ai pizza
1.0.0
Pourtant, personne ne sait si une machine peut créer quelque chose de nouveau ou si elle se limite à ce qu’elle sait déjà. Mais même aujourd’hui, l’intelligence artificielle peut résoudre des problèmes complexes et analyser des ensembles de données non structurées. Chez Dodo, nous avons décidé de mener une expérience. Organiser et décrire structurellement quelque chose qui est considéré comme chaotique et subjectif : le goût. Nous avons décidé d'utiliser l'intelligence artificielle pour trouver les combinaisons d'ingrédients les plus folles qui seront néanmoins considérées comme délicieuses par la plupart des gens.
En collaboration avec des experts du MIPT et de Skoltech, nous avons créé une intelligence artificielle qui a analysé plus de 300 000 recettes et résultats de recherches sur les combinaisons moléculaires d'ingrédients menées par Cambridge et plusieurs autres universités américaines. Sur cette base, l’IA a appris à trouver des liens non évidents entre les ingrédients et à comprendre comment associer les ingrédients et comment la présence de chacun influence les combinaisons de tous les autres.
Pour tout modèle, vous avez besoin de données. C'est pourquoi, pour entraîner notre IA, nous avons collecté plus de 300 000 recettes de cuisine.
Le plus difficile n’était pas de les rassembler mais de les amener à la même forme. Par exemple, le piment dans les recettes est répertorié comme « chili », « chili », « chilis » ou même « chilis ». Il est évident pour nous que tous ces moyens signifient « piment », mais le réseau de neurones considère chacun d'eux comme une entité individuelle.
Au départ, nous avions plus de 100 000 ingrédients uniques, et après avoir nettoyé les données, il ne restait plus que 1 000 positions uniques.
Une fois que nous avons obtenu l’ensemble de données, nous avons effectué une première analyse. Tout d’abord, nous avons eu une évaluation quantitative du nombre de cuisines présentes dans notre ensemble de données.
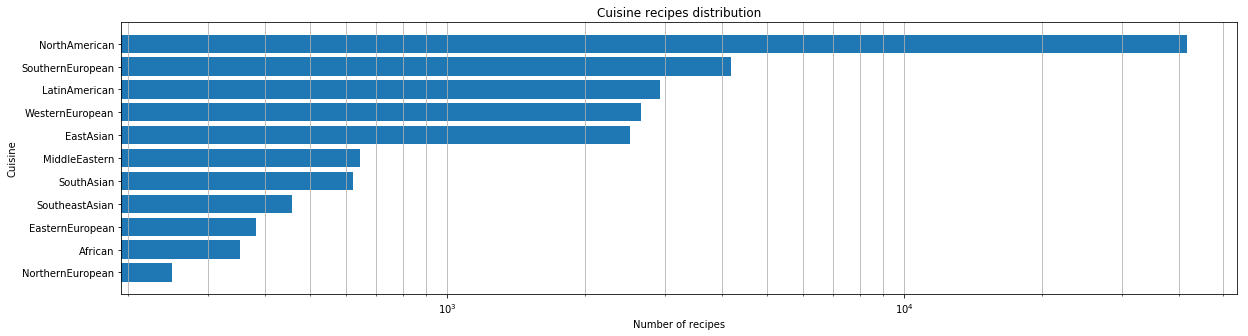
Pour chaque cuisine, nous avons identifié les ingrédients les plus appréciés.
