
Xuan Ju 1* , Yiming Gao 1* , Zhaoyang Zhang 1*# , Ziyang Yuan 1 , Xintao Wang 1 , Ailing Zeng, Yu Xiong, Qiang Xu, Ying Shan 1
1 ARC Lab, Tencent PCG 2 Université chinoise de Hong Kong * Contribution égale # Chef de projet
Les ensembles de données vidéo jouent un rôle crucial dans la génération de vidéos telles que Sora. Cependant, les ensembles de données texte-vidéo existants ne parviennent souvent pas à gérer de longues séquences vidéo et à capturer des transitions de prise de vue . Pour remédier à ces limitations, nous introduisons MiraData , un ensemble de données vidéo conçu spécifiquement pour les tâches de génération de vidéos longues. De plus, pour mieux évaluer la cohérence temporelle et l'intensité du mouvement dans la génération vidéo, nous introduisons MiraBench , qui améliore les références existantes en ajoutant une cohérence 3D et des mesures de force de mouvement basées sur le suivi. Vous pouvez trouver plus de détails dans notre document de recherche.
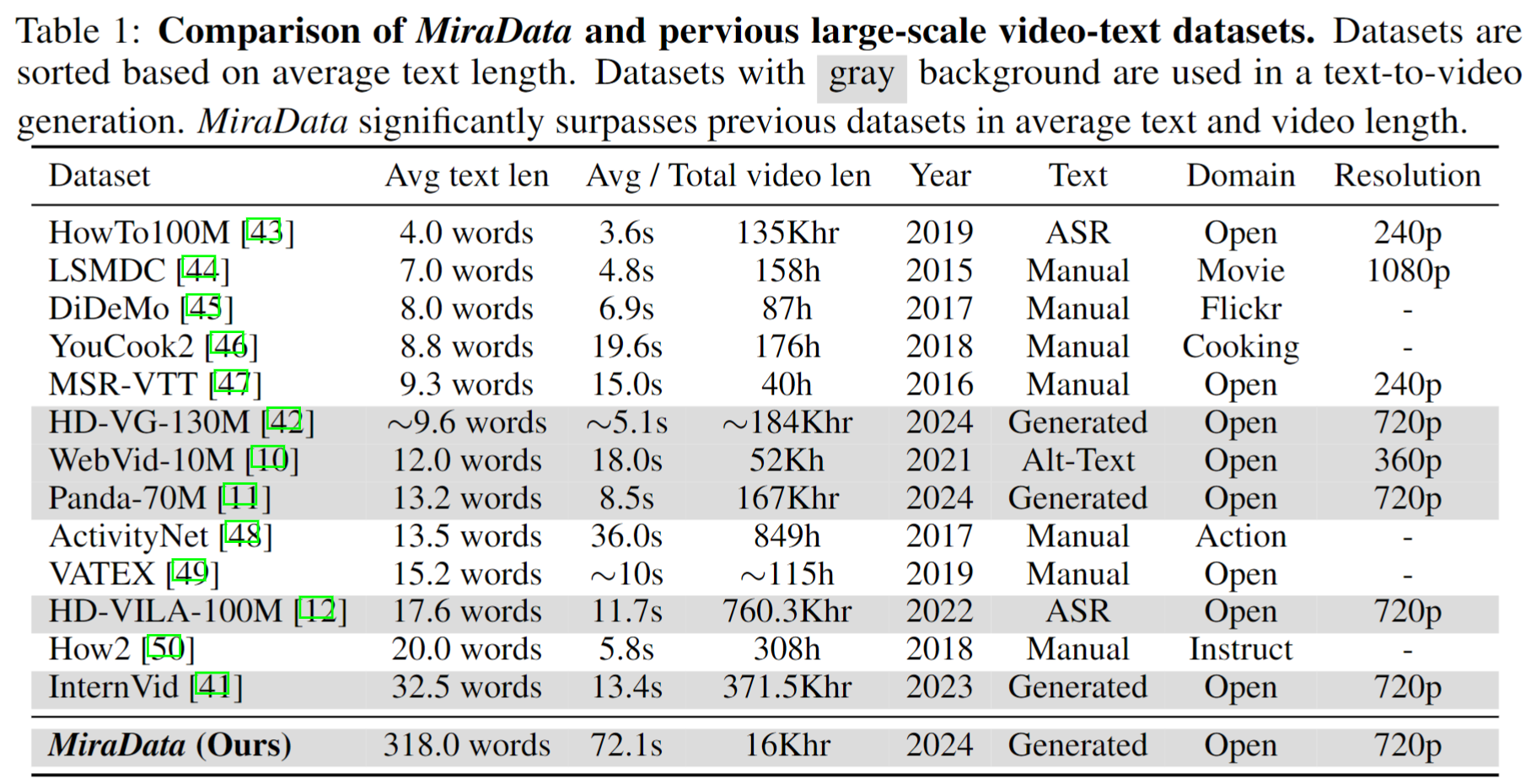
Nous publions quatre versions de MiraData, contenant des données 330K, 93K, 42K et 9K.
