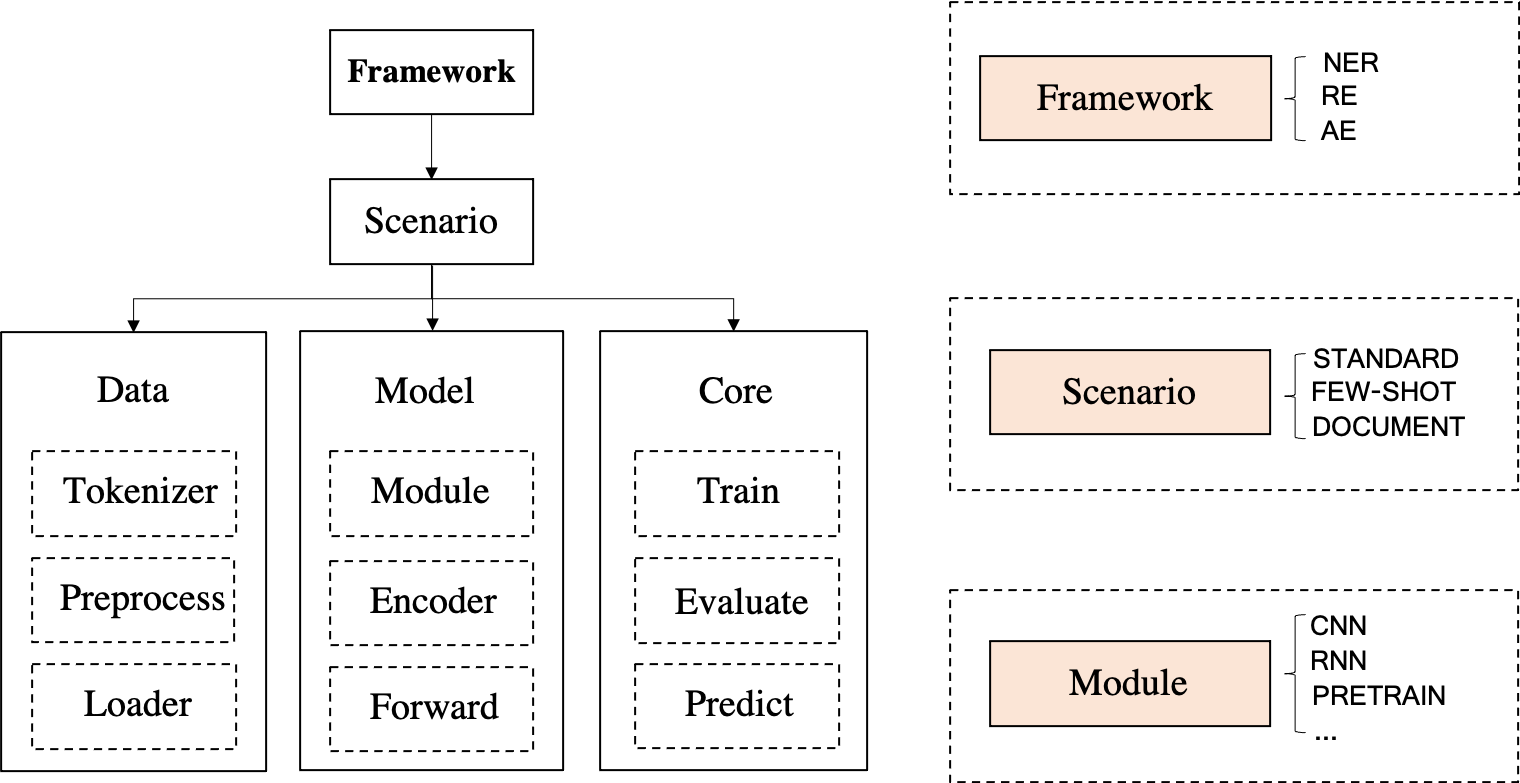
DeepKE
DeepKE 2.2.7
Anglais | 简体中文
Une boîte à outils d'extraction de connaissances basée sur l'apprentissage profond
pour la construction de graphes de connaissances
DeepKE est une boîte à outils d'extraction de connaissances pour la construction de graphes de connaissances prenant en charge les scénarios cnSchema , à faibles ressources , au niveau du document et multimodaux pour l'extraction d'entités , de relations et d'attributs . Nous fournissons des documents, une démo en ligne, du papier, des diapositives et une affiche pour les débutants.
