SonicSim
Speech

Kai Li 1 , Wendi Sang 1 , Chang Zeng 2 , Runxuan Yang 1 , Guo Chen 1 , Xiaolin Hu 1
1 Université Tsinghua, Chine
2 Institut national d'informatique, Japon
Papier | Démo
Nous présentons SonicSim, une boîte à outils synthétique conçue pour générer des données hautement personnalisables pour les sources sonores en mouvement. SonicSim est développé sur la base de la plate-forme de simulation d'IA intégrée, Habitat-sim, prenant en charge des ajustements de paramètres à plusieurs niveaux, notamment au niveau de la scène, du microphone et de la source, générant ainsi des données synthétiques plus diverses. En utilisant SonicSim, nous avons construit un ensemble de données de référence de sources sonores mobiles, SonicSet, en utilisant l'ensemble de données LibriSpeech, le Freesound Dataset 50k (FSD50K) et Free Music Archive (FMA), ainsi que 90 scènes de Matterport3D pour évaluer les modèles de séparation et d'amélioration de la parole.
[2024-10-30] Nous avons corrigé les bugs d'installation de l'environnement et mis à jour le code de formation pour les modèles de séparation et d'amélioration de la parole sur l'ensemble de données SonicSet.
[2024-10-23] Nous publions le training code pour les modèles de séparation et d'amélioration de la parole sur l'ensemble de données SonicSet.
[2024-10-03] Nous publions l'article sur arxiv
[2024-10-01] Nous publions l'ensemble de données de séparation de la parole dans le monde réel, qui vise à évaluer les performances des modèles de séparation de la parole dans des scénarios du monde réel.
[2024-07-31] Nous publions l' SonicSim dataset , qui comprend des tâches de séparation et d'amélioration de la parole.
[2024-07-24] Nous publions les scripts pour dataset construction et les modèles pré-entraînés pour speech separation and enhancement .

Importation de scènes 3D : prend en charge l'importation d'une variété d'actifs 3D à partir d'ensembles de données tels que Matterport3D, permettant une génération efficace et évolutive d'environnements acoustiques complexes.
Simulation d'environnement acoustique :
Simule les réflexions sonores dans la géométrie des pièces à l’aide de modélisation acoustique intérieure et d’algorithmes de traçage de chemin bidirectionnel.
Mappe les étiquettes sémantiques des scènes 3D aux propriétés des matériaux, en définissant les coefficients d'absorption, de diffusion et de transmission des surfaces.
Synthétise les données de source sonore en mouvement en fonction des chemins de source, garantissant une haute fidélité aux conditions du monde réel.
Configurations de microphone : offre une large gamme de configurations de microphone, notamment mono, binaurales et ambisoniques, ainsi que la prise en charge de réseaux de microphones linéaires et circulaires personnalisés.
Positionnement de la source et du microphone : permet de personnaliser ou de randomiser les positions de la source sonore et du microphone. Prend en charge les trajectoires de mouvement pour les simulations de sources sonores en mouvement, ajoutant du réalisme aux scénarios acoustiques dynamiques.

Vous pouvez télécharger l'ensemble de données pré-construit à partir du lien suivant :
| Nom de l'ensemble de données | Onedrive | Disque Baidu |
|---|---|---|
| dossier train (40 fichiers rar divisés, 377G) | [Lien de téléchargement] | [Lien de téléchargement] |
| val.rar (4.9G) | [Lien de téléchargement] | [Lien de téléchargement] |
| test.rar (2.2G) | [Lien de téléchargement] | [Lien de téléchargement] |
| données de référence septembre (8,57G) | [Lien de téléchargement] | [Lien de téléchargement] |
| données de référence enh (7.70G) | [Lien de téléchargement] | [Lien de téléchargement] |
| Nom de l'ensemble de données | Onedrive | Disque Baidu |
|---|---|---|
| Ensemble de données du monde réel (1.0G) | [Lien de téléchargement] | [Lien de téléchargement] |
Ensemble de données RealMAN : RealMAN


