Magika est un nouvel outil de détection de type de fichier alimenté par l'IA qui s'appuie sur les progrès récents de l'apprentissage profond pour fournir une détection précise. Sous le capot, Magika utilise un modèle Keras personnalisé et hautement optimisé qui ne pèse que quelques Mo environ et permet une identification précise des fichiers en quelques millisecondes, même lorsqu'il est exécuté sur un seul processeur.
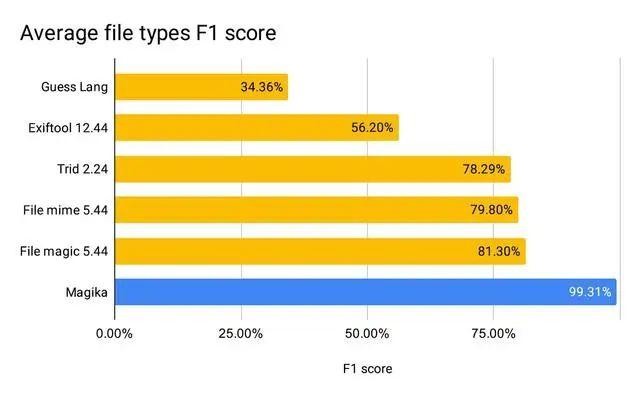
Lors d'une évaluation portant sur plus d'un million de fichiers et plus de 100 types de contenu (couvrant à la fois les formats de fichiers binaires et textuels), Magika atteint plus de 99 % de précision et de rappel. Magika est utilisé à grande échelle pour contribuer à améliorer la sécurité des utilisateurs de Google en acheminant les fichiers Gmail, Drive et Safe Browsing vers les analyseurs de sécurité et de politique de contenu appropriés. Apprenez-en davantage dans notre document de recherche !
Vous pouvez essayer Magika sans rien installer en utilisant notre démo Web, qui s'exécute localement dans votre navigateur !
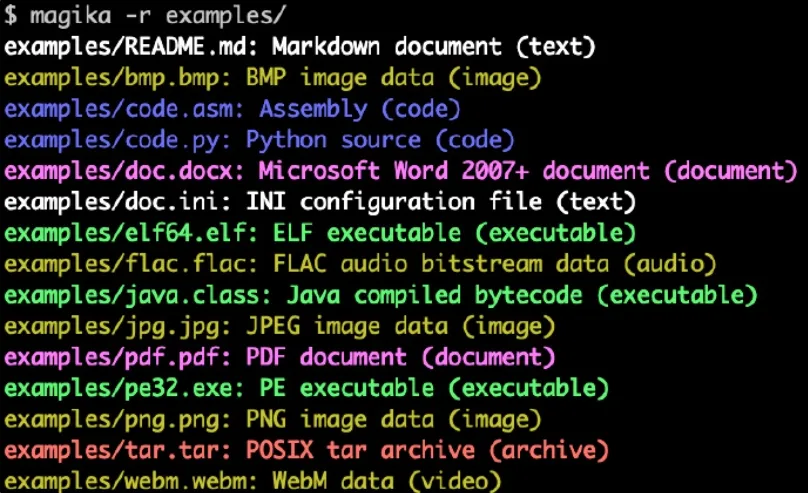
Voici un exemple de ce à quoi ressemble la sortie de la ligne de commande Magika :
Pour plus de contexte, vous pouvez lire notre annonce initiale sur le blog OSS de Google.

Important
Nous sommes sur le point de publier un certain nombre de nouveautés, et elles sont prêtes à être testées !
Un nouveau modèle ML prenant en charge plus de 200 types de contenu.
Une nouvelle CLI écrite en Rust. Cela remplacera la précédente CLI écrite en python. Plus d'informations ici. La base de code Rust peut également être utilisée pour les applications écrites en Rust, voir la documentation.
Package Python 0.6.0rc1 : cette version fournit le nouveau modèle avec la prise en charge de plus de 200 types de contenu, la CLI écrite en Rust (qui remplace l'ancienne écrite en python) et une API Python remaniée avec quelques modifications importantes, voir la documentation et le journal des modifications ! Si vous avez besoin de documentation sur la version stable, parcourez ce référentiel avec la dernière balise stable, ici.
Disponible sous forme d'outil de ligne de commande écrit en Rust, d'API Python, d'API Rust et de version expérimentale TFJS (qui alimente notre démo Web).
Formé sur un ensemble de données de plus de 25 millions de fichiers sur plus de 100 types de contenu.
