pour les utilisateurs Debian/Ubuntu, vous pouvez télécharger avec le script d'installation automatique
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
conda (fortement recommandé)
Important
Si vous utilisez Windows, n'oubliez pas de toujours utiliser une invite de commande développeur/PowerShell pour VS2022 pour les commandes suivantes
Cloner le dépôt
git clone --récursif https://github.com/microsoft/BitNet.gitcd BitNet
Installer les dépendances
# (Recommandé) Créer un nouvel environnement condaconda create -n bitnet-cpp python=3.9 conda active bitnet-cpp pip install -r exigences.txt
Construire le projet
# Téléchargez le modèle depuis Hugging Face, convertissez-le au format gguf quantifié et construisez le projectpython setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s# Ou vous pouvez télécharger manuellement le modèle et exécuter avec pathhuggingface-cli local télécharger HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dir models/Llama3-8B-1.58-100B-tokens python setup_env.py -md modèles/Llama3-8B-1.58-100B-tokens -q i2_s
utilisation : setup_env.py [-h] [--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}] [--model-dir MODEL_DIR] [ --log-dir LOG_DIR] [--quant-type {i2_s,tl1}] [--quant-embd]
[--use-préréglé]
Configurer l'environnement pour exécuter l'inférence
arguments facultatifs :
-h, --help afficher ce message d'aide et quitter
--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}, -hr {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3- 8B-1.58-100B-jetons}
Modèle utilisé pour l'inférence
--model-dir MODEL_DIR, -md MODEL_DIR
Répertoire pour sauvegarder/charger le modèle
--log-dir LOG_DIR, -ld LOG_DIR
Répertoire pour enregistrer les informations de journalisation
--quant-type {i2_s,tl1}, -q {i2_s,tl1}
Type de quantification
--quant-embd Quantifier les intégrations en f16
--use-pretuned, -p Utiliser les paramètres préréglés du noyau# Exécutez l'inférence avec le modelpython quantifié run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel est retourné au jardin. Mary s'est rendue à la cuisine. Sandra s'est rendu à la cuisine. Sandra est allée dans le couloir. John est allé dans la chambre. Mary est retournée dans le jardin ?nRéponse :" -n 6 -temp 0# Sortie :# Daniel est retourné dans le jardin. Mary se rendit à la cuisine. Sandra se rendit à la cuisine. Sandra se dirigea vers le couloir. John est allé dans la chambre. Mary est retournée au jardin. Où est Marie ?# Réponse : Marie est dans le jardin.
utilisation : run_inference.py [-h] [-m MODEL] [-n N_PREDICT] -p PROMPT [-t THREADS] [-c CTX_SIZE] [-temp TEMPERATURE]
Exécuter l'inférence
arguments facultatifs :
-h, --help afficher ce message d'aide et quitter
-m MODÈLE, --model MODÈLE
Chemin d'accès au fichier modèle
-n N_PREDICT, --n-predict N_PREDICT
Nombre de jetons à prédire lors de la génération de texte
-p INVITE, --prompt INVITE
Invite à générer du texte à partir de
-t FILS, --threads FILS
Nombre de threads à utiliser
-c TAILLE_CTX, --taille-ctx TAILLE_CTX
Taille du contexte d'invite
-temp TEMPÉRATURE, --température TEMPÉRATURE
La température, un hyperparamètre qui contrôle le caractère aléatoire du texte généréNous fournissons des scripts pour exécuter le benchmark d'inférence fournissant un modèle.
usage: e2e_benchmark.py -m MODEL [-n N_TOKEN] [-p N_PROMPT] [-t THREADS] Setup the environment for running the inference required arguments: -m MODEL, --model MODEL Path to the model file. optional arguments: -h, --help Show this help message and exit. -n N_TOKEN, --n-token N_TOKEN Number of generated tokens. -p N_PROMPT, --n-prompt N_PROMPT Prompt to generate text from. -t THREADS, --threads THREADS Number of threads to use.
Voici une brève explication de chaque argument :
-m , --model : Le chemin d'accès au fichier modèle. Il s'agit d'un argument obligatoire qui doit être fourni lors de l'exécution du script.
-n , --n-token : Le nombre de jetons à générer lors de l'inférence. Il s'agit d'un argument facultatif avec une valeur par défaut de 128.
-p , --n-prompt : Le nombre de jetons d'invite à utiliser pour générer du texte. Il s'agit d'un argument facultatif avec une valeur par défaut de 512.
-t , --threads : Le nombre de threads à utiliser pour exécuter l'inférence. Il s'agit d'un argument facultatif avec une valeur par défaut de 2.
-h , --help : Afficher le message d'aide et quitter. Utilisez cet argument pour afficher les informations d'utilisation.
Par exemple:
python utils/e2e_benchmark.py -m /path/to/model -n 200 -p 256 -t 4
Cette commande exécuterait le test d'inférence en utilisant le modèle situé dans /path/to/model , générant 200 jetons à partir d'une invite de 256 jetons, en utilisant 4 threads.
Pour la présentation du modèle qui n'est prise en charge par aucun modèle public, nous fournissons des scripts pour générer un modèle factice avec la présentation du modèle donnée et exécuter le benchmark sur votre machine :
python utils/generate-dummy-bitnet-model.py models/bitnet_b1_58-large --outfile models/dummy-bitnet-125m.tl1.gguf --outtype tl1 --model-size 125M# Exécutez un benchmark avec le modèle généré, utilisez -m pour spécifier le chemin du modèle, -p pour spécifier l'invite traitée, -n pour spécifier le nombre de jetons à générerpython utils/e2e_benchmark.py -m models/dummy-bitnet-125m.tl1.gguf -p 512 -n 128