storm
v1.0.0 & EMNLP 2024 Paper Accepted!
| Aperçu de la recherche | Papier TEMPÊTE | Papier Co-STORM | Site Web |
Dernières nouvelles
[2024/09] La base de code Co-STORM est maintenant publiée et intégrée au package Python knowledge-storm v1.0.0. Exécutez pip install knowledge-storm --upgrade pour le vérifier.
[2024/09] Nous introduisons le STORM collaboratif (Co-STORM) pour soutenir la curation collaborative des connaissances humain-IA ! Co-STORM Paper a été accepté à la conférence principale EMNLP 2024.
[2024/07] Vous pouvez désormais installer notre package avec pip install knowledge-storm !
[2024/07] Nous ajoutons VectorRM pour prendre en charge la base sur les documents fournis par les utilisateurs, complétant ainsi la prise en charge existante des moteurs de recherche ( YouRM , BingSearch ). (consultez le numéro 58)
[2024/07] Nous publions demo light pour les développeurs, une interface utilisateur minimale construite avec un framework simplifié en Python, pratique pour le développement local et l'hébergement de démos (checkout #54)
[2024/06] Nous présenterons STORM à la NAACL 2024 ! Retrouvez-nous à la Poster Session 2 le 17 juin ou consultez notre matériel de présentation.
[2024/05] Nous ajoutons la prise en charge de Bing Search dans rm.py. Testez STORM avec GPT-4o - nous configurons maintenant la partie génération d'articles dans notre démo en utilisant le modèle GPT-4o .
[2024/04] Nous publions une version refactorisée de la base de code STORM ! Nous définissons l'interface pour le pipeline STORM et réimplémentons STORM-wiki (consultez src/storm_wiki ) pour montrer comment instancier le pipeline. Nous fournissons une API pour prendre en charge la personnalisation de différents modèles de langage et l'intégration de récupération/recherche.