\ dans les chemins de fichiers ;wisemodel ou modescape .Si vous rencontrez des problèmes lors de l'installation de DeepKE et DeepKE-LLM, veuillez consulter les conseils ou soumettre rapidement un problème, et nous vous aiderons à résoudre le problème !
April, 2024 Nous publions un nouveau modèle d'extraction d'informations bilingue (chinois et anglais) basé sur un schéma appelé OneKE, basé sur Chinese-Alpaca-2-13B.Feb, 2024 Nous publions un ensemble de données d'instructions d'extraction d'informations (IE) bilingues (chinois et anglais) de haute qualité à grande échelle (0,32 milliard de jetons) nommé IEPile, ainsi que deux modèles formés avec IEPile , baichuan2-13b-iepile-lora et lama2. -13b-iepile-lora.Sep 2023 un ensemble de données d'instructions d'extraction d'informations (IE) bilingue chinois anglais appelé InstructIE a été publié pour la tâche de construction de graphe de connaissances basée sur les instructions (KGC basé sur les instructions), comme détaillé ici.June, 2023 Nous mettons à jour DeepKE-LLM pour prendre en charge l'extraction de connaissances avec KnowLM, ChatGLM, les séries LLaMA, les séries GPT, etc.Apr, 2023 Nous avons ajouté de nouveaux modèles, notamment CP-NER(IJCAI'23), ASP(EMNLP'22), PRGC(ACL'21), PURE(NAACL'21), et fourni des capacités d'extraction d'événements (chinois et anglais), et offrait une compatibilité avec les versions supérieures des packages Python (par exemple, Transformers).Feb, 2023 Nous avons pris en charge l'utilisation de LLM (GPT-3) avec l'apprentissage en contexte (basé sur EasyInstruct) et la génération de données, ajouté un modèle NER W2NER (AAAI'22). Nov, 2022 Ajoutez des instructions d'annotation de données pour la reconnaissance d'entités et l'extraction de relations, l'étiquetage automatique des données faiblement supervisées (extraction d'entités et extraction de relations) et optimisez la formation multi-GPU.
Sept, 2022 L'article DeepKE : A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population a été accepté par le programme de démonstration du système EMNLP 2022.
Aug, 2022 Nous avons ajouté la prise en charge de l'augmentation des données (chinois, anglais) pour l'extraction de relations à faibles ressources.
June, 2022 Nous avons ajouté la prise en charge multimodale pour l'extraction d'entités et de relations.
May, 2022 Nous avons publié DeepKE-cnschema avec des modèles d'extraction de connaissances prêts à l'emploi.
Jan, 2022 Nous avons publié un article DeepKE : une boîte à outils d'extraction de connaissances basée sur l'apprentissage profond pour la population de la base de connaissances.
Dec, 2021 Nous avons ajouté dockerfile pour créer automatiquement l'environnement.
Nov, 2021 La démo de DeepKE, prenant en charge l'extraction en temps réel sans déploiement ni formation, a été publiée.
La documentation de DeepKE, contenant les détails de DeepKE tels que les codes sources et les ensembles de données, a été publiée.
Oct, 2021 pip install deepke
Les codes de deepke-v2.0 ont été publiés.
Aug, 2019 Les codes de deepke-v1.0 ont été publiés.
Aug, 2018 Le démarrage du projet DeepKE et les codes de deepke-v0.1 ont été publiés.