Pour construire l'ensemble de données vous-même, veuillez vous référer au README dans le dossier SonicSim-SonicSet/data-script . Ce document fournit des instructions détaillées sur la façon d'utiliser les scripts fournis pour générer l'ensemble de données.
Pour configurer l'environnement de formation et d'inférence, utilisez le fichier YAML fourni :
conda create -n SonicSim-Train python=3.10 conda activer SonicSim-Train pip installer Cython==3.0.10 numpy==1.26.4 pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118 pip install -r exigences.txt -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
Accédez au répertoire separation et exécutez le script suivant pour générer l'ensemble de validation fixe :
séparation des CD python generate_fixed_validation.py --raw_dir=../SonicSim-SonicSet/SonicSet/scene_datasets/mp3d/val --save_dir=../SonicSim-SonicSet/SonicSet/scene_datasets/mp3d/val-sep-2 --is_mono python generate_fixed_test.py --raw_dir=/home/pod/SonicSim/SonicSim/SonicSim-SonicSet/SonicSet/scene_datasets/mp3d/test --is_mono
Accédez au répertoire enhancement et exécutez le script suivant pour générer l'ensemble de validation fixe :
amélioration du CD python generate_fixed_validation.py --raw_dir=../SonicSim-SonicSet/SonicSet/scene_datasets/mp3d/val --save_dir=../SonicSim-SonicSet/SonicSet/scene_datasets/mp3d/val-enh-noise --is_mono python generate_fixed_test.py --raw_dir=/home/pod/SonicSim/SonicSim/SonicSim-SonicSet/SonicSet/scene_datasets/mp3d/test --is_mono
Accédez au répertoire separation et exécutez le script de formation avec le fichier de configuration spécifié :
séparation des CD python train.py --conf_dir=configs/afrcnn.yaml
Accédez au répertoire enhancement et exécutez le script de formation avec le fichier de configuration spécifié :
amélioration du CD python train.py --conf_dir=config/dccrn.yaml
Veuillez vérifier le contenu du fichier README.md dans les dossiers sep-checkpoints et enh-checkpoints, télécharger les modèles pré-entraînés appropriés dans Release et décompressez-les dans les dossiers appropriés.
Accédez au répertoire separation et exécutez le script d'inférence avec le fichier de configuration spécifié :
séparation des CD python inference.py --conf_dir=../sep-checkpoints/TFGNet-Noise/config.yaml
Accédez au répertoire enhancement et exécutez le script d'inférence avec le fichier de configuration spécifié :
amélioration du CD python inference.py --conf_dir=../enh-checkpoints/TaylorSENet-Noise/config.yaml


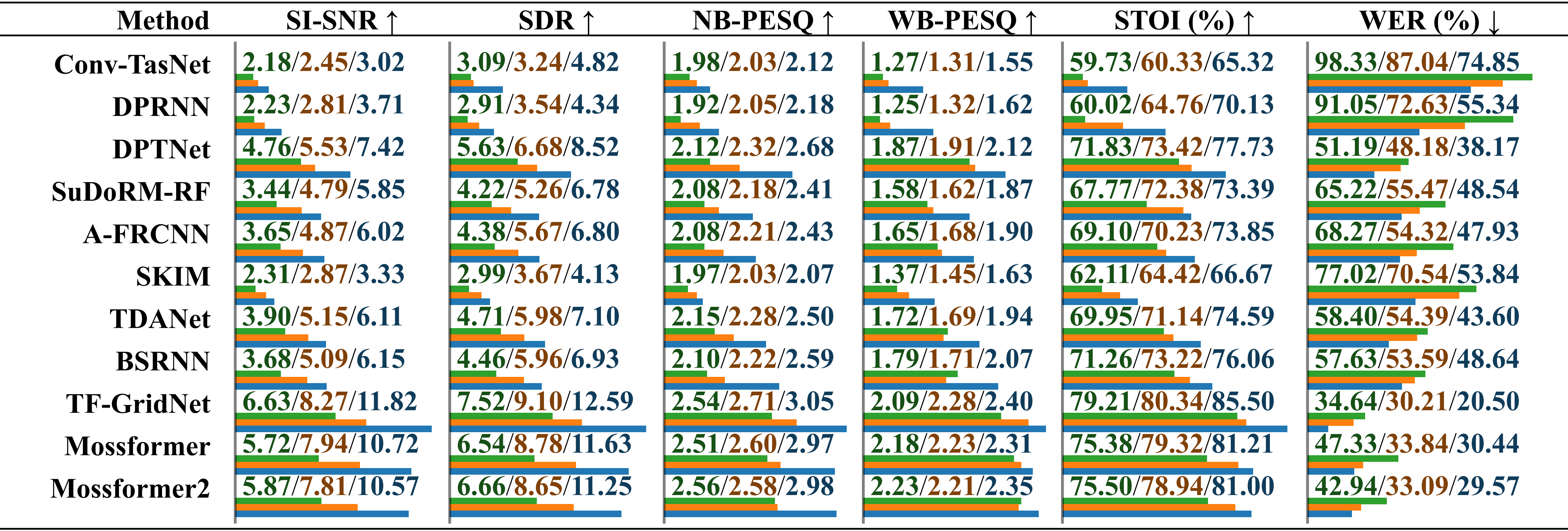
Évaluation comparative des performances de modèles formés sur différents ensembles de données en utilisant de l'audio réel enregistré avec du bruit ambiant . Les résultats sont rapportés séparément pour « formé sur LRS2-2Mix », « formé sur Libri2Mix » et « formé sur SonicSet », distingués par une barre oblique. La longueur relative est indiquée sous la valeur par des barres horizontales.