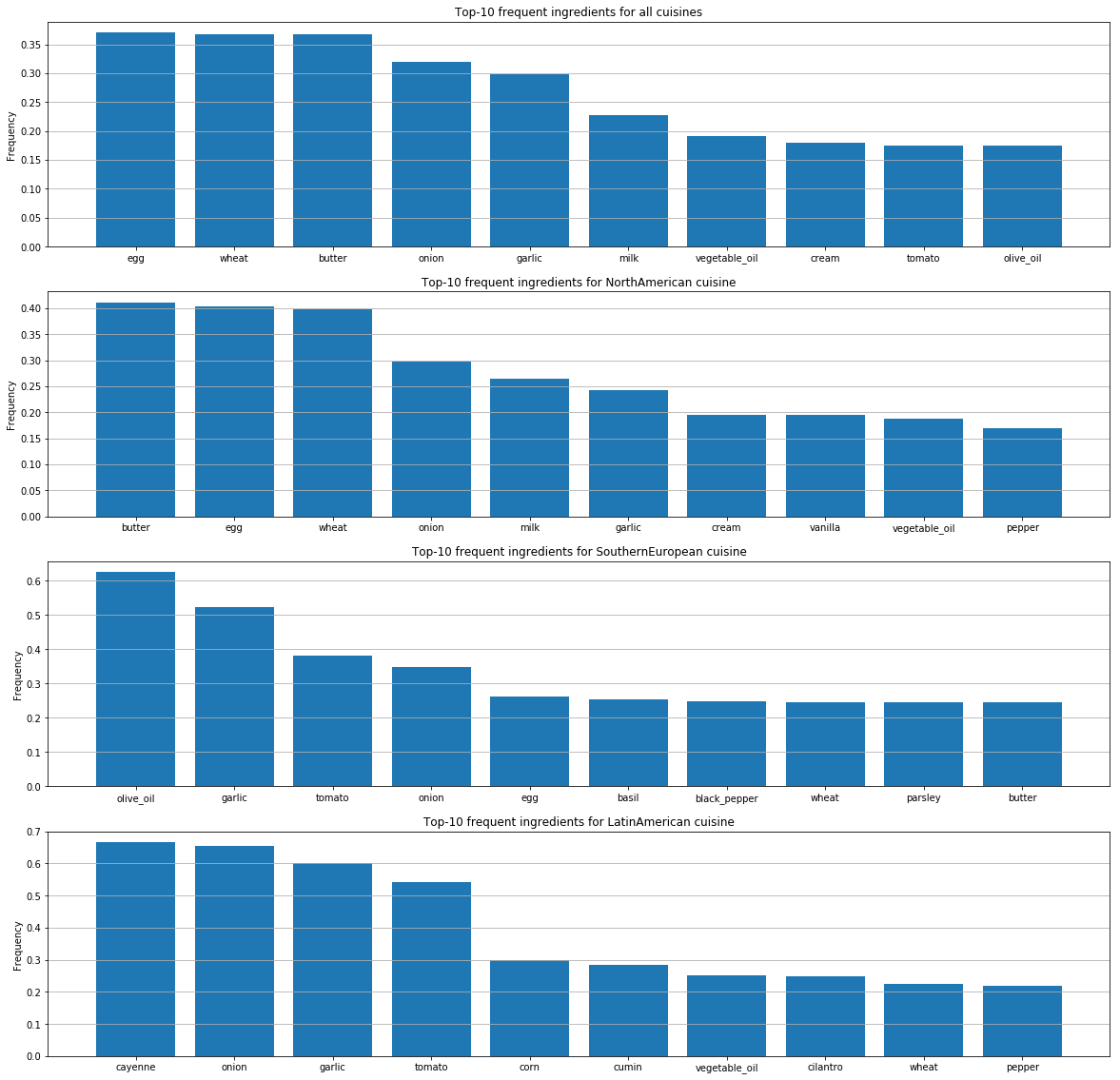
Ces graphiques montrent les différences dans les préférences gustatives des gens selon les pays et les différences dans la manière dont ils combinent les ingrédients.
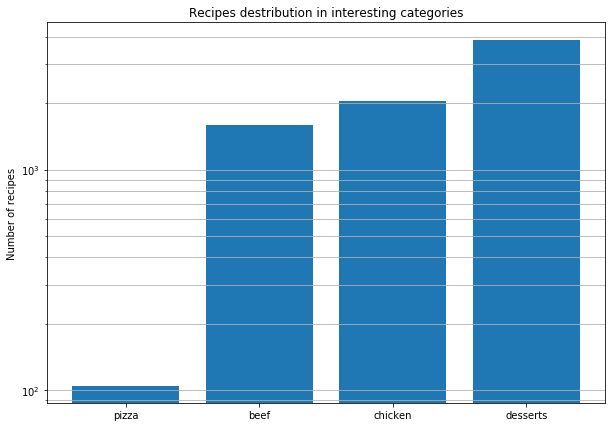
Après cela, nous avons décidé d’analyser des recettes de pizza du monde entier pour en découvrir les modèles. Telles sont les conclusions que nous avons tirées.
