MagicMix
1.0.0
Implémentation de MagicMix : document de mélange sémantique avec des modèles de diffusion.
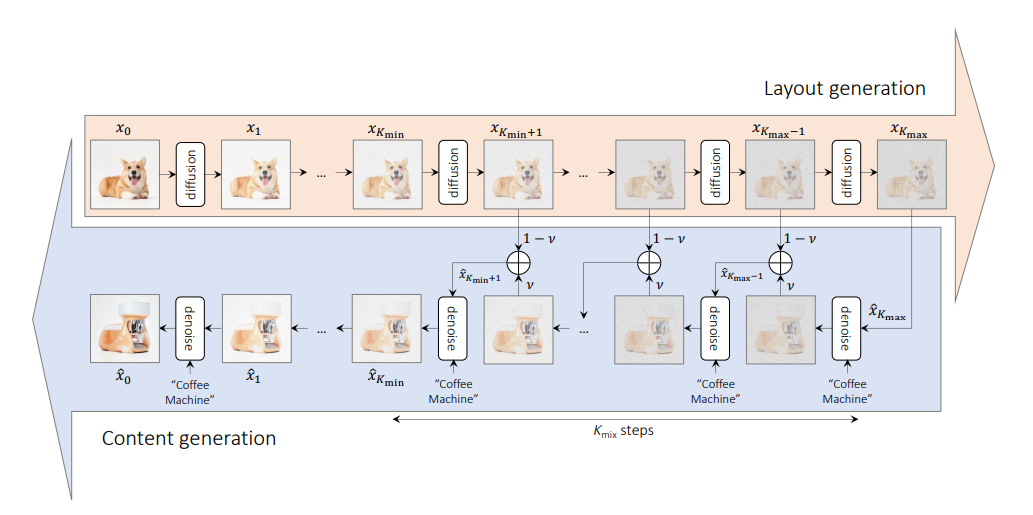
Le but de la méthode est de mélanger deux concepts différents de manière sémantique pour synthétiser un nouveau concept tout en préservant l'agencement spatial et la géométrie.
Le procédé prend une image qui fournit la sémantique de mise en page et une invite qui fournit la sémantique de contenu pour le processus de mixage.
Il y a 3 paramètres pour la méthode-
v : C'est la constante d'interpolation utilisée dans la phase de génération du layout. Plus la valeur de v est grande, plus l'influence de l'invite sur le processus de génération de mise en page est grande.kmax et kmin : ceux-ci déterminent la plage du processus de mise en page et de génération de contenu. Une valeur plus élevée de kmax entraîne une perte de plus d'informations sur la disposition de l'image d'origine et une valeur plus élevée de kmin entraîne davantage d'étapes dans le processus de génération de contenu. from PIL import Image
from magic_mix import magic_mix
img = Image . open ( 'phone.jpg' )
out_img = magic_mix ( img , 'bed' , kmax = 0.5 )
out_img . save ( "mix.jpg" ) python3 magic_mix.py
"phone.jpg"
"bed"
"mix.jpg"
--kmin 0.3
--kmax 0.6
--v 0.5
--steps 50
--seed 42
--guidance_scale 7.5
Consultez également le cahier de démonstration pour un exemple d'utilisation de l'implémentation pour reproduire des exemples de l'article.
Vous pouvez également utiliser le pipeline communautaire sur la bibliothèque des diffuseurs.
from diffusers import DiffusionPipeline , DDIMScheduler
from PIL import Image
pipe = DiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
custom_pipeline = "magic_mix" ,
scheduler = DDIMScheduler . from_pretrained ( "CompVis/stable-diffusion-v1-4" , subfolder = "scheduler" ),
). to ( 'cuda' )
img = Image . open ( 'phone.jpg' )
mix_img = pipe (
img ,
prompt = 'bed' ,
kmin = 0.3 ,
kmax = 0.5 ,
mix_factor = 0.5 ,
)
mix_img . save ( 'mix.jpg' )







Je ne suis pas l'auteur de l'article et ce n'est pas une implémentation officielle