Il y a une démonstration de prédiction. Le fichier GIF est créé par Terminalizer. Obtenez le code. 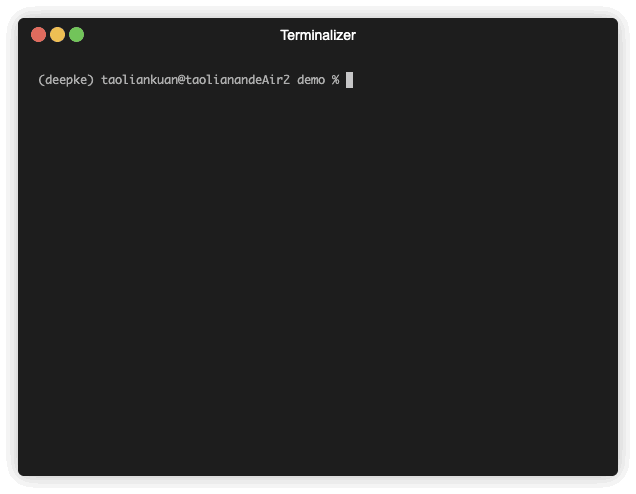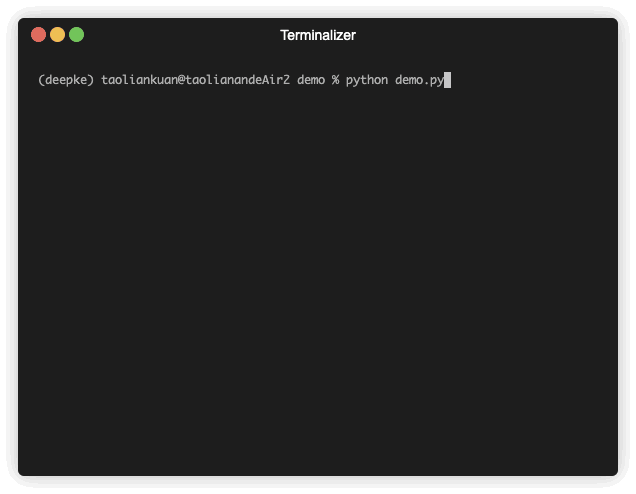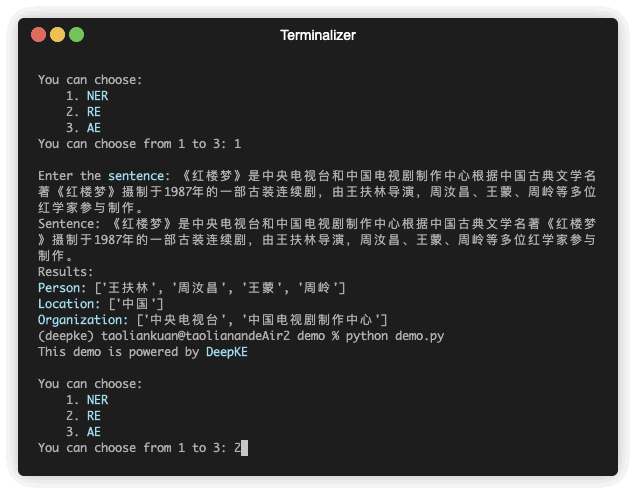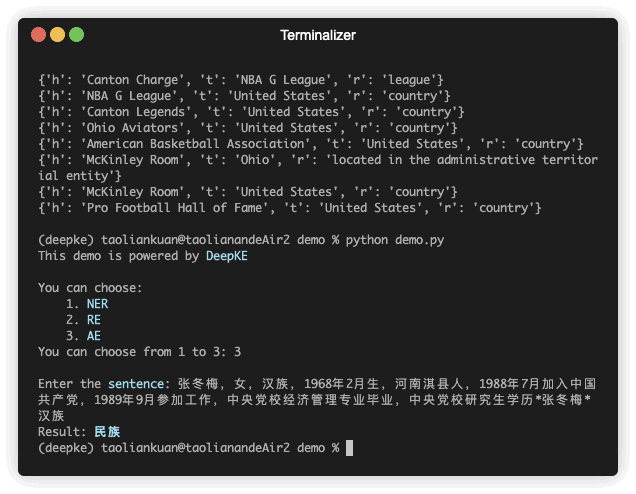
À l'ère des grands modèles, DeepKE-LLM utilise une toute nouvelle dépendance d'environnement.
