lorax
v0.12.0: Multi-LoRA prefix caching, fp8 kv cache, Mllama, function calling

LoRAX : serveur d'inférence multi-LoRA qui s'adapte à des milliers de LLM affinés
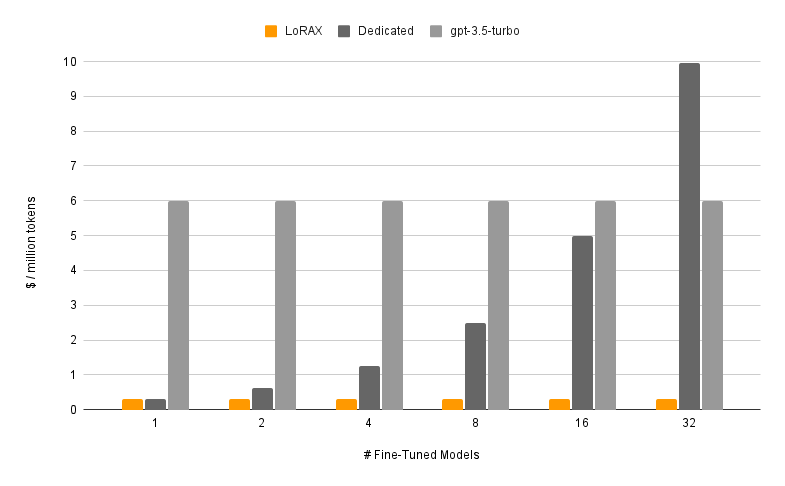
LoRAX (LoRA eXchange) est un framework qui permet aux utilisateurs de servir des milliers de modèles affinés sur un seul GPU, réduisant considérablement le coût de service sans compromettre le débit ou la latence.
Table des matières
Caractéristiques
Modèles
?Commencer
Exigences
Lancer le serveur LoRAX
Invite via l'API REST
Invite via le client Python
Discutez via l'API OpenAI
Prochaines étapes
Remerciements
Feuille de route
Chargement dynamique de l'adaptateur : incluez n'importe quel adaptateur LoRA affiné de HuggingFace, Predibase ou n'importe quel système de fichiers dans votre demande, il sera chargé juste à temps sans bloquer les demandes simultanées. Fusionnez les adaptateurs par demande pour créer instantanément des ensembles puissants.
Traitement par lots continu hétérogène : regroupe les demandes de différents adaptateurs dans le même lot, maintenant ainsi la latence et le débit presque constants avec le nombre d'adaptateurs simultanés.
Planification d'échange d'adaptateurs : précharge et décharge de manière asynchrone les adaptateurs entre la mémoire GPU et CPU, planifie le traitement par lots des demandes pour optimiser le débit global du système.
Inférence optimisée : optimisations à haut débit et à faible latence, y compris le parallélisme tensoriel, les noyaux CUDA précompilés (flash-attention, paged attention, SGMV), la quantification, le streaming de jetons.
Images Docker prédéfinies prêtes pour la production , graphiques Helm pour Kubernetes, métriques Prometheus et traçage distribué avec Open Telemetry. API compatible OpenAI prenant en charge les conversations de chat à plusieurs tours. Adaptateurs privés via l’isolation des locataires par demande. Sortie structurée (mode JSON).
? Gratuit pour un usage commercial : licence Apache 2.0. Assez dit ?.
Servir un modèle affiné avec LoRAX se compose de deux éléments :
Modèle de base : grand modèle pré-entraîné partagé entre tous les adaptateurs.
Adaptateur : poids d'adaptateur spécifiques à une tâche chargés dynamiquement par requête.
LoRAX prend en charge un certain nombre de modèles de langage étendus comme modèle de base, notamment Llama (y compris CodeLlama), Mistral (y compris Zephyr) et Qwen. Voir Architectures prises en charge pour une liste complète des modèles de base pris en charge.
Les modèles de base peuvent être chargés en fp16 ou quantifiés avec bitsandbytes , GPT-Q ou AWQ.
Les adaptateurs pris en charge incluent les adaptateurs LoRA formés à l'aide des bibliothèques PEFT et Ludwig. N'importe laquelle des couches linéaires du modèle peut être adaptée via LoRA et chargée dans LoRAX.