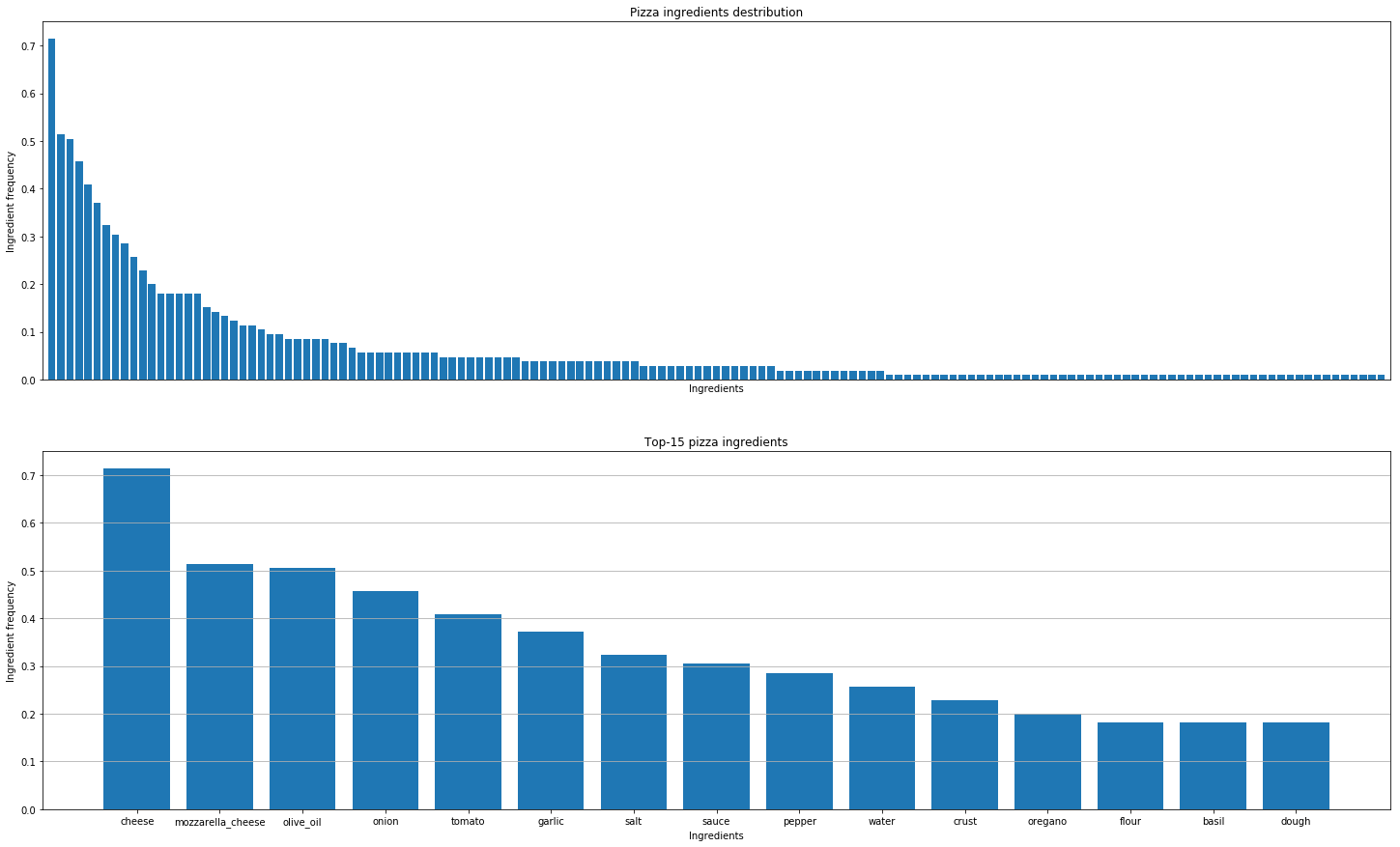
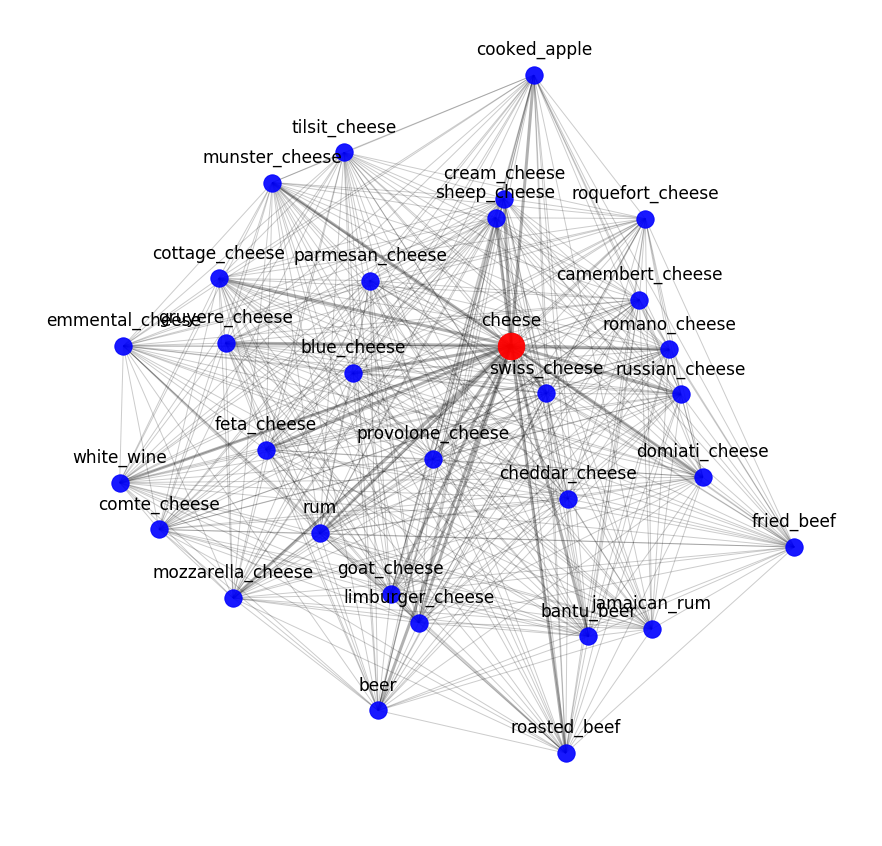
Trouver de véritables combinaisons de goûts n’est pas la même chose que trouver des combinaisons moléculaires. Tous les fromages ont la même composition moléculaire, mais cela ne signifie pas que de bonnes combinaisons ne peuvent provenir que d'ingrédients les plus proches.
Cependant, ce sont les combinaisons d’ingrédients moléculairement similaires que nous devons observer lorsque nous convertissons les ingrédients en mathématiques. Parce que les objets similaires (les mêmes fromages) doivent rester similaires, quelle que soit la manière dont on les décrit. De cette façon, nous pouvons déterminer si les objets sont décrits correctement.
Pour présenter la recette sous une forme compréhensible pour le réseau neuronal, nous avons utilisé Skip-Gram Negative Sampling (SGNS) — un algorithme de word2vec, basé sur l'occurrence de mots dans leur contexte.
Nous avons décidé de ne pas utiliser de modèles word2vec pré-entraînés car la structure sémantique de la recette est différente de celle des textes simples. Et avec ces modèles, nous pourrions perdre des informations importantes.
