
Implémentation officielle PyTorch d'OpenStreetView-5M : les nombreuses routes vers la géolocalisation visuelle mondiale.
Premiers auteurs : Guillaume Astruc, Nicolas Dufour, Ioannis Siglidis
Deuxièmes auteurs : Constantin Aronssohn, Nacim Bouia, Stephanie Fu, Romain Loiseau, Van Nguyen Nguyen, Charles Raude, Elliot Vincent, Lintao XU, Hongyu Zhou
Dernier auteur : Loïc Landrieu
Institut de recherche : Imagine, LIGM, Ecole des Ponts, Univ Gustave Eiffel, CNRS, Marne-la-Vallée, France
OpenStreetView-5M est le premier benchmark de géolocalisation ouverte à grande échelle d'images StreetView.
Pour avoir une idée de la difficulté du benchmark, vous pouvez jouer à notre démo.
Notre ensemble de données a été utilisé dans un benchmark approfondi dont nous fournissons le meilleur modèle.
Pour plus de détails et de résultats, veuillez consulter notre page article et projet.
OpenStreetView-5M est hébergé sur huggingface/datasets/osv5m/osv5m. Pour le télécharger et l'extraire, exécutez :
python scripts/download-dataset.pyPour différentes manières d'importer l'ensemble de données, voir DATASET.md
Notre meilleur modèle sur OSV-5M peut également être trouvé sur Huggingface.
from PIL import Image
from models . huggingface import Geolocalizer
geolocalizer = Geolocalizer . from_pretrained ( 'osv5m/baseline' )
img = Image . open ( '.media/examples/img1.jpeg' )
x = geolocalizer . transform ( img ). unsqueeze ( 0 ) # transform the image using our dedicated transformer
gps = geolocalizer ( x ) # B, 2 (lat, lon - tensor in rad)Pour reproduire les résultats du modèle sur huggingface, exécutez :
python evaluation.py exp=eval_best_model dataset.global_batch_size=1024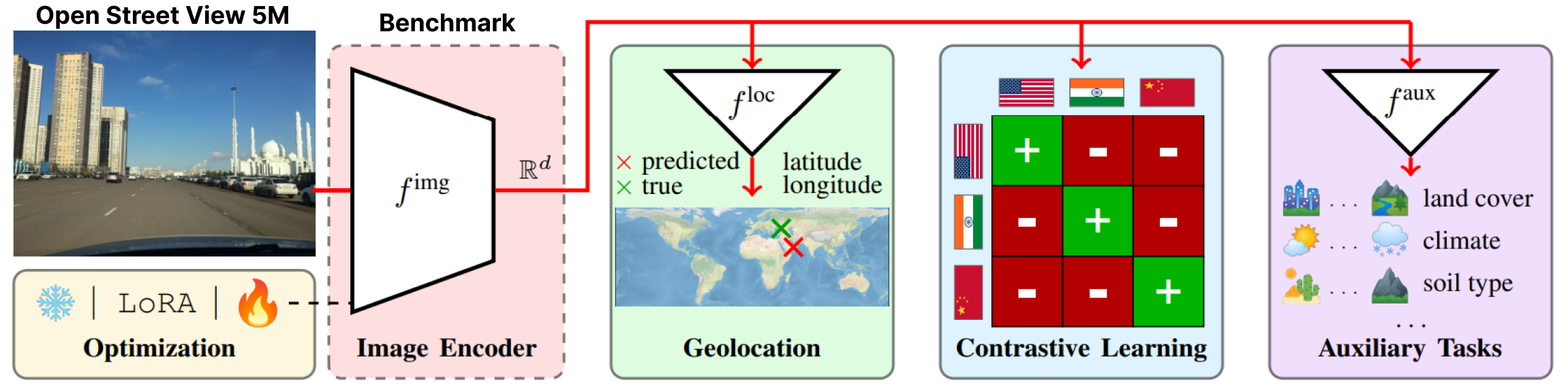 Pour reproduire toutes les expériences de notre article, nous proposons des scripts dédiés dans
Pour reproduire toutes les expériences de notre article, nous proposons des scripts dédiés dans scripts/experiments .
Pour installer notre environnement conda, exécutez :
conda env create -f environment.yaml
conda activate osv5mPour exécuter la plupart des méthodes, vous devez d'abord précalculer les QuadTrees (environ 10 minutes) :
python scripts/preprocessing/preprocess.py data_dir=datasets do_split=1000 # You will need to run this code with other splitting/depth arguments if you want to use different quadtree argumentsUtilisez le dossier configs/exp pour sélectionner l'expérience souhaitée. N'hésitez pas à l'explorer. Tous les modèles évalués dans le document ont un fichier de configuration dédié
# Using more workers in the dataloader
computer.num_workers=20
# Change number of devices available
computer.devices=1
# Change batch_size distributed to all devices
dataset.global_batch_size=2
# Changing mode train or eval, default is train
mode=eval
# All these parameters and more can be changed from the config file!
# train best model
python train.py exp=best_model computer.devices=1 computer.num_workers=16 dataset.global_batch_size=2 @article { osv5m ,
title = { {OpenStreetView-5M}: {T}he Many Roads to Global Visual Geolocation } ,
author = { Astruc, Guillaume and Dufour, Nicolas and Siglidis, Ioannis
and Aronssohn, Constantin and Bouia, Nacim and Fu, Stephanie and Loiseau, Romain
and Nguyen, Van Nguyen and Raude, Charles and Vincent, Elliot and Xu, Lintao
and Zhou, Hongyu and Landrieu, Loic } ,
journal = { CVPR } ,
year = { 2024 } ,
}