Le fichier méta de cette version de MiraData est fourni dans Google Drive et HuggingFace Dataset. De plus, pour une compréhension meilleure et plus rapide de la composition de nos métafichiers, nous échantillonnons au hasard un ensemble de 100 clips vidéo, accessibles ici. Le fichier méta contient les informations d'index suivantes :
{download_id}.{clip_id}Pour télécharger les vidéos et les diviser en clips, commencez par télécharger les métafichiers depuis Google Drive ou HuggingFace Dataset. Une fois que vous disposez des métafichiers, vous pouvez utiliser les scripts suivants pour télécharger les exemples vidéo :
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
Nous supprimerons les échantillons vidéo de notre ensemble de données / Github / page Web du projet aussi longtemps que vous en aurez besoin. Veuillez nous contacter pour la demande.
Pour collecter les MiraData, nous sélectionnons d'abord manuellement les chaînes YouTube dans différents scénarios et incluons des vidéos de HD-VILA-100M, Videovo, Pixabay et Pexels. Ensuite, toutes les vidéos des chaînes correspondantes sont téléchargées et divisées à l'aide de PySceneDetect. Nous avons ensuite utilisé plusieurs modèles pour assembler les courts clips et filtrer les vidéos de mauvaise qualité. Suite à cela, nous avons sélectionné des clips vidéo de longues durées. Enfin, nous avons sous-titré tous les clips vidéo en utilisant GPT-4V.

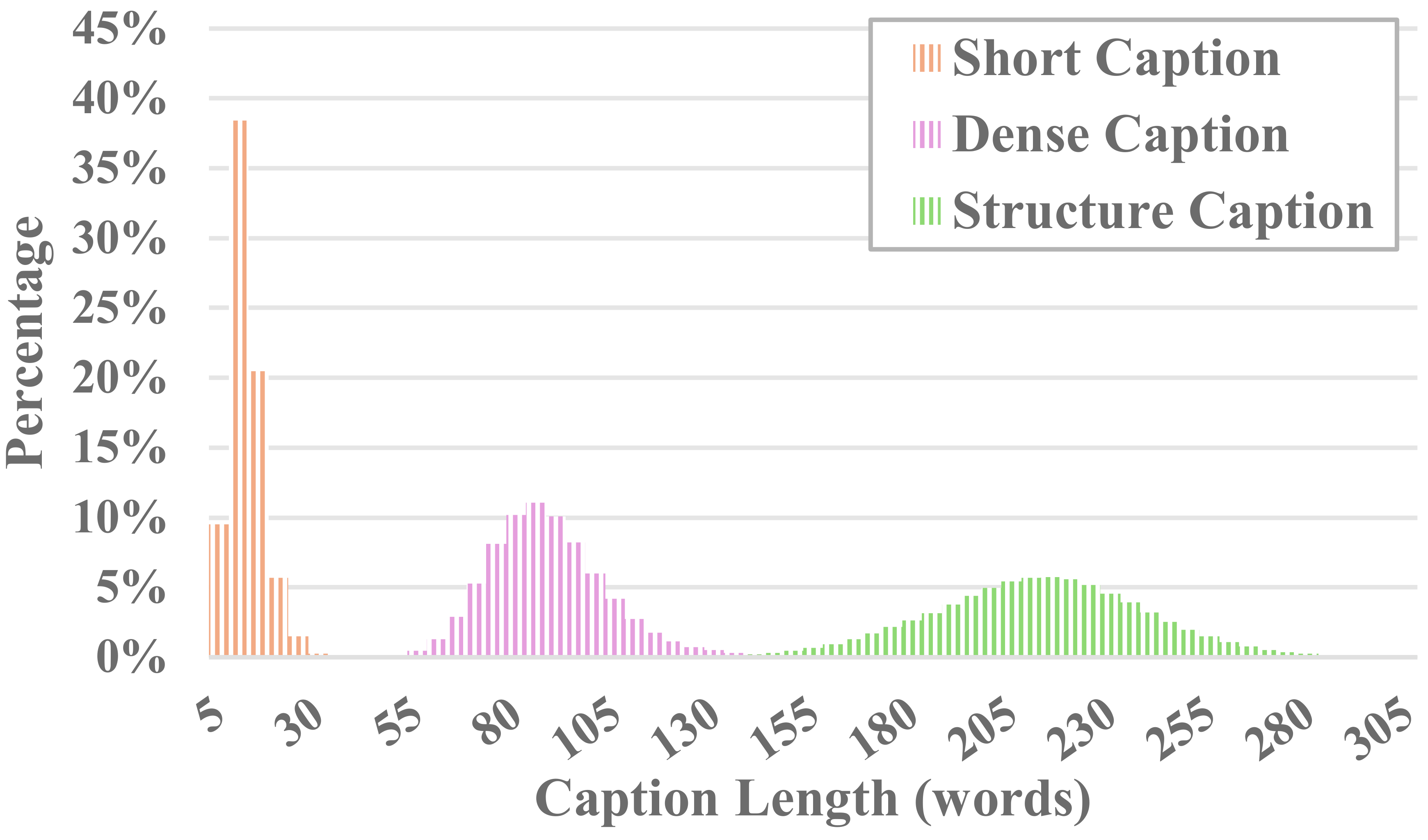
Chaque vidéo dans MiraData est accompagnée de sous-titres structurés. Ces légendes fournissent des descriptions détaillées sous diverses perspectives, renforçant ainsi la richesse de l'ensemble de données.
Six types de sous-titres
Nous avons testé les méthodes LLM visuelles open source existantes et GPT-4V, et avons constaté que les légendes de GPT-4V montrent une meilleure précision et cohérence dans la compréhension sémantique en termes de séquence temporelle.