Bien que le système ne puisse pas produire des articles prêts à être publiés qui nécessitent souvent un nombre important de modifications, les éditeurs expérimentés de Wikipédia l'ont trouvé utile dans leur phase de pré-écriture.
Plus de 70 000 personnes ont essayé notre aperçu de recherche en direct. Essayez-le pour voir comment STORM peut vous aider dans votre parcours d'exploration des connaissances et veuillez nous faire part de vos commentaires pour nous aider à améliorer le système !
STORM décompose la génération d'articles longs avec des citations en deux étapes :
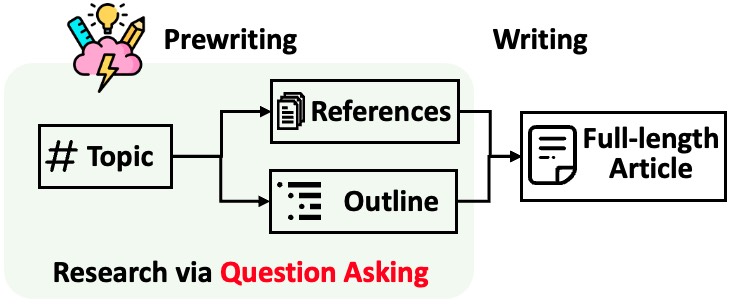
STORM identifie le cœur de l'automatisation du processus de recherche comme étant la proposition automatique de bonnes questions à poser. Inviter directement le modèle linguistique à poser des questions ne fonctionne pas bien. Pour améliorer la profondeur et l'étendue des questions, STORM adopte deux stratégies :
Co-STORM propose un protocole de discours collaboratif qui met en œuvre une politique de gestion du tour pour soutenir une collaboration fluide entre
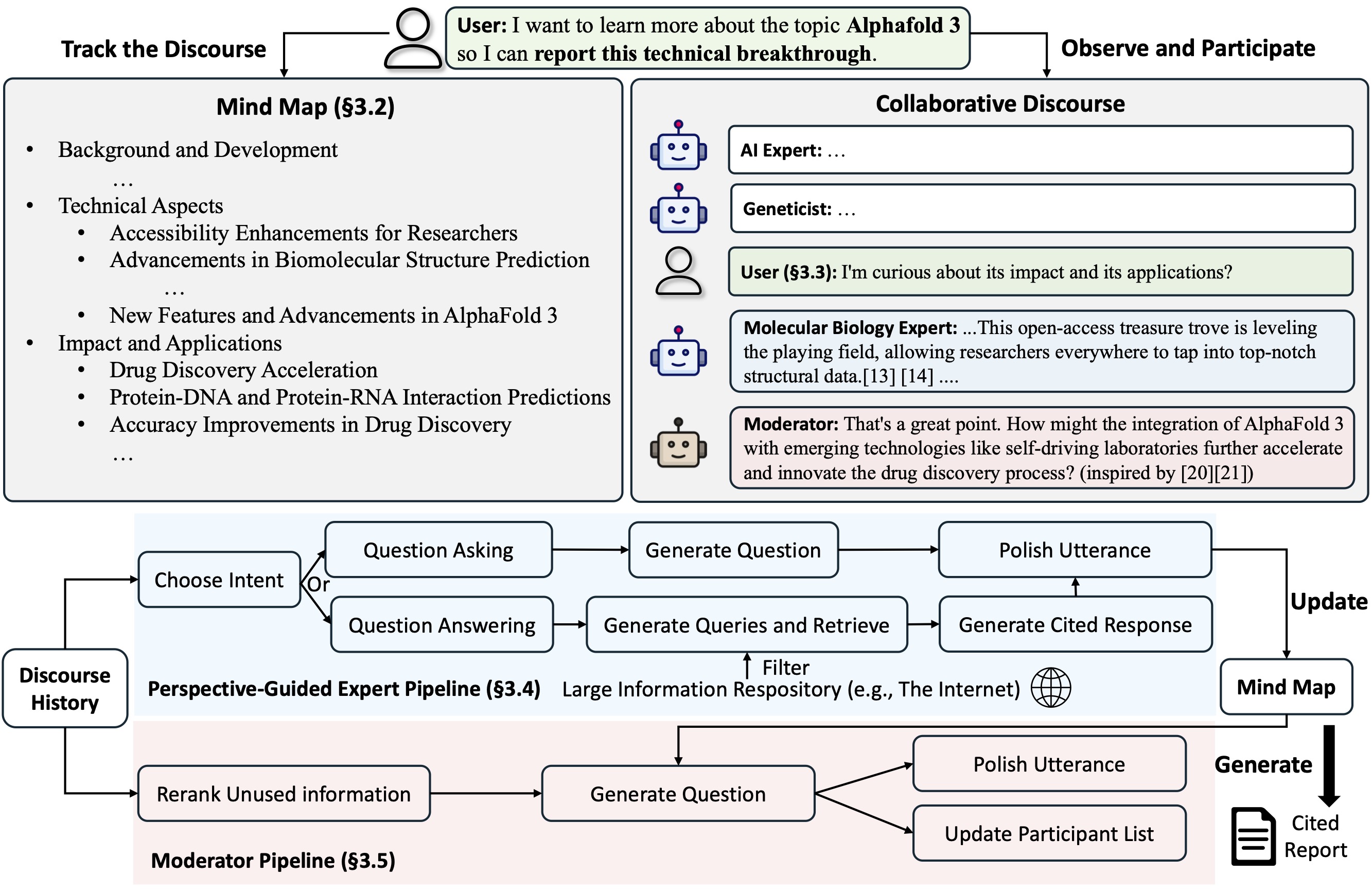
Co-STORM maintient également une carte mentale dynamique mise à jour, qui organise les informations collectées dans une structure conceptuelle hiérarchique, visant à construire un espace conceptuel partagé entre l'utilisateur humain et le système . Il a été prouvé que la carte mentale aide à réduire la charge mentale lorsque le discours est long et approfondi.