Évaluation comparative des performances de modèles formés sur différents ensembles de données en utilisant de l'audio réel enregistré avec du bruit musical . Les résultats sont rapportés séparément pour « formé sur LRS2-2Mix », « formé sur Libri2Mix » et « formé sur SonicSet », distingués par une barre oblique.


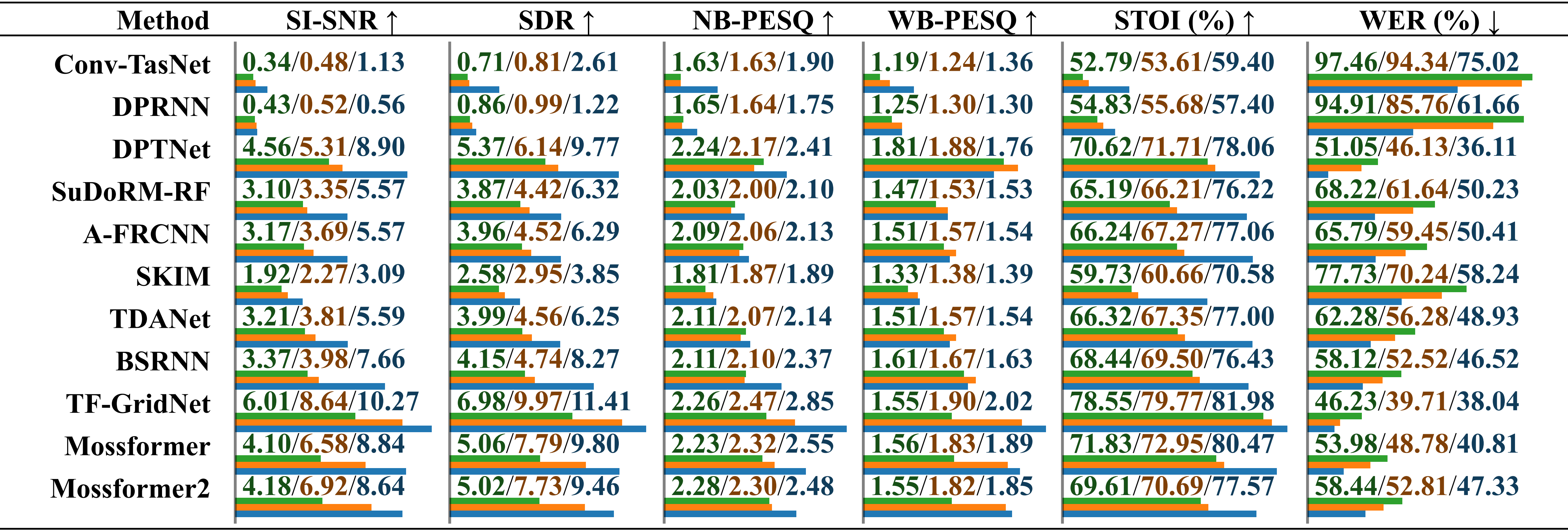
Évaluation comparative des performances de modèles formés sur différents ensembles de données à l'aide de l'ensemble de données RealMAN. Les résultats sont rapportés séparément pour « formé sur VoiceBank+DEMAND », « formé sur DNS Challenge » et « formé sur SonicSet », distingués par une barre oblique.
Nous avons formé des modèles de séparation et d'amélioration sur l'ensemble de données SonicSet. Les résultats sont les suivants :