Vous pouvez évaluer le résultat de word2vec en examinant les voisins sémantiques les plus proches. Par exemple, voici ce que notre modèle sait sur le fromage :
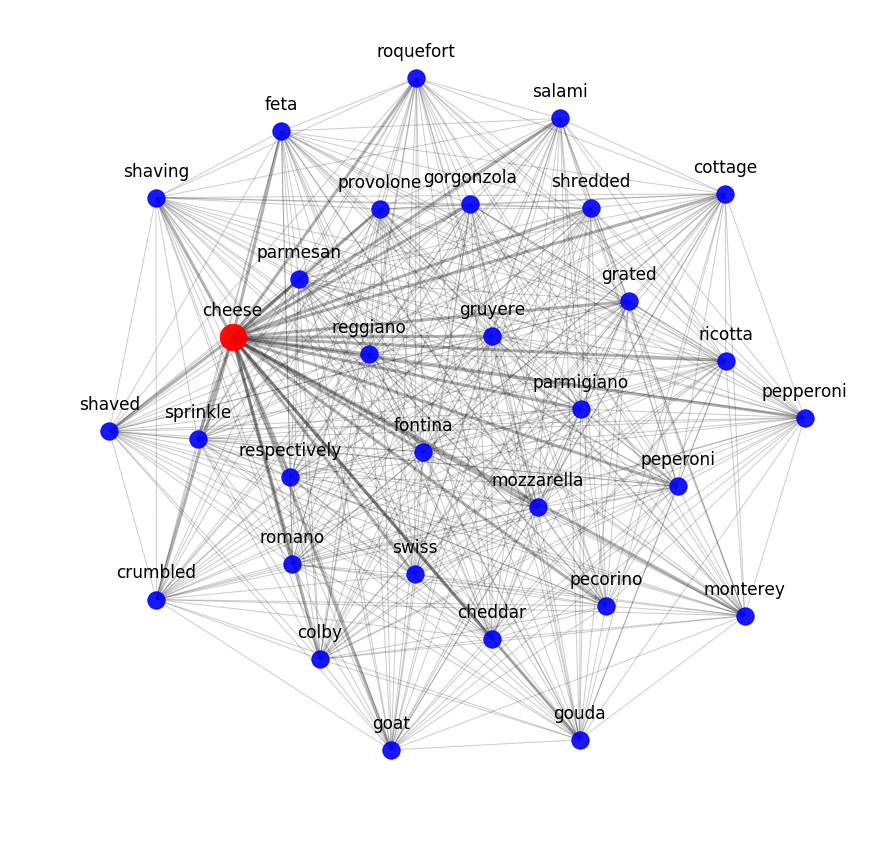
Pour tester dans quelle mesure les modèles sémantiques peuvent capturer les relations entre les ingrédients dans les recettes, nous avons appliqué un modèle thématique. En d’autres termes, nous avons essayé de diviser l’ensemble de données de recettes en clusters selon des régularités mathématiquement déterminées.
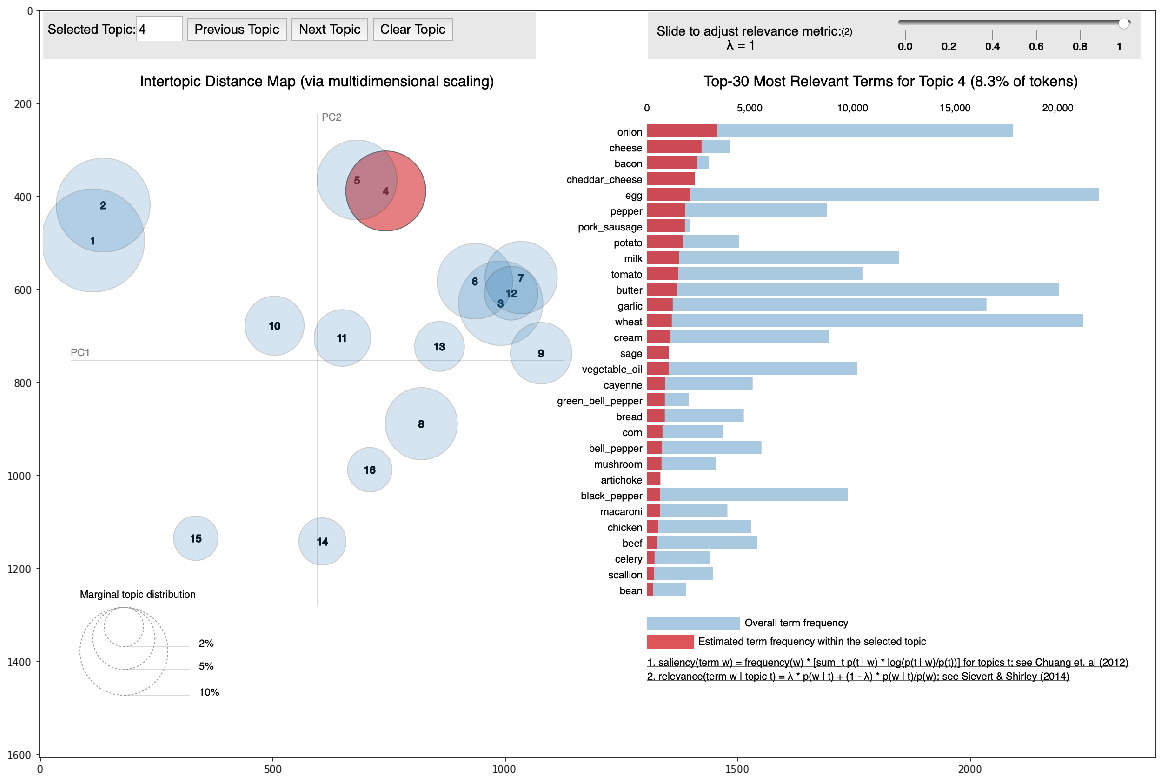
Pour toutes les recettes, nous connaissions les groupes déterminés auxquels elles correspondaient. Pour