STORM et Co-STORM sont implémentés de manière hautement modulaire à l'aide de dspy.
Pour installer la bibliothèque Knowledge Storm, utilisez pip install knowledge-storm .
Vous pouvez également installer le code source qui permet de modifier directement le comportement du moteur STORM.
Clonez le dépôt git.
git clone https://github.com/stanford-oval/storm.git
cd stormInstallez les packages requis.
conda create -n storm python=3.11
conda activate storm
pip install -r requirements.txtActuellement, notre package prend en charge :
OpenAIModel , AzureOpenAIModel , ClaudeModel , VLLMClient , TGIClient , TogetherClient , OllamaClient , GoogleModel , DeepSeekModel , GroqModel en tant que composants de modèle de langageYouRM , BingSearch , VectorRM , SerperRM , BraveRM , SearXNG , DuckDuckGoSearchRM , TavilySearchRM , GoogleSearch et AzureAISearch en tant que composants du module de récupération? Les PR pour l'intégration de plus de modèles de langage dans knowledge_storm/lm.py et de moteurs de recherche/récupérateurs dans knowledge_storm/rm.py sont très appréciés !
STORM et Co-STORM fonctionnent tous deux dans la couche de conservation des informations, vous devez configurer le module de récupération d'informations et le module de modèle de langage pour créer respectivement leurs classes Runner .
Le moteur de conservation des connaissances STORM est défini comme une simple classe Python STORMWikiRunner . Voici un exemple d'utilisation du moteur de recherche You.com et des modèles OpenAI.
import os
from knowledge_storm import STORMWikiRunnerArguments , STORMWikiRunner , STORMWikiLMConfigs
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . rm import YouRM
lm_configs = STORMWikiLMConfigs ()
openai_kwargs = {
'api_key' : os . getenv ( "OPENAI_API_KEY" ),
'temperature' : 1.0 ,
'top_p' : 0.9 ,
}
# STORM is a LM system so different components can be powered by different models to reach a good balance between cost and quality.
# For a good practice, choose a cheaper/faster model for `conv_simulator_lm` which is used to split queries, synthesize answers in the conversation.
# Choose a more powerful model for `article_gen_lm` to generate verifiable text with citations.
gpt_35 = OpenAIModel ( model = 'gpt-3.5-turbo' , max_tokens = 500 , ** openai_kwargs )
gpt_4 = OpenAIModel ( model = 'gpt-4o' , max_tokens = 3000 , ** openai_kwargs )
lm_configs . set_conv_simulator_lm ( gpt_35 )
lm_configs . set_question_asker_lm ( gpt_35 )
lm_configs . set_outline_gen_lm ( gpt_4 )
lm_configs . set_article_gen_lm ( gpt_4 )
lm_configs . set_article_polish_lm ( gpt_4 )
# Check out the STORMWikiRunnerArguments class for more configurations.
engine_args = STORMWikiRunnerArguments (...)
rm = YouRM ( ydc_api_key = os . getenv ( 'YDC_API_KEY' ), k = engine_args . search_top_k )
runner = STORMWikiRunner ( engine_args , lm_configs , rm ) L'instance STORMWikiRunner peut être évoquée avec la simple méthode run :
topic = input ( 'Topic: ' )
runner . run (
topic = topic ,
do_research = True ,
do_generate_outline = True ,
do_generate_article = True ,
do_polish_article = True ,
)
runner . post_run ()
runner . summary ()do_research : si True, simulez des conversations avec des perspectives différentes pour collecter des informations sur le sujet ; sinon, chargez les résultats.do_generate_outline : si True, génère un plan pour le sujet ; sinon, chargez les résultats.do_generate_article : si True, génère un article pour le sujet basé sur le plan et les informations collectées ; sinon, chargez les résultats.do_polish_article : si True, peaufine l'article en ajoutant une section de résumé et (éventuellement) en supprimant le contenu en double ; sinon, chargez les résultats. Le moteur de conservation des connaissances Co-STORM est défini comme une simple classe Python CoStormRunner . Voici un exemple d'utilisation du moteur de recherche Bing et des modèles OpenAI.
