CQN
1.0.0
Une réimplémentation de Coarse-to-fine Q-Network (CQN) , un algorithme RL basé sur des valeurs efficaces pour le contrôle continu, introduit dans :
Contrôle continu avec apprentissage par renforcement grossier à fin
Younggyo Seo, Jafar Uruç, Stephen James
Notre idée clé est d'apprendre des agents RL qui zooment sur l'espace d'action continue de manière grossière à fine, ce qui nous permet de former des agents RL basés sur des valeurs pour un contrôle continu avec peu d'actions discrètes à chaque niveau.
Consultez la page Web de notre projet https://younggyo.me/cqn/ pour plus d'informations.
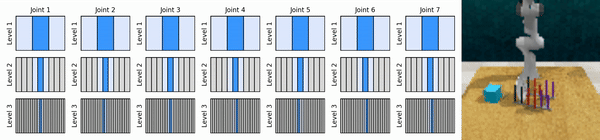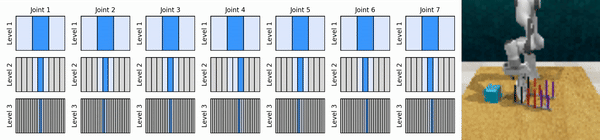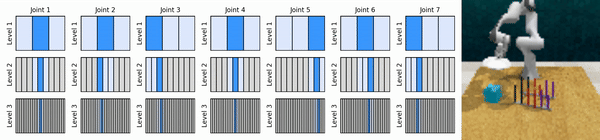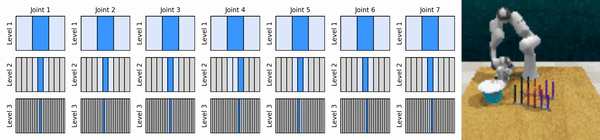
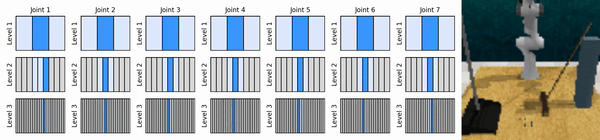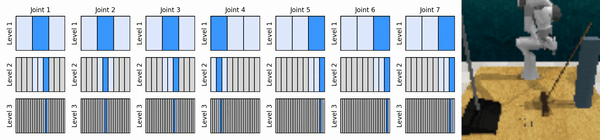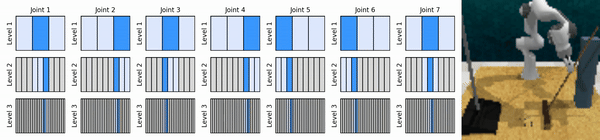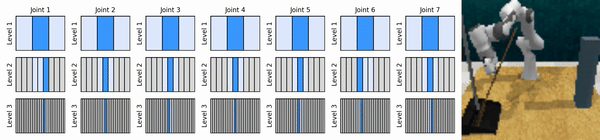
Installez l'environnement conda :
conda env create -f conda_env.yml
conda activate cqn
Installez RLBench et PyRep (les dernières versions à la date du 10 juillet 2024 doivent être utilisées). Suivez le guide dans les référentiels d'origine pour (1) installer RLBench et PyRep et (2) activer le mode sans tête. (Voir README dans RLBench & Robobase pour plus d'informations sur l'installation de RLBench.)
git clone https://github.com/stepjam/RLBench
git clone https://github.com/stepjam/PyRep
# Install PyRep
cd PyRep
git checkout 8f420be8064b1970aae18a9cfbc978dfb15747ef
pip install .
# Install RLBench
cd RLBench
git checkout b80e51feb3694d9959cb8c0408cd385001b01382
pip install .
Démonstrations de pré-collecte
cd RLBench/rlbench
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python dataset_generator.py --save_path=/your/own/directory --image_size 84 84 --renderer opengl3 --episodes_per_task 100 --variations 1 --processes 1 --tasks take_lid_off_saucepan --arm_max_velocity 2.0 --arm_max_acceleration 8.0
Exécuter des expériences (CQN) :
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
Exécutez des expériences de base (DrQv2+) :
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench_drqv2plus.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
Exécutez des expériences :
CUDA_VISIBLE_DEVICES=0 python train_dmc.py dmc_task=cartpole_swingup
Attention : CQN n'est pas testé de manière approfondie dans DMC
Ce référentiel est basé sur l'implémentation publique de DrQ-v2
@article{seo2024continuous,
title={Continuous Control with Coarse-to-fine Reinforcement Learning},
author={Seo, Younggyo and Uru{c{c}}, Jafar and James, Stephen},
journal={arXiv preprint arXiv:2407.07787},
year={2024}
}