conda create -n deepke-llm python=3.9
conda activate deepke-llm
cd example/llm
pip install -r requirements.txt
Veuillez noter que le fichier requirements.txt se trouve dans le dossier example/llm .
pip install deepke .Étape 1 Téléchargez le code de base
git clone --depth 1 https://github.com/zjunlp/DeepKE.git Étape 2 Créez un environnement virtuel à l'aide Anaconda et entrez-y.
conda create -n deepke python=3.8
conda activate deepkeInstaller DeepKE avec le code source
pip install -r requirements.txt
python setup.py install
python setup.py develop Installez DeepKE avec pip ( NON recommandé ! )
pip install deepkeÉtape 3 Entrez le répertoire des tâches
cd DeepKE/example/re/standardÉtape 4 Téléchargez l'ensemble de données ou suivez les instructions d'annotation pour obtenir des données
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gzDe nombreux types de formats de données sont pris en charge et les détails se trouvent dans chaque partie.
Formation Step5 (les paramètres de formation peuvent être modifiés dans le dossier conf )
Nous prenons en charge le réglage des paramètres visuels à l'aide de wandb .
python run.py Prédiction Étape 6 (les paramètres de prédiction peuvent être modifiés dans le dossier conf )
Modifiez le chemin du modèle entraîné dans predict.yaml . Le chemin absolu du modèle doit être utilisé, tel que xxx/checkpoints/2019-12-03_ 17-35-30/cnn_ epoch21.pth .
python predict.pyÉtape 1 Installez le client Docker
Installez Docker et démarrez le service Docker.
Étape 2 : Extrayez l'image Docker et exécutez le conteneur
docker pull zjunlp/deepke:latest
docker run -it zjunlp/deepke:latest /bin/bashLes étapes restantes sont les mêmes que celles de l'étape 3 et des suivantes dans Configuration manuelle de l'environnement .
python == 3,8
La reconnaissance des entités nommées cherche à localiser et à classer les entités nommées mentionnées dans un texte non structuré dans des catégories prédéfinies telles que les noms de personnes, les organisations, les emplacements, les organisations, etc.
Les données sont stockées dans des fichiers .txt . Quelques exemples comme suit (les utilisateurs peuvent étiqueter les données en fonction des outils Doccano, MarkTool, ou ils peuvent utiliser la supervision faible avec DeepKE pour obtenir automatiquement les données) :
| Phrase | Personne | Emplacement | Organisation |
|---|---|---|---|
| 本报北京9月4日讯记者杨涌报道:部分省区人民日报宣传发行工作座谈会9月3日在4日在京举行。 | 杨涌 | 北京 | 人民日报 |
| 《红楼梦》由王扶林导演,周汝昌、王蒙、周岭等多位专家参与制作。 | 王扶林,周汝昌,王蒙,周岭 | ||
| 秦始皇兵马俑位于陕西省西安市,是世界八大奇迹之一。 | 秦始皇 | 陕西省,西安市 |
Lisez le processus détaillé dans le README spécifique
STANDARD (entièrement supervisé)
Nous prenons en charge LLM et fournissons le modèle standard, DeepKE-cnSchema-NER, qui extraira les entités dans cnSchema sans formation.
Étape 1 Entrez DeepKE/example/ner/standard . Téléchargez l'ensemble de données.
wget 120.27.214.45/Data/ner/standard/data.tar.gz
tar -xzvf data.tar.gz Formation Étape 2
L'ensemble de données et les paramètres peuvent être personnalisés respectivement dans le dossier data et le dossier conf .
python run.pyPrédiction étape 3
python predict.pyQUELQUES PLANS
Étape 1 Entrez DeepKE/example/ner/few-shot . Téléchargez l'ensemble de données.
wget 120.27.214.45/Data/ner/few_shot/data.tar.gz
tar -xzvf data.tar.gz Étape 2 Formation dans un contexte à faibles ressources
Le répertoire où le modèle est chargé et enregistré et les paramètres de configuration peuvent être personnalisés dans le dossier conf .
python run.py +train=few_shot Les utilisateurs peuvent modifier load_path dans conf/train/few_shot.yaml pour utiliser le modèle chargé existant.