from knowledge_storm . collaborative_storm . engine import CollaborativeStormLMConfigs , RunnerArgument , CoStormRunner
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . logging_wrapper import LoggingWrapper
from knowledge_storm . rm import BingSearch
# Co-STORM adopts the same multi LM system paradigm as STORM
lm_config : CollaborativeStormLMConfigs = CollaborativeStormLMConfigs ()
openai_kwargs = {
"api_key" : os . getenv ( "OPENAI_API_KEY" ),
"api_provider" : "openai" ,
"temperature" : 1.0 ,
"top_p" : 0.9 ,
"api_base" : None ,
}
question_answering_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
discourse_manage_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
utterance_polishing_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 2000 , ** openai_kwargs )
warmstart_outline_gen_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
question_asking_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 300 , ** openai_kwargs )
knowledge_base_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
lm_config . set_question_answering_lm ( question_answering_lm )
lm_config . set_discourse_manage_lm ( discourse_manage_lm )
lm_config . set_utterance_polishing_lm ( utterance_polishing_lm )
lm_config . set_warmstart_outline_gen_lm ( warmstart_outline_gen_lm )
lm_config . set_question_asking_lm ( question_asking_lm )
lm_config . set_knowledge_base_lm ( knowledge_base_lm )
# Check out the Co-STORM's RunnerArguments class for more configurations.
topic = input ( 'Topic: ' )
runner_argument = RunnerArgument ( topic = topic , ...)
logging_wrapper = LoggingWrapper ( lm_config )
bing_rm = BingSearch ( bing_search_api_key = os . environ . get ( "BING_SEARCH_API_KEY" ),
k = runner_argument . retrieve_top_k )
costorm_runner = CoStormRunner ( lm_config = lm_config ,
runner_argument = runner_argument ,
logging_wrapper = logging_wrapper ,
rm = bing_rm ) L'instance CoStormRunner peut être évoquée avec les méthodes warmstart() et step(...) .
# Warm start the system to build shared conceptual space between Co-STORM and users
costorm_runner . warm_start ()
# Step through the collaborative discourse
# Run either of the code snippets below in any order, as many times as you'd like
# To observe the conversation:
conv_turn = costorm_runner . step ()
# To inject your utterance to actively steer the conversation:
costorm_runner . step ( user_utterance = "YOUR UTTERANCE HERE" )
# Generate report based on the collaborative discourse
costorm_runner . knowledge_base . reorganize ()
article = costorm_runner . generate_report ()
print ( article )Nous fournissons des scripts dans notre dossier d'exemples comme un démarrage rapide pour exécuter STORM et Co-STORM avec différentes configurations.
Nous vous suggérons d'utiliser secrets.toml pour configurer les clés API. Créez un fichier secrets.toml sous le répertoire racine et ajoutez le contenu suivant :
# Set up OpenAI API key.
OPENAI_API_KEY= " your_openai_api_key "
# If you are using the API service provided by OpenAI, include the following line:
OPENAI_API_TYPE= " openai "
# If you are using the API service provided by Microsoft Azure, include the following lines:
OPENAI_API_TYPE= " azure "
AZURE_API_BASE= " your_azure_api_base_url "
AZURE_API_VERSION= " your_azure_api_version "
# Set up You.com search API key.
YDC_API_KEY= " your_youcom_api_key " Pour exécuter STORM avec des modèles de la famille gpt avec des configurations par défaut :
Exécutez la commande suivante.
python examples/storm_examples/run_storm_wiki_gpt.py
--output-dir $OUTPUT_DIR
--retriever you
--do-research
--do-generate-outline
--do-generate-article
--do-polish-articlePour exécuter STORM en utilisant vos modèles de langage préférés ou en vous appuyant sur votre propre corpus : consultez examples/storm_examples/README.md.
