bulk
1.0.0
Bulk est un outil de développement rapide permettant d'appliquer des étiquettes groupées. Étant donné un ensemble de données préparé avec des intégrations 2D, il peut générer une interface qui vous permet d'ajouter rapidement des annotations volumineuses, quoique moins précises.
python -m pip install --upgrade pip
python -m pip install bulk
L’avenir du vrac est de proposer des widgets qui pourront vous aider dans le notebook. Pour le moment, BaseTextExplorer est le principal widget pris en charge. Étant donné certaines données prétraitées, vous pouvez utiliser l'explorateur pour parcourir un UMAP 2D d'incorporations de texte.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
umap = UMAP ()
text_emb_pipeline = make_pipeline (
enc , umap
)
# Load sentences
sentences = list ( pd . read_csv ( "tests/data/text.csv" )[ 'text' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]Pour utiliser le widget, il vous suffit d'exécuter ceci :
from bulk . widgets import BaseTextExplorer
widget = BaseTextExplorer ( df )
widget . show ()Cela nous permettra d'explorer rapidement les clusters qui apparaissent dans nos données. Vous pouvez maintenir le curseur de la souris pour passer en mode sélection et lorsque vous sélectionnez des éléments, vous verrez un sous-ensemble aléatoire apparaître sur la droite. Vous pouvez rééchantillonner à partir de votre sélection en cliquant sur le bouton de rééchantillonnage.
Lorsque vous effectuez des sélections, vous pouvez voir le widget sur la bonne mise à jour, mais vous pouvez également récupérer les données d'un attribut Python.
widget . selected_idx
widget . selected_texts