Afin d'équilibrer les coûts d'annotation et la précision des sous-titres, nous échantillonnons uniformément 8 images pour chaque vidéo et les organisons dans une grille 2x4 d'une grande image. Ensuite, nous utilisons le modèle de légende de Panda-70M pour annoter chaque vidéo avec une légende d'une phrase, qui sert d'indice pour le contenu principal, et la saisissons dans notre invite affinée. En transmettant l'invite affinée et une grande image 2x4 à GPT-4V, nous pouvons produire efficacement des sous-titres pour plusieurs dimensions en un seul cycle de conversation. Le contenu spécifique de l'invite peut être trouvé dans caption_gpt4v.py, et nous invitons tout le monde à contribuer aux données texte-vidéo de meilleure qualité. ?

Pour évaluer la génération de vidéos longues, nous concevons 17 métriques d'évaluation dans MiraBench sous 6 perspectives, notamment la cohérence temporelle, la force du mouvement temporel, la cohérence 3D, la qualité visuelle, l'alignement texte-vidéo et la cohérence de la distribution. Ces mesures englobent la plupart des normes d'évaluation courantes utilisées dans les modèles de génération vidéo précédents et les références texte-vidéo.
Pour évaluer les vidéos générées, veuillez d'abord configurer l'environnement Python via :
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
Ensuite, exécutez l'évaluation via :
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
Vous pouvez suivre l'exemple dans data/evaluation_example pour évaluer vos propres vidéos générées.
Veuillez consulter LICENCE.
Si vous trouvez ce projet utile pour votre recherche, veuillez citer notre article. ?
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
Pour toute demande de renseignements, veuillez envoyer un e-mail [email protected] .
MiraData est sous licence GPL-v3 et est pris en charge pour un usage commercial. Si vous avez besoin d'une licence commerciale pour MiraData, n'hésitez pas à nous contacter.