Comparaison des méthodes de séparation de la parole existantes sur l'ensemble de données SonicSet. Les performances de chaque modèle sont répertoriées séparément pour les résultats sous « bruit environnemental » et « bruit musical », distingués par une barre oblique.


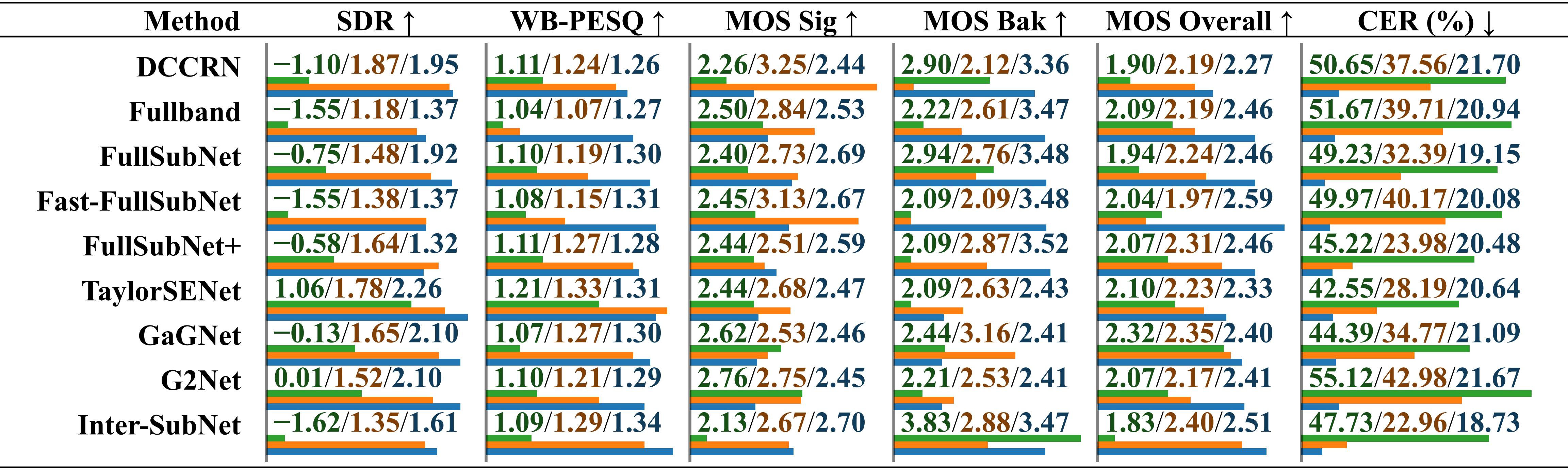
Comparaison des méthodes d'amélioration de la parole existantes sur la Comparaison des méthodes d'amélioration de la parole à l'aide de l'ensemble de test SonicSet. Les mesures sont répertoriées séparément sous « bruit ambiant » et « bruit musical », distinguées par une barre oblique.
Nous tenons à exprimer notre gratitude aux personnes suivantes :
LibriSpeech pour fournir les données vocales.
SoundSpaces pour l'environnement de simulation.
Apple pour avoir fourni des scripts de synthèse audio dynamique.
Ce travail est sous licence internationale Creative Commons Attribution-ShareAlike 4.0.