Étape 3 Ajoutez - predict à conf/config.yaml , modifiez loda_path comme chemin du modèle et write_path comme chemin où les résultats prédits sont enregistrés dans conf/predict.yaml , puis exécutez python predict.py
python predict.pyMULTIMODAL
Étape 1 Entrez DeepKE/example/ner/multimodal . Téléchargez l'ensemble de données.
wget 120.27.214.45/Data/ner/multimodal/data.tar.gz
tar -xzvf data.tar.gzNous utilisons les objets détectés par RCNN et les objets de mise à la terre visuelle à partir d'images originales comme informations visuelles locales, où RCNN via fast_rcnn et mise à la terre visuelle via onestage_grounding.
Étape 2 Formation dans le cadre multimodal
data et le dossier conf .load_path dans conf/train.yaml comme chemin où le modèle entraîné la dernière fois a été enregistré. Et les journaux de sauvegarde de chemin générés lors de la formation peuvent être personnalisés par log_dir . python run.pyPrédiction étape 3
python predict.pyL'extraction de relations est la tâche d'extraire les relations sémantiques entre entités à partir d'un texte non structuré.
Les données sont stockées dans des fichiers .csv . Quelques exemples comme suit (les utilisateurs peuvent étiqueter les données en fonction des outils Doccano, MarkTool, ou ils peuvent utiliser la supervision faible avec DeepKE pour obtenir automatiquement les données) :
| Phrase | Relation | Tête | Head_offset | Queue | Tail_offset |
|---|---|---|---|---|---|
| 《岳父也是爹》是王军执导的电视剧,由马恩然、范明主演。 | 导演 | 岳父也是爹 | 1 | 王军 | 8 |
| 《九玄珠》是在纵横中文网连载的一部小说,作者是龙马。 | 连载网站 | 九玄珠 | 1 | 纵横中文网 | 7 |
| 提起杭州的美景,西湖总是第一个映入脑海的词语。 | 所在城市 | 西湖 | 8 | 杭州 | 2 |
!REMARQUE : S'il existe plusieurs types d'entités pour une relation, les types d'entités peuvent être préfixés par la relation comme entrées.
Lisez le processus détaillé dans le README spécifique
STANDARD (entièrement supervisé)
Nous prenons en charge LLM et fournissons le modèle standard, DeepKE-cnSchema-RE, qui extraira les relations dans cnSchema sans formation.
Étape 1 Entrez le dossier DeepKE/example/re/standard . Téléchargez l'ensemble de données.
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz Formation Étape 2
L'ensemble de données et les paramètres peuvent être personnalisés respectivement dans le dossier data et le dossier conf .
python run.pyPrédiction étape 3
python predict.pyQUELQUES PLANS
Étape 1 Entrez DeepKE/example/re/few-shot . Téléchargez l'ensemble de données.
wget 120.27.214.45/Data/re/few_shot/data.tar.gz
tar -xzvf data.tar.gz Étape 2 Formation
data et le dossier conf .train_from_saved_model dans conf/train.yaml comme chemin où le modèle entraîné la dernière fois a été enregistré. Et les journaux de sauvegarde de chemin générés lors de la formation peuvent être personnalisés par log_dir . python run.pyPrédiction étape 3
python predict.py DOCUMENT
Étape 1 Entrez DeepKE/example/re/document . Téléchargez l'ensemble de données.
wget 120.27.214.45/Data/re/document/data.tar.gz
tar -xzvf data.tar.gz Formation Étape 2
data et le dossier conf .train_from_saved_model dans conf/train.yaml comme chemin où le modèle entraîné la dernière fois a été enregistré. Et les journaux de sauvegarde de chemin générés lors de la formation peuvent être personnalisés par log_dir . python run.pyPrédiction étape 3
python predict.pyMULTIMODAL
Étape 1 Entrez DeepKE/example/re/multimodal . Téléchargez l'ensemble de données.
wget 120.27.214.45/Data/re/multimodal/data.tar.gz
tar -xzvf data.tar.gzNous utilisons les objets détectés par RCNN et les objets de mise à la terre visuelle à partir d'images originales comme informations visuelles locales, où RCNN via fast_rcnn et mise à la terre visuelle via onestage_grounding.