Nous vous recommandons de commencer avec notre image Docker prédéfinie pour éviter de compiler des noyaux CUDA personnalisés et d'autres dépendances.
La configuration système minimale requise pour exécuter LoRAX comprend :
GPU Nvidia (génération Ampère ou supérieure)
Pilotes de périphériques compatibles CUDA 11.8 et supérieurs
Système d'exploitation Linux
Docker (pour ce guide)
Installez nvidia-container-toolkit Ensuite
sudo systemctl daemon-reload
sudo systemctl restart docker
modèle=mistralai/Mistral-7B-Instruct-v0.1
volume=$PWD/données
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data
ghcr.io/predibase/lorax:main --model-id $modelPour un didacticiel complet incluant le streaming de jetons et le client Python, consultez Mise en route - Docker.
LLM de base rapide :
curl 127.0.0.1:8080/générer
-X POSTE
-d '{ "inputs": "[INST] Natalia a vendu des clips à 48 de ses amis en avril, puis elle a vendu deux fois moins de clips en mai. Combien de clips Natalia a-t-elle vendus au total en avril et en mai ? [/INST] ", "paramètres": { "max_new_tokens": 64 } }'
-H 'Type de contenu : application/json'Invitez un adaptateur LoRA :
curl 127.0.0.1:8080/générer
-X POSTE
-d '{ "inputs": "[INST] Natalia a vendu des clips à 48 de ses amis en avril, puis elle a vendu deux fois moins de clips en mai. Combien de clips Natalia a-t-elle vendus au total en avril et en mai ? [/INST] ", "parameters": { "max_new_tokens": 64, "adapter_id": "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k" } }'
-H 'Type de contenu : application/json'Voir Référence - API REST pour plus de détails.
Installer:
pip installer lorax-client
Courir:
from lorax import Clientclient = Client("http://127.0.0.1:8080")# Invite la base LLMprompt = "[INST] Natalia a vendu des clips à 48 de ses amis en avril, puis elle a vendu deux fois moins de clips en mai . Combien de clips Natalia a-t-elle vendus en tout en avril et en mai [/INST]"print(client.generate(prompt, max_new_tokens=64).generated_text)# Inviter un adaptateur LoRAadapter_id = "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k"print(client.generate(prompt, max_new_tokens=64, adapter_id=adapter_id).generated_text )Voir Référence - Client Python pour plus de détails.
Pour d'autres façons d'exécuter LoRAX, consultez Mise en route - Kubernetes, Mise en route - SkyPilot et Mise en route - Local.
LoRAX prend en charge les conversations de chat à plusieurs tours combinées au chargement dynamique d'un adaptateur via une API compatible OpenAI. Spécifiez simplement n’importe quel adaptateur comme paramètre model .
depuis openai import OpenAIclient = OpenAI(api_key="EMPTY",base_url="http://127.0.0.1:8080/v1",
)resp = client.chat.completions.create(model="alignment-handbook/zephyr-7b-dpo-lora",messages=[
{"role": "system","content": "Vous êtes un chatbot sympathique qui répond toujours à la manière d'un pirate",
},
{"role": "user", "content": "Combien d'hélicoptères un humain peut-il manger en une seule séance ?"},
],max_jetons=100,
)print("Réponse :", resp.choices[0].message.content)Voir API compatible OpenAI pour plus de détails.
Voici quelques autres modèles intéressants de Mistral-7B optimisés à essayer :
Alignement-handbook/zephyr-7b-dpo-lora : Mistral-7b affiné sur l'ensemble de données Zephyr-7B avec DPO.
IlyaGusev/saiga_mistral_7b_lora : chatbot russe basé sur Open-Orca/Mistral-7B-OpenOrca .
Undi95/Mistral-7B-roleplay_alpaca-lora : affiné à l'aide d'invites de jeu de rôle.
Vous pouvez trouver plus d'adaptateurs LoRA ici, ou essayer de peaufiner le vôtre avec PEFT ou Ludwig.
LoRAX est construit sur l'inférence de génération de texte de HuggingFace, dérivée de la v0.9.4 (Apache 2.0).
Nous souhaitons également remercier Punica pour son travail sur le noyau SGMV, utilisé pour accélérer l'inférence multi-adaptateur sous forte charge.
Notre feuille de route est suivie ici.