widget . selected_dataframeÊtre capable d'explorer ces clusters est bien, mais il semble que nous pourrions tout explorer plus facilement si nous disposions de davantage d'outils. En particulier, nous souhaitons disposer d'un encodeur afin de pouvoir utiliser des requêtes dans notre espace embarqué. L'interface utilisateur ci-dessous nous permettra d'explorer de manière beaucoup plus interactive en mettant à jour les couleurs avec une invite de texte.
from embetter . text import SentenceEncoder
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
# Pay attention here! The rows in df needs to align with the rows in X!
widget = BaseTextExplorer ( df , X = X , encoder = enc )
widget . show ()Grâce à des outils comme ipywidget et anywidget, nous pouvons vraiment commencer à créer des outils pour que le notebook reste l'endroit idéal pour vos besoins en données. Avec quelques widgets appropriés, vous ne pourrez jamais surpasser un notebook Jupyter !
L'intérêt premier de ce projet est de travailler sur des outils pour la qualité des données. Être capable de sélectionner des points de données en masse semble être un excellent point de départ. Peut-être pourrez-vous trouver un sous-ensemble intéressant à annoter en premier, peut-être serez-vous surpris lorsque vous verrez deux clusters distincts qui devraient en être un. Toutes ces bonnes choses peuvent arriver dans le cahier !
Bulk est également livré avec une petite application Web qui utilise Bokeh pour vous proposer des interfaces d'annotation basées sur des représentations UMAP des intégrations. Il offre une interface pour le texte. Cette interface était l'interface/fonctionnalité originale de ce projet.
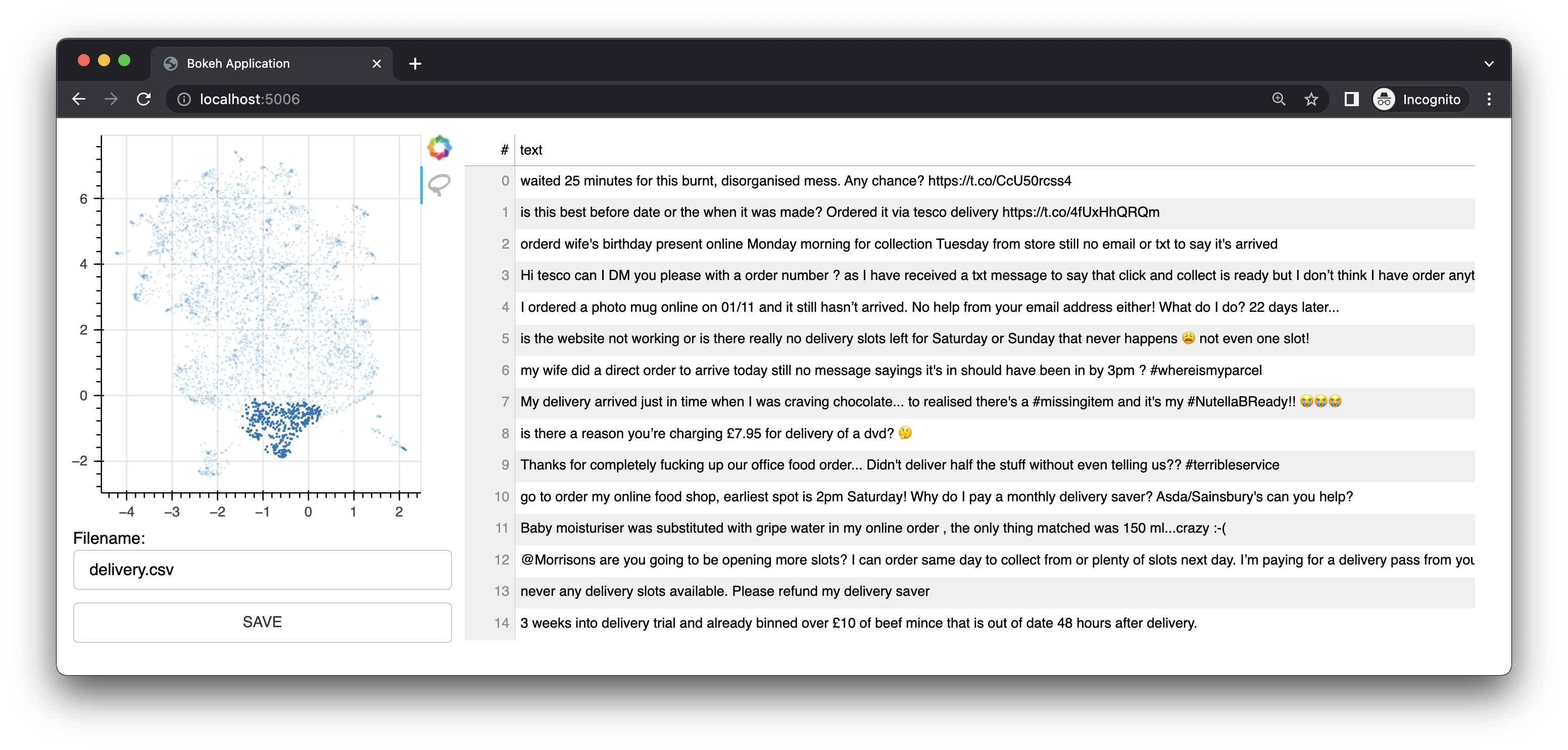
Il dispose également d'une interface d'image.
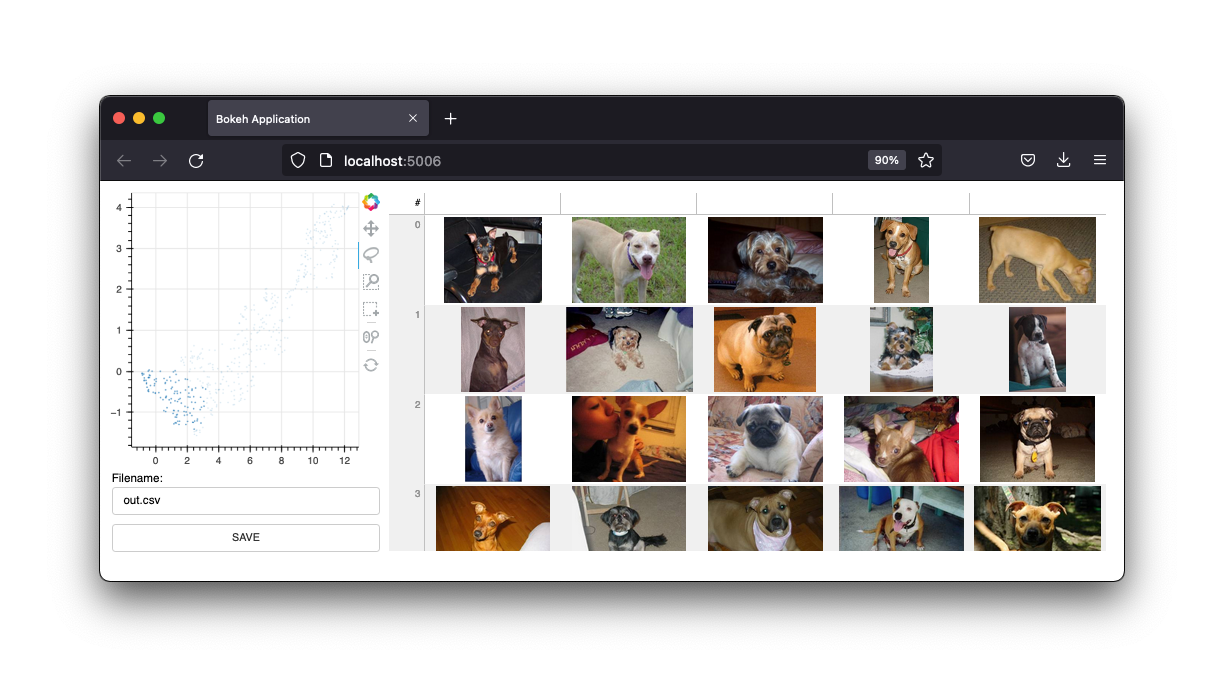
Nous conserverons ces interfaces, mais l'avenir de ce projet sera celui des widgets d'un notebook Jupyter. Cependant, en l’état, la webapp est certainement toujours utile.