Formation Étape 2
data et le dossier conf .load_path dans conf/train.yaml comme chemin où le modèle entraîné la dernière fois a été enregistré. Et les journaux de sauvegarde de chemin générés lors de la formation peuvent être personnalisés par log_dir . python run.pyPrédiction étape 3
python predict.pyL'extraction d'attributs consiste à extraire les attributs des entités dans un texte non structuré.
Les données sont stockées dans des fichiers .csv . Quelques exemples comme suit :
| Phrase | Att. | Ent | Ent_offset | Val | Val_offset |
|---|---|---|---|---|---|
| 张冬梅,女,汉族,1968年2月生,河南淇县人 | 民族 | 张冬梅 | 0 | 汉族 | 6 |
| 诸葛亮,字孔明,三国时期杰出的军事家、文学家、发明家。 | 朝代 | 诸葛亮 | 0 | 三国时期 | 8 |
| 10 janvier 2014 | 上映时间 | 黄金时代 | 19 | 10 janvier 2014 | 0 |
Lisez le processus détaillé dans le README spécifique
STANDARD (entièrement supervisé)
Étape 1 Entrez le dossier DeepKE/example/ae/standard . Téléchargez l'ensemble de données.
wget 120.27.214.45/Data/ae/standard/data.tar.gz
tar -xzvf data.tar.gz Formation Étape 2
L'ensemble de données et les paramètres peuvent être personnalisés respectivement dans le dossier data et le dossier conf .
python run.pyPrédiction étape 3
python predict.py.tsv , certaines instances sont les suivantes :| Phrase | Type d'événement | Déclenchement | Rôle | Argument | |
|---|---|---|---|---|---|
| 据《欧洲时报》报道,当地时间27日,法国巴黎卢浮宫博物馆员工因不满工作条件恶化而罢工,导致该博物馆也因此闭门谢客一天。 | 组织行为-罢工 | 罢工 | 罢工人员 | 法国巴黎卢浮宫博物馆员工 | |
| 时间 | 当地时间27日 | ||||
| 所属组织 | 法国巴黎卢浮宫博物馆 | ||||
| 中国外运2019年上半年归母净利润增长17%:收购了少数股东股权 | 财经/交易-出售/收购 | 收购 | 出售方 | 少数股东 | |
| 收购方 | 中国外运 | ||||
| 交易物 | 权 | ||||
| 美国亚特兰大航展13日发生一起表演机坠机事故,飞行员弹射出舱并安全着陆,事故没有造成人员伤亡。 | 灾害/意外-坠机 | 坠机 | 时间 | 13 heures | |
| 地点 | 美国亚特兰 | ||||
Lisez le processus détaillé dans le README spécifique
STANDARD (entièrement supervisé)
Étape 1 Entrez le dossier DeepKE/example/ee/standard . Téléchargez l'ensemble de données.
wget 120.27.214.45/Data/ee/DuEE.zip
unzip DuEE.zipÉtape 2 Formation
L'ensemble de données et les paramètres peuvent être personnalisés respectivement dans le dossier data et le dossier conf .
python run.pyPrédiction de l'étape 3
python predict.py 1. Using nearest mirror , THU en Chine, accélérera l'installation d' Anaconda ; Aliyun en Chine, accélérera pip install XXX .
2.Lorsque vous rencontrez ModuleNotFoundError: No module named 'past' , exécutez pip install future .
3. L'installation des modèles linguistiques pré-entraînés en ligne est lente. Il est recommandé de télécharger les modèles pré-entraînés avant utilisation et de les enregistrer dans le dossier pretrained . Lisez README.md dans chaque répertoire de tâches pour vérifier les exigences spécifiques relatives à l'enregistrement des modèles pré-entraînés.
