Article : Sur la généralisation sans tir au moment du test des modèles vision-langage : avons-nous vraiment besoin d'un apprentissage rapide ? .
Auteurs : Maxime Zanella, Ismail Ben Ayed.
Il s'agit du référentiel GitHub officiel de notre article accepté au CVPR '24. Ce travail présente la méthode MeanShift Test-time Augmentation (MTA), exploitant les modèles Vision-Language sans nécessiter un apprentissage rapide. Notre méthode augmente de manière aléatoire une seule image en N vues augmentées, puis alterne entre deux étapes clés (voir mta.py et Détails sur la section code.) :
Cette étape consiste à calculer un score pour chaque vue augmentée afin d'évaluer sa pertinence et sa qualité (score d'inlierness).
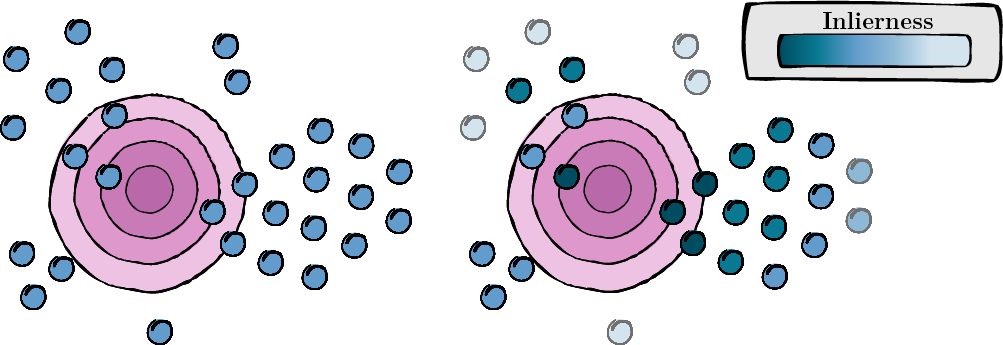
Figure 1 : Calcul du score pour chaque vue augmentée.
Sur la base des scores calculés à l'étape précédente, nous recherchons le mode des points de données (MeanShift).
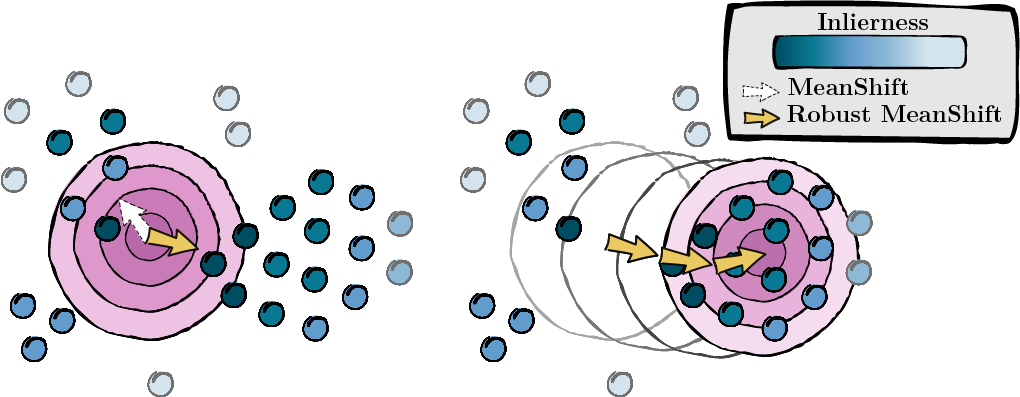
Figure 2 : Recherche du mode, pondéré par les scores d'intégrité.
Nous suivons l'installation et le prétraitement de TPT. Cela garantit que votre ensemble de données est formaté de manière appropriée. Vous pouvez trouver leur référentiel ici. Si cela est plus pratique, vous pouvez modifier les noms de dossier de chaque ensemble de données dans le dictionnaire ID_to_DIRNAME dans data/datautils.py (ligne 20).
Exécutez MTA sur l'ensemble de données ImageNet avec une valeur aléatoire de 1 et une invite « une photo d'un » en entrant la commande suivante :
python main.py --data /path/to/your/data --mta --testsets I --seed 1Ou les 15 ensembles de données à la fois :
python main.py --data /path/to/your/data --mta --testsets I/A/R/V/K/DTD/Flower102/Food101/Cars/SUN397/Aircraft/Pets/Caltech101/UCF101/eurosat --seed 1Plus d'informations sur la procédure dans mta.py.
gaussian_kernelsolve_mtay ) de manière uniforme.Si vous trouvez ce projet utile, veuillez le citer comme suit :
@inproceedings { zanella2024test ,
title = { On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? } ,
author = { Zanella, Maxime and Ben Ayed, Ismail } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 23783--23793 } ,
year = { 2024 }
}Nous exprimons notre gratitude aux auteurs de TPT pour leur contribution open source. Vous pouvez trouver leur référentiel ici.