des exemples de recettes, nous connaissions leur lien avec de vrais clusters. Sur cette base, nous avons trouvé le lien entre ces deux types de clusters.
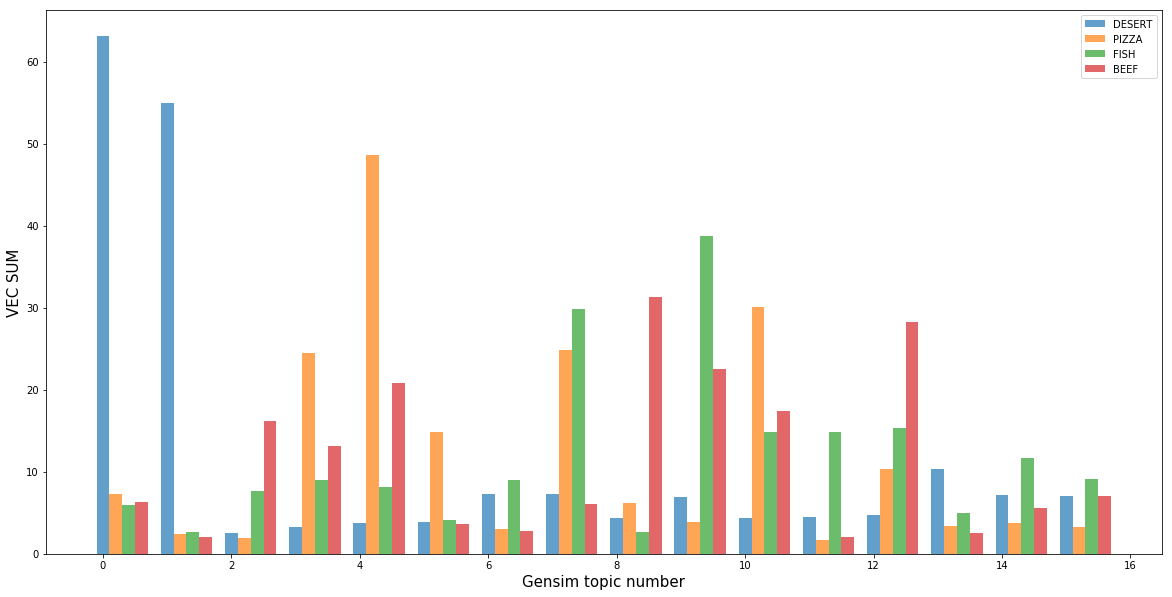
Le plus évident était la classe de desserts, qui étaient inclus dans les thèmes 0 et 1, générés par le modèle thématique. En plus des desserts, il n'existe pratiquement aucune autre classe sur ces sujets, ce qui suggère que les desserts se distinguent facilement des autres classes de plats. De plus, chaque sujet possède une classe qui le décrit le mieux. Cela signifie que nos modèles ont réussi à définir mathématiquement la signification non évidente du « goût ».