4.L'ancienne version de DeepKE se trouve dans la branche deepke-v1.0. Les utilisateurs peuvent modifier la branche pour utiliser l'ancienne version. L'ancienne version a été totalement transférée vers l'extraction de relation standard (exemple/re/standard).
5.Si vous souhaitez modifier le code source, il est recommandé d'installer DeepKE avec les codes sources. Dans le cas contraire, la modification ne fonctionnera pas. Voir le problème
6. D’autres travaux d’extraction de connaissances à faibles ressources peuvent être trouvés dans Extraction de connaissances dans des scénarios à faibles ressources : enquête et perspective.
7.Assurez-vous que les versions exactes des exigences sont dans requirements.txt .
Dans la prochaine version, nous prévoyons de publier un LLM plus puissant pour KE.
En attendant, nous proposerons une maintenance à long terme pour corriger les bugs , résoudre les problèmes et répondre aux nouvelles demandes . Donc, si vous rencontrez des problèmes, veuillez nous en faire part.
Construction de graphes de connaissances efficaces en matière de données, 高效知识图谱构建 (Tutoriel sur CCKS 2022) [diapositives]
Construction de graphes de connaissances efficace et robuste (Tutoriel sur AACL-IJCNLP 2022) [diapositives]
Famille PromptKG : une galerie de travaux de recherche, de boîtes à outils et de listes papier liées à l'apprentissage rapide et à la KG [Ressources]
Extraction de connaissances dans des scénarios à faibles ressources : enquête et perspective [Enquête] [Paper-list]
Doccano、MarkTool、LabelStudio : boîtes à outils d'annotation de données
LambdaKG : une bibliothèque et un benchmark pour les intégrations KG basées sur PLM
EasyInstruct : un framework facile à utiliser pour instruire de grands modèles de langage
Matériel de lecture :
Construction de graphes de connaissances efficaces en matière de données, 高效知识图谱构建 (Tutoriel sur CCKS 2022) [diapositives]
Construction de graphes de connaissances efficace et robuste (Tutoriel sur AACL-IJCNLP 2022) [diapositives]
Famille PromptKG : une galerie de travaux de recherche, de boîtes à outils et de listes papier liées à l'apprentissage rapide et à la KG [Ressources]
Extraction de connaissances dans des scénarios à faibles ressources : enquête et perspective [Enquête] [Paper-list]
Boîte à outils connexe :
Doccano、MarkTool、LabelStudio : boîtes à outils d'annotation de données
LambdaKG : une bibliothèque et un benchmark pour les intégrations KG basées sur PLM
EasyInstruct : un framework facile à utiliser pour instruire de grands modèles de langage
Veuillez citer notre article si vous utilisez DeepKE dans votre travail
@inproceedings { EMNLP2022_Demo_DeepKE ,
author = { Ningyu Zhang and
Xin Xu and
Liankuan Tao and
Haiyang Yu and
Hongbin Ye and
Shuofei Qiao and
Xin Xie and
Xiang Chen and
Zhoubo Li and
Lei Li } ,
editor = { Wanxiang Che and
Ekaterina Shutova } ,
title = { DeepKE: {A} Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population } ,
booktitle = { {EMNLP} (Demos) } ,
pages = { 98--108 } ,
publisher = { Association for Computational Linguistics } ,
year = { 2022 } ,
url = { https://aclanthology.org/2022.emnlp-demos.10 }
}Ningyu Zhang, Haofen Wang, Fei Huang, Feiyu Xiong, Liankuan Tao, Xin Xu, Honghao Gui, Zhenru Zhang, Chuanqi Tan, Qiang Chen, Xiaohan Wang, Zekun Xi, Xinrong Li, Haiyang Yu, Hongbin Ye, Shuofei Qiao, Peng Wang , Yuqi Zhu, Xin Xie, Xiang Chen, Zhoubo Li, Lei Li, Xiaozhuan Liang, Yunzhi Yao, Jing Chen, Yuqi Zhu, Shumin Deng, Wen Zhang, Guozhou Zheng, Huajun Chen
Contributeurs de la communauté : thredreams, eltociear, Ziwen Xu, Rui Huang, Xiaolong Weng