Lors de notre évaluation, Magika atteint une précision et un rappel moyens de plus de 99 %, surpassant les approches existantes.
Plus de 200 types de contenu (voir liste complète).
Une fois le modèle chargé (il s’agit d’une surcharge ponctuelle), le temps d’inférence est d’environ 5 ms par fichier.
Traitement par lots : vous pouvez transmettre plusieurs fichiers à la ligne de commande et à l'API en même temps, et Magika utilisera le traitement par lots pour accélérer le temps d'inférence. Vous pouvez appeler Magika même avec des milliers de fichiers en même temps. Vous pouvez également utiliser -r pour analyser de manière récursive un répertoire.
Temps d'inférence quasi constant indépendamment de la taille du fichier ; Magika n'utilise qu'un sous-ensemble limité des octets du fichier.
Magika utilise un système de seuil par type de contenu qui détermine s'il faut « faire confiance » à la prédiction du modèle ou s'il faut renvoyer une étiquette générique, telle que « Document texte générique » ou « Données binaires inconnues ».
Prend en charge trois modes de prédiction différents, qui ajustent la tolérance aux erreurs : high-confidence , medium-confidence et best-guess .
C'est open source ! (Et d’autres sont encore à venir.)
Pour plus de détails, consultez la documentation du package python et du package js (dev docs).
Commencer
Ligne de commande Python
API Python
Modèle TFJS expérimental et package npm
Installation
Exécuté sur Docker
Usage
Configuration du développement
Documents importants
Limitations connues et contribution
Foire aux questions
Ressources supplémentaires
Document de recherche et citation
Licence
Clause de non-responsabilité
Magika est disponible en tant que magika sur PyPI :
$ pip installer magika
Si vous avez l'intention d'utiliser Magika uniquement en ligne de commande, vous souhaiterez peut-être utiliser $ pipx install magika à la place.
git clone https://github.com/google/magika cd magika/ docker build -t magika . docker run -it --rm -v $(pwd):/magika magika -r /magika/tests_data
La nouvelle ligne de commande est écrite en Rust et est disponible dans le package magika python.
Exemples :
$ cd tests_data/basic && magika -r *asm/code.asm : Assemblage (code) batch/simple.bat : fichier batch DOS (code) c/code.c : source C (code) css/code.css : source CSS (code) csv/magika_test.csv : document CSV (code) dockerfile/Dockerfile : Dockerfile (code) docx/doc.docx : document Microsoft Word 2007+ (document) epub/doc.epub : document EPUB (document) epub/magika_test.epub : document EPUB (document) flac/test.flac : données de flux binaire audio FLAC (audio) handlebars/example.handlebars : source du guidon (code) html/doc.html : document HTML (code) ini/doc.ini : fichier de configuration INI (texte) javascript/code.js : source JavaScript (code) jinja/exemple.j2 : modèle Jinja (code) jpeg/magika_test.jpg : données d'image JPEG (image) json/doc.json : document JSON (code) latex/sample.tex : document LaTeX (texte) makefile/simple.Makefile : source du Makefile (code) markdown/README.md : document Markdown (texte) [...]
$magika ./tests_data/basic/python/code.py --json
[
{ "path": "./tests_data/basic/python/code.py", "result": { "status": "ok", "value": { "dl": { "description": "source Python" , "extensions": [ "py", "pyi"
], "group": "code", "is_text": true, "label": "python", "mime_type": "text/x-python"
}, "output": { "description": "Source Python", "extensions": [ "py", "pyi"
], "group": "code", "is_text": true, "label": "python", "mime_type": "text/x-python"
}, "score": 0,753000020980835
}
}
}
]$ chat doc.ini | magie - - : fichier de configuration INI (texte)
$ magika --aide
Détermine le type de contenu des fichiers avec le deep-learning
Utilisation : magika [OPTIONS] [CHEMIN]...
Arguments : [CHEMIN]...
Liste des chemins d'accès aux fichiers à analyser.
Utilisez un tiret (-) pour lire à partir de l'entrée standard (ne peut être utilisé qu'une seule fois).
