chatdocs
0.2.6
Discutez avec vos documents hors ligne grâce à l'IA. Aucune donnée ne quitte votre système. Une connexion Internet est uniquement requise pour installer l'outil et télécharger les modèles d'IA. Il est basé sur PrivateGPT mais possède plus de fonctionnalités.
Contenu
chatdocs.yml| Extension | Format |
|---|---|
.csv | CSV |
.docx , .doc | Document Word |
.enex | EverNote |
.eml | |
.epub | EPub |
.html | HTML |
.md | Réduction |
.msg | Message Outlook |
.odt | Ouvrir le texte du document |
.pdf | Format de document portable (PDF) |
.pptx , .ppt | Document PowerPoint |
.txt | Fichier texte (UTF-8) |
Installez l'outil en utilisant :
pip install chatdocsTéléchargez les modèles d'IA en utilisant :
chatdocs downloadIl peut désormais être exécuté hors ligne, sans connexion Internet.
Ajoutez un répertoire contenant des documents avec lesquels discuter en utilisant :
chatdocs add /path/to/documentsLes documents traités seront stockés dans le répertoire
dbpar défaut.
Discutez avec vos documents en utilisant :
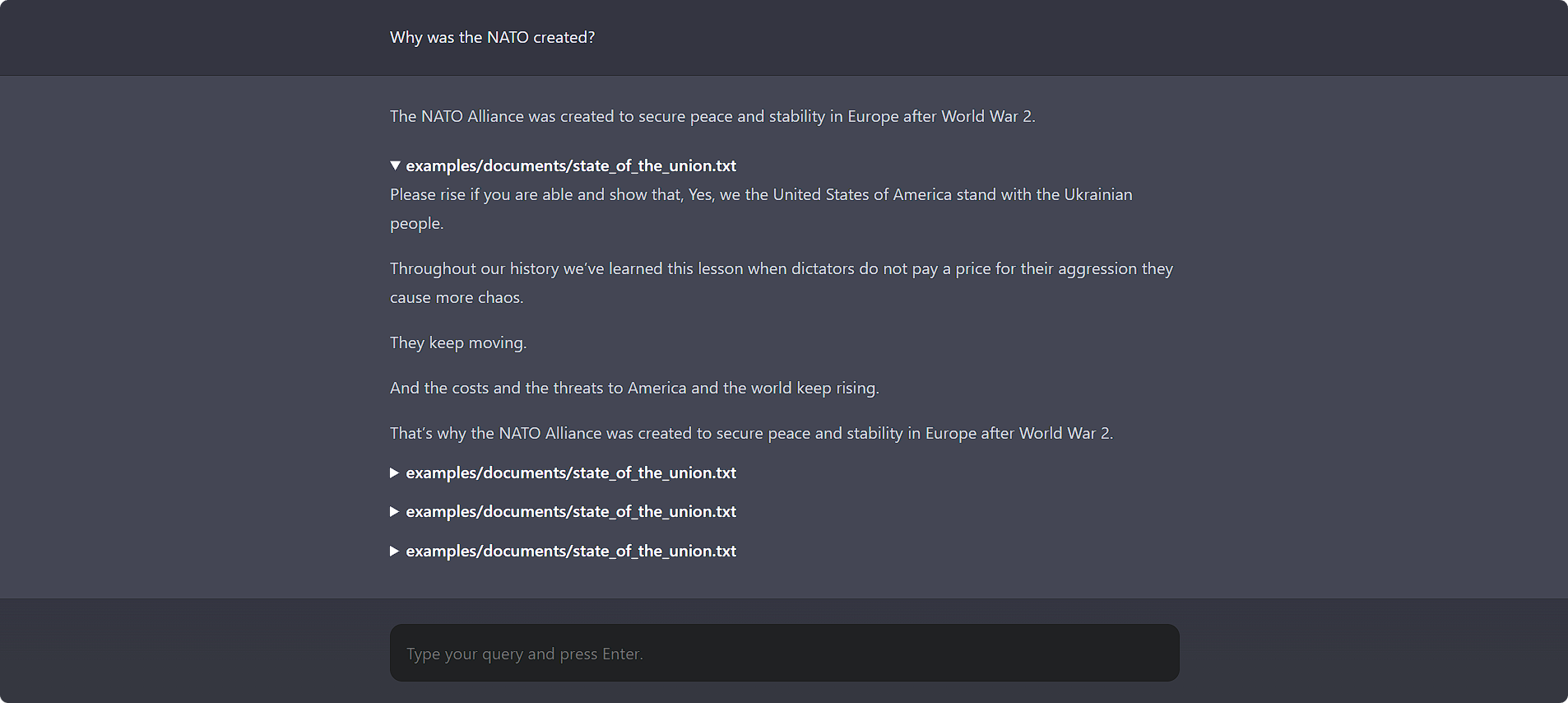
chatdocs uiOuvrez http://localhost:5000 dans votre navigateur pour accéder à l'interface utilisateur Web.