Si vous êtes curieux d'en savoir plus, vous apprécierez peut-être cette vidéo sur YouTube pour le texte et cette vidéo sur YouTube pour la vision par ordinateur.
Pour utiliser le traitement groupé pour le texte, vous devez d'abord préparer un fichier CSV.
Note
L'exemple ci-dessous utilise embetter pour générer les intégrations et umap pour réduire les dimensions. Mais vous êtes totalement libre d'utiliser l'outil d'intégration de texte de votre choix. Vous devrez installer ces outils séparément. Notez qu'embetter utilise des transformateurs de phrases sous le capot.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
text_emb_pipeline = make_pipeline (
SentenceEncoder ( 'all-MiniLM-L6-v2' ),
UMAP ()
)
# Load sentences
sentences = list ( pd . read_csv ( "original.csv" )[ 'sentences' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]
df . to_csv ( "ready.csv" , index = False ) Vous pouvez maintenant utiliser ce fichier ready.csv pour appliquer un étiquetage groupé.
python -m bulk text ready.csv
Si vous recherchez un exemple de fichier avec lequel jouer, vous pouvez télécharger le fichier de démonstration .csv dans ce référentiel. Cet ensemble de données contient un sous-ensemble d'un ensemble de données trouvé sur Kaggle. Vous pouvez trouver l'original ici.
Vous pouvez également transmettre une colonne supplémentaire à votre fichier csv appelée "couleur". Cette colonne servira ensuite à colorer les points dans l'interface.
Vous pouvez également transmettre --keywords à l'application de ligne de commande pour mettre en évidence les éléments contenant des mots-clés spécifiques.
python -m bulk text ready.csv --keywords "deliver,card,website,compliment"
L'exemple ci-dessous utilise la bibliothèque embetter pour créer un ensemble de données pour l'étiquetage groupé des images.
Note
L'exemple ci-dessous utilise embetter pour générer les intégrations et umap pour réduire les dimensions. Mais vous êtes totalement libre d'utiliser l'outil d'intégration de texte de votre choix. Vous devrez installer ces outils séparément. Notez qu'Embetter utilise TIMM sous le capot.
import pathlib
import pandas as pd
from sklearn . pipeline import make_pipeline
from umap import UMAP
from sklearn . preprocessing import MinMaxScaler
# pip install "embetter[vision]"
from embetter . grab import ColumnGrabber
from embetter . vision import ImageLoader , TimmEncoder
# Build image encoding pipeline
image_emb_pipeline = make_pipeline (
ColumnGrabber ( "path" ),
ImageLoader ( convert = "RGB" ),
TimmEncoder ( 'xception' ),
UMAP (),
MinMaxScaler ()
)
# Make dataframe with image paths
img_paths = list ( pathlib . Path ( "downloads" , "pets" ). glob ( "*" ))
dataf = pd . DataFrame ({
"path" : [ str ( p ) for p in img_paths ]
})
# Make csv file with Umap'ed model layer
# Note! Bulk assumes the image path column to be called "path"!
X = image_emb_pipeline . fit_transform ( dataf )
dataf [ 'x' ] = X [:, 0 ]
dataf [ 'y' ] = X [:, 1 ]
dataf . to_csv ( "ready.csv" , index = False )Cela génère un fichier csv qui peut être chargé en masse via ;
python -m bulk image ready.csv
Vous pouvez également générer un ensemble de vignettes pour vos images. Cela peut être utile si vous travaillez avec un grand ensemble de données.
python -m bulk util resize ready.csv ready2.csv temp
Cela créera un dossier appelé temp avec toutes les images redimensionnées. Vous pouvez ensuite utiliser ce dossier comme argument --thumbnail-path .
python -m bulk image ready2.csv --thumbnail-path temp
Vous pouvez également utiliser le volume pour télécharger certains ensembles de données avec lesquels jouer. Pour plus d'informations :
python -m bulk download --help
L'interface peut vous aider à étiqueter très rapidement, mais les étiquettes elles-mêmes peuvent être assez bruyantes. Le cas d'utilisation prévu pour cet outil est de préparer des sous-ensembles intéressants à utiliser plus tard dans prodi.gy.