Possibilités :
-r, --récursif
Identifie les fichiers dans les répertoires au lieu d'identifier le répertoire lui-même
--pas de déréférencement
Identifie les liens symboliques tels quels au lieu d'identifier leur contenu en les suivant
--couleurs
Imprime avec des couleurs quelle que soit la prise en charge du terminal
--pas de couleurs
Imprime sans couleurs, quelle que soit la prise en charge du terminal
-s, --output-score
Imprime le score de prédiction en plus du type de contenu
-i, --type-mime
Imprime le type MIME au lieu de la description du type de contenu
-l, --étiquette
Imprime une simple étiquette au lieu de la description du type de contenu
--json
Imprime au format JSON
--jsonl
Imprime au format JSONL
--format <PERSONNALISÉ>
Imprime en utilisant un format personnalisé (utilisez --help pour plus de détails).
Les espaces réservés suivants sont pris en charge :
%p Le chemin du fichier
%l L'étiquette unique identifiant le type de contenu
%d La description du type de contenu
%g Le groupe du type de contenu
%m Le type MIME du type de contenu
%e Extensions de fichiers possibles pour le type de contenu
%s Le score du type de contenu pour le fichier
%S Le score du type de contenu pour le fichier en pourcentage
%b La sortie du modèle en cas d'annulation (vide sinon)
%% Un % littéral
-h, --aide
Imprimer l'aide (voir un résumé avec '-h')
-V, --version
Version imprimableVoir ici pour une documentation plus détaillée.
Exemples :
>>> from magika import Magika>>> m = Magika()>>> res = m.identify_bytes(b"# ExemplenCeci est un exemple de démarque !")>>> print(res.output.label)markdown
Voir la documentation Python pour une documentation détaillée.
Nous proposons également Magika sous forme de package expérimental pour les personnes intéressées par une utilisation dans une application Web. Notez que les performances d'implémentation de Magika JS sont nettement plus lentes et vous devez vous attendre à dépenser plus de 100 ms par fichier.
Voir la documentation js pour les détails.
Voir la section « Configuration du développement » dans la documentation Python.
Documentation sur la CLI
Documentation sur la nouvelle CLI Rust
Documentation sur les liaisons pour différentes langues
Liste des types de contenu pris en charge (pour la v1, d'autres à venir).
Liste des types de contenu pris en charge pour le nouveau modèle
Documentation sur la façon d'interpréter la sortie de Magika.
Foire aux questions
Magika s'améliore considérablement par rapport à l'état de l'art, mais il y a toujours place à l'amélioration ! Des travaux supplémentaires peuvent être effectués pour augmenter la précision de la détection, la prise en charge de types de contenu supplémentaires, les liaisons pour davantage de langues, etc.
Cette version initiale ne cible pas la détection polyglotte, et nous sommes impatients de voir des exemples contradictoires de la communauté. Nous aimerions également entendre la communauté nous parler des problèmes rencontrés, des erreurs de détection, des demandes de fonctionnalités, du besoin d'assistance pour des types de contenu supplémentaires, etc.
Consultez nos problèmes GitHub ouverts pour voir ce qui figure sur notre feuille de route et veuillez signaler les erreurs de détection ou les demandes de fonctionnalités en ouvrant les problèmes GitHub (de préférence) ou en nous envoyant un e-mail à [email protected].
REMARQUE : N'envoyez PAS de rapports sur les fichiers pouvant contenir des informations personnelles, le rapport contient (une petite) partie du contenu du fichier !
Voir CONTRIBUTING.md pour plus de détails.
Nous avons rassemblé ici un certain nombre de FAQ.
Article du blog OSS de Google sur l'annonce de Magika.
Démo Web : démo Web.
Nous décrivons comment nous avons développé Magika et les choix que nous avons faits dans notre document de recherche.
Si vous utilisez ce logiciel pour vos recherches, veuillez le citer comme suit :
@misc{magika, title={{Magika : Détection de type de contenu basée sur l'IA}}, author={{Fratantonio, Yanick et Invernizzi, Luca et Farah, Loua et Kurt, Thomas et Zhang, Marina et Albertini, Ange et Galilée , François et Metitieri, Giancarlo et Cretin, Julien et Petit-Bianco, Alexandre et Tao, David et Bursztein, Elie}}, année={2024}, eprint={2409.13768}, archivePrefix={arXiv}, PrimaryClass={cs. CR}, url={https://arxiv.org/abs/2409.13768},
}Veuillez nous contacter directement à [email protected]
Apache 2.0 ; voir LICENSE pour plus de détails.
Ce projet n'est pas un projet officiel de Google. Il n'est pas pris en charge par Google et Google décline spécifiquement toute garantie quant à sa qualité, sa qualité marchande ou son adéquation à un usage particulier.