Il possède également une belle interface de ligne de commande :
chatdocs chat
Toutes les options de configuration peuvent être modifiées à l'aide du fichier de configuration chatdocs.yml . Créez un fichier chatdocs.yml dans un répertoire et exécutez toutes les commandes de ce répertoire. Pour référence, consultez le fichier chatdocs.yml par défaut.
Vous n'êtes pas obligé de copier l'intégralité du fichier, ajoutez simplement les options de configuration que vous souhaitez modifier car elles seront fusionnées avec la configuration par défaut. Par exemple, voir tests/fixtures/chatdocs.yml qui ne modifie que certaines options de configuration.
Pour modifier le modèle d'intégration, ajoutez et modifiez ce qui suit dans votre chatdocs.yml :
embeddings :
model : hkunlp/instructor-largeRemarque : Lorsque vous modifiez le modèle d'intégration, supprimez le répertoire
dbet ajoutez à nouveau des documents.
Pour modifier le modèle CTransformers (GGML/GGUF), ajoutez et modifiez ce qui suit dans votre chatdocs.yml :
ctransformers :
model : TheBloke/Wizard-Vicuna-7B-Uncensored-GGML
model_file : Wizard-Vicuna-7B-Uncensored.ggmlv3.q4_0.bin
model_type : llamaRemarque : Lorsque vous ajoutez un nouveau modèle pour la première fois, exécutez
chatdocs downloadpour télécharger le modèle avant de l'utiliser.
Vous pouvez également utiliser un fichier de modèle local existant :
ctransformers :
model : /path/to/ggml-model.bin
model_type : llama Utiliser ? Modèles Transformers, ajoutez ce qui suit à votre chatdocs.yml :
llm : huggingface Pour changer le ? Modèle Transformers, ajoutez et modifiez ce qui suit dans votre chatdocs.yml :
huggingface :
model : TheBloke/Wizard-Vicuna-7B-Uncensored-HFRemarque : Lorsque vous ajoutez un nouveau modèle pour la première fois, exécutez
chatdocs downloadpour télécharger le modèle avant de l'utiliser.
Pour utiliser des modèles GPTQ avec ? Transformers, installez les packages nécessaires en utilisant :
pip install chatdocs[gptq] Pour activer la prise en charge GPU (CUDA) pour le modèle d'intégration, ajoutez ce qui suit à votre chatdocs.yml :
embeddings :
model_kwargs :
device : cudaVous devrez peut-être réinstaller PyTorch avec CUDA activé en suivant les instructions ici.
Pour activer la prise en charge GPU (CUDA) pour le modèle CTransformers (GGML/GGUF), ajoutez ce qui suit à votre chatdocs.yml :
ctransformers :
config :
gpu_layers : 50Vous devrez peut-être installer les bibliothèques CUDA en utilisant :
pip install ctransformers[cuda] Pour activer la prise en charge GPU (CUDA) pour le ? Modèle Transformers, ajoutez ce qui suit à votre chatdocs.yml :
huggingface :
device : 0Vous devrez peut-être réinstaller PyTorch avec CUDA activé en suivant les instructions ici.
MIT