Nous avons utilisé deux réseaux de neurones récurrents pour créer de nouvelles recettes. Pour cela, nous avons supposé que dans tout l’espace des recettes, il existe un sous-espace correspondant aux recettes de pizza. Et pour que le réseau de neurones apprenne à créer de nouvelles recettes de pizza, il fallait trouver ce sous-espace.
Cette tâche est similaire à l’autoencodage d’image, dans lequel nous présentons l’image sous forme de vecteur de faible dimension. Ces vecteurs peuvent contenir de nombreuses informations spécifiques sur l’image.
Par exemple, ces vecteurs peuvent stocker des informations sur la couleur des cheveux d'une personne dans une cellule distincte pour la reconnaissance faciale sur une photo. Nous avons choisi cette approche précisément en raison des propriétés uniques du sous-espace caché.
Pour identifier le sous-espace pizza, nous avons exécuté les recettes de pizza via deux réseaux de neurones récurrents. Le premier reçut la recette de la pizza et trouva sa représentation comme vecteur latent. Le second a reçu un vecteur latent du premier réseau de neurones et a créé une recette basée sur celui-ci. Les recettes à l’entrée du premier réseau de neurones et à la sortie du second auraient dû correspondre.
De cette manière, deux réseaux de neurones ont appris à transformer correctement la recette d'un vecteur latent. Et sur cette base, nous avons pu trouver un sous-espace caché, qui correspond à toute la gamme des recettes de pizza.