Pour exécuter Co-STORM avec des modèles de la famille gpt avec des configurations par défaut,
BING_SEARCH_API_KEY="xxx" et ENCODER_API_TYPE="xxx" à secrets.tomlpython examples/costorm_examples/run_costorm_gpt.py
--output-dir $OUTPUT_DIR
--retriever bingSi vous avez installé le code source, vous pouvez personnaliser STORM en fonction de votre propre cas d'utilisation. Le moteur STORM se compose de 4 modules :
L'interface de chaque module est définie dans knowledge_storm/interface.py , tandis que leurs implémentations sont instanciées dans knowledge_storm/storm_wiki/modules/* . Ces modules peuvent être personnalisés en fonction de vos besoins spécifiques (par exemple, générer des sections sous forme de puces au lieu de paragraphes complets).
Si vous avez installé le code source, vous pouvez personnaliser Co-STORM en fonction de votre propre cas d'utilisation
knowledge_storm/interface.py , tandis que son implémentation est instanciée dans knowledge_storm/collaborative_storm/modules/co_storm_agents.py . Différentes politiques d'agent LLM peuvent être personnalisées.DiscourseManager dans knowledge_storm/collaborative_storm/engine.py . Il peut être personnalisé et encore amélioré. Pour faciliter l'étude de la curation automatique des connaissances et de la recherche d'informations complexes, notre projet publie les ensembles de données suivants :
L'ensemble de données FreshWiki est une collection de 100 articles Wikipédia de haute qualité se concentrant sur les pages les plus éditées de février 2022 à septembre 2023. Voir la section 2.1 de l'article STORM pour plus de détails.
Vous pouvez télécharger l’ensemble de données directement depuis huggingface. Pour atténuer le problème de contamination des données, nous archivons le code source du pipeline de construction de données qui peut être répété à des dates ultérieures.
Pour étudier les intérêts des utilisateurs dans des tâches complexes de recherche d'informations dans la nature, nous avons utilisé les données collectées à partir de l'aperçu de la recherche sur le Web pour créer l'ensemble de données WildSeek. Nous avons sous-échantillonné les données pour garantir la diversité des sujets et la qualité des données. Chaque point de données est une paire comprenant un sujet et l'objectif de l'utilisateur pour effectuer une recherche approfondie sur le sujet. Pour plus de détails, veuillez vous référer à la section 2.2 et à l'annexe A du document Co-STORM.
L'ensemble de données WildSeek est disponible ici.
Pour les expériences sur papier STORM, veuillez passer à la branche NAACL-2024-code-backup ici.
Pour les expériences papier Co-STORM, veuillez passer à la branche EMNLP-2024-code-backup (espace réservé pour l'instant, sera bientôt mis à jour).
Notre équipe travaille activement sur :
Si vous avez des questions ou des suggestions, n'hésitez pas à ouvrir un problème ou une pull request. Nous apprécions les contributions pour améliorer le système et la base de code !
Personne à contacter : Yijia Shao et Yucheng Jiang
Nous tenons à remercier Wikipédia pour son excellent contenu open source. L'ensemble de données FreshWiki provient de Wikipédia, sous licence Creative Commons Attribution-ShareAlike (CC BY-SA).
Nous sommes très reconnaissants à Michelle Lam pour la conception du logo de ce projet et à Dekun Ma pour avoir dirigé le développement de l'interface utilisateur.
Veuillez citer notre article si vous utilisez ce code ou une partie de celui-ci dans votre travail :
@misc { jiang2024unknownunknowns ,
title = { Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations } ,
author = { Yucheng Jiang and Yijia Shao and Dekun Ma and Sina J. Semnani and Monica S. Lam } ,
year = { 2024 } ,
eprint = { 2408.15232 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.15232 } ,
}
@inproceedings { shao2024assisting ,
title = { {Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models} } ,
author = { Yijia Shao and Yucheng Jiang and Theodore A. Kanell and Peter Xu and Omar Khattab and Monica S. Lam } ,
year = { 2024 } ,
booktitle = { Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) }
}