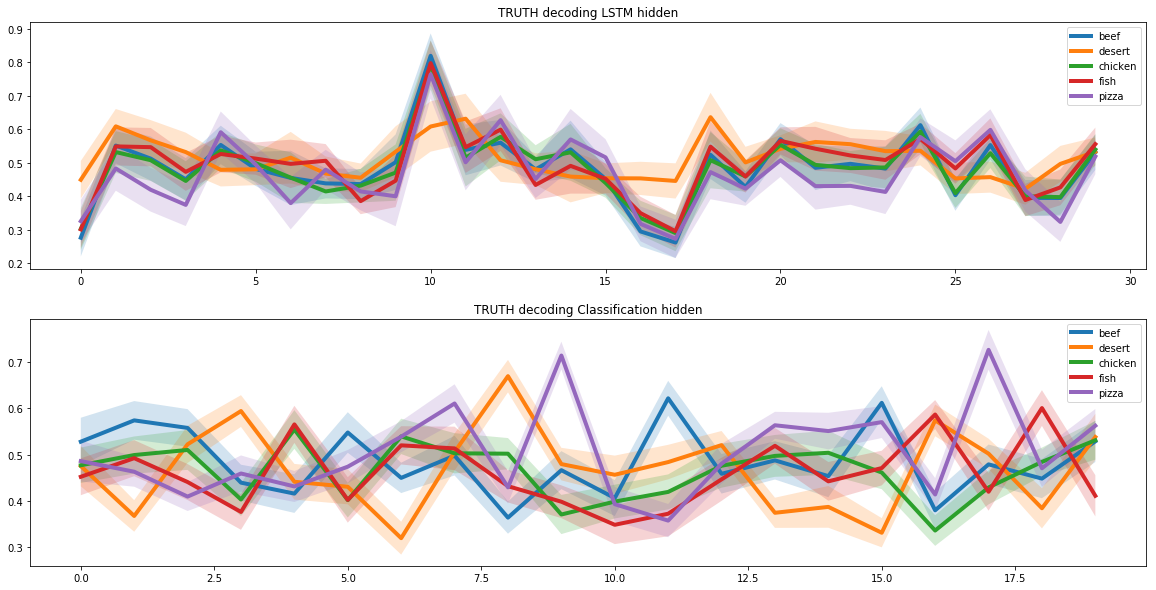
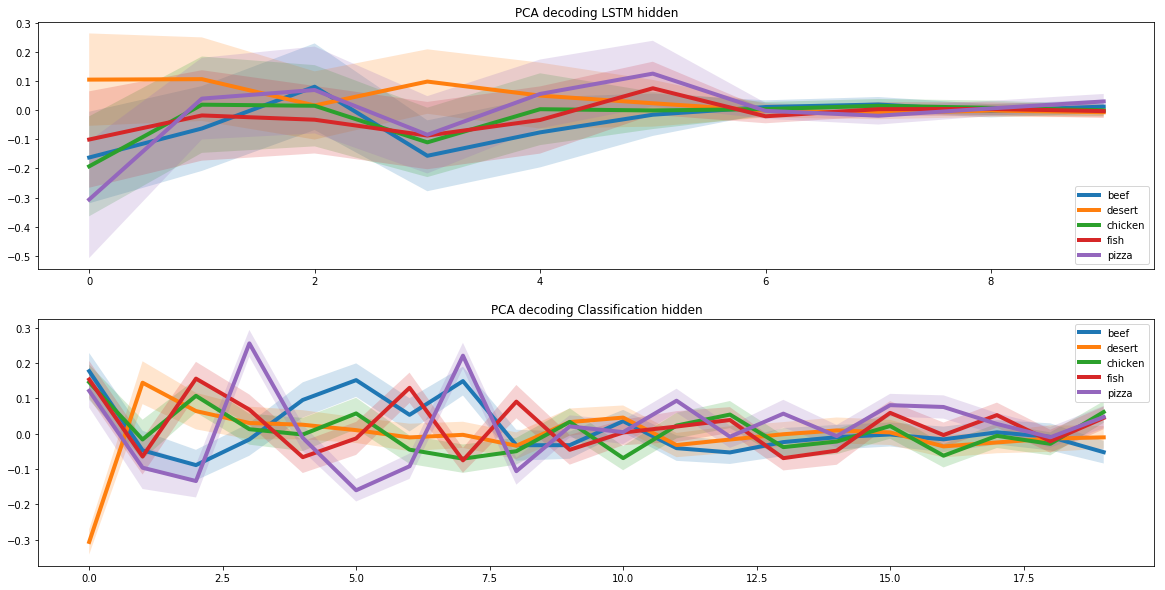
Lorsque nous avons résolu le problème de la création d’une recette de pizza, nous avons dû ajouter des critères de combinaison moléculaire au modèle. Pour ce faire, nous avons utilisé les résultats d’une étude conjointe de scientifiques de Cambridge et de plusieurs universités américaines.
L’étude a révélé que les ingrédients comportant les paires moléculaires les plus courantes forment les meilleures combinaisons. Par conséquent, lors de la création de la recette, le réseau neuronal a privilégié les ingrédients ayant une structure moléculaire similaire.
En conséquence, notre réseau neuronal a appris à créer des recettes de pizza. En ajustant les coefficients, le réseau de neurones peut produire aussi bien des recettes classiques comme les margaritas ou le pepperoni que des recettes insolites, dont l'une est le cœur d'Opensource Pizza.
| Non | Recette |
|---|---|
| 1 | épinards, fromage, tomate, olive_noire, olive, ail, poivre, basilic, agrumes, melon, germe, babeurre, citron, bar, noix, rutabaga |
| 2 | oignon, tomate, olive, poivre noir, pain, pâte |
| 3 | poulet, oignon, olive_noire, fromage, sauce, tomate, huile d'olive, fromage_mozzarella |
| 4 | tomate, beurre, fromage à la crème, poivre, huile d'olive, fromage, poivre noir, fromage mozzarella |
Open Source Pizza est sous licence MIT.
Golodyayev Arseniy, MIPT, Skoltech, [email protected]
Egor Baryshnikov, Skoltech, [email protected]


