gpt neox
GPT-NeoX 2.0
Ce référentiel enregistre la bibliothèque d'EleutherAI pour la formation de modèles de langage à grande échelle sur les GPU. Notre framework actuel est basé sur le modèle de langage Megatron de NVIDIA et a été complété par des techniques de DeepSpeed ainsi que par de nouvelles optimisations. Nous visons à faire de ce dépôt un lieu centralisé et accessible pour rassembler des techniques de formation de modèles de langage autorégressifs à grande échelle et à accélérer la recherche sur la formation à grande échelle. Cette bibliothèque est largement utilisée dans les laboratoires universitaires, industriels et gouvernementaux, notamment par les chercheurs du Oak Ridge National Lab, de CarperAI, de Stability AI, de Together.ai, de l'Université de Corée, de l'Université Carnegie Mellon et de l'Université de Tokyo, entre autres. Unique parmi les bibliothèques similaires, GPT-NeoX prend en charge une grande variété de systèmes et de matériels, y compris le lancement via Slurm, MPI et IBM Job Step Manager, et a été exécuté à grande échelle sur AWS, CoreWeave, ORNL Summit, ORNL Frontier, LUMI et autres.
Si vous ne cherchez pas à entraîner des modèles avec des milliards de paramètres à partir de zéro, ce n'est probablement pas la bonne bibliothèque à utiliser. Pour les besoins d'inférence génériques, nous vous recommandons d'utiliser plutôt la bibliothèque transformers Hugging Face qui prend en charge les modèles GPT-NeoX.
GPT-NeoX exploite bon nombre des mêmes fonctionnalités et technologies que la populaire bibliothèque Megatron-DeepSpeed, mais avec une convivialité considérablement accrue et de nouvelles optimisations. Les principales fonctionnalités incluent :
[9/9/2024] Nous prenons désormais en charge l'apprentissage des préférences via DPO, KTO et la modélisation des récompenses
[9/9/2024] Nous prenons désormais en charge l'intégration avec Comet ML, une plateforme de surveillance de l'apprentissage automatique
[21/05/2024] Nous prenons désormais en charge RWKV avec le parallélisme des pipelines !. Voir les PR pour RWKV et RWKV+pipeline
[21/03/2024] Nous prenons désormais en charge le mélange d'experts (MoE)
[17/03/2024] Nous prenons désormais en charge les GPU AMD MI250X
[15/03/2024] Nous prenons désormais en charge Mamba avec le parallélisme tensoriel ! Voir le PR
[8/10/2023] Nous prenons désormais en charge les points de contrôle avec AWS S3 ! Activez avec l'option de configuration s3_path (pour plus de détails, voir le PR)
[20/09/2023] Depuis le numéro 1035, nous avons abandonné Flash Attention 0.x et 1.x et migré la prise en charge vers Flash Attention 2.x. Nous ne pensons pas que cela posera des problèmes, mais si vous avez un cas d'utilisation spécifique qui nécessite la prise en charge de l'ancienne version de Flash à l'aide du dernier GPT-NeoX, veuillez signaler un problème.
[8/10/2023] Nous avons un support expérimental pour LLaMA 2 et Flash Attention v2 pris en charge dans notre projet math-lm qui sera mis en amont plus tard ce mois-ci.
[17/05/2023] Après avoir corrigé quelques bugs divers, nous prenons désormais entièrement en charge bf16.
[11/04/2023] Nous avons mis à niveau notre implémentation Flash Attention pour prendre désormais en charge les intégrations positionnelles Alibi.
[3/9/2023] Nous avons publié GPT-NeoX 2.0.0, une version mise à niveau construite sur le dernier DeepSpeed qui sera régulièrement synchronisée à l'avenir.
Avant le 9/03/2023, GPT-NeoX s'appuyait sur DeeperSpeed, qui était basé sur une ancienne version de DeepSpeed (0.3.15). Afin de migrer vers la dernière version en amont de DeepSpeed tout en permettant aux utilisateurs d'accéder aux anciennes versions de GPT-NeoX et DeeperSpeed, nous avons introduit deux versions versionnées pour les deux bibliothèques :
Cette base de code a principalement été développée et testée pour Python 3.8-3.10 et PyTorch 1.8-2.0. Ce n’est pas une exigence stricte et d’autres versions et combinaisons de bibliothèques peuvent fonctionner.
Pour installer les dépendances de base restantes, exécutez :
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # optional, if logging using WandB
pip install -r requirements/requirements-tensorboard.txt # optional, if logging via tensorboard
pip install -r requirements/requirements-comet.txt # optional, if logging via Cometà partir de la racine du référentiel.
Avertissement
Notre base de code s'appuie sur DeeperSpeed, notre fork de la bibliothèque DeepSpeed avec quelques modifications supplémentaires. Nous vous recommandons fortement d'utiliser Anaconda, une machine virtuelle ou une autre forme d'isolation de l'environnement avant de continuer. Ne pas le faire peut entraîner la panne d’autres référentiels qui s’appuient sur DeepSpeed.
Nous prenons désormais en charge les GPU AMD (MI100, MI250X) via la compilation JIT à noyau fusionné. Les noyaux fusionnés seront construits et chargés selon les besoins. Pour éviter d'attendre lors du lancement d'une tâche, vous pouvez également effectuer les opérations suivantes pour la pré-construction manuelle :
python
from megatron . fused_kernels import load
load () Cela adapte automatiquement le processus de construction sur différents fournisseurs de GPU (AMD, NVIDIA) sans modifications de code spécifiques à la plate-forme. Pour tester davantage les noyaux fusionnés à l'aide de pytest , utilisez pytest tests/model/test_fused_kernels.py
Pour utiliser Flash-Attention, installez les dépendances supplémentaires dans ./requirements/requirements-flashattention.txt et définissez le type d'attention dans votre configuration en conséquence (voir configurations). Cela peut fournir des accélérations significatives par rapport à une attention régulière sur certaines architectures GPU, notamment les GPU Ampere (tels que les A100) ; voir le référentiel pour plus de détails.
NeoX et Deep(er)Speed prennent en charge la formation sur plusieurs nœuds différents et vous avez la possibilité d'utiliser une variété de lanceurs différents pour orchestrer des tâches multi-nœuds.
En général, il doit y avoir un "fichier hôte" quelque part accessible au format :
node1_ip slots=8
node2_ip slots=8 où la première colonne contient l'adresse IP de chaque nœud de votre configuration et le nombre d'emplacements est le nombre de GPU auxquels le nœud a accès. Dans votre configuration, vous devez transmettre le chemin d'accès au fichier hôte avec "hostfile": "/path/to/hostfile" . Alternativement, le chemin d'accès au fichier hôte peut être dans la variable d'environnement DLTS_HOSTFILE .
pdsh est le lanceur par défaut, et si vous utilisez pdsh , tout ce que vous devez faire (en plus de vous assurer que pdsh est installé dans votre environnement) est de définir {"launcher": "pdsh"} dans vos fichiers de configuration.
Si vous utilisez MPI, vous devez spécifier la bibliothèque MPI (DeepSpeed/GPT-NeoX prend actuellement en charge mvapich , openmpi , mpich et impi , bien que openmpi soit la plus couramment utilisée et testée) ainsi que transmettre l'indicateur deepspeed_mpi dans votre fichier de configuration :
{
"launcher" : " openmpi " ,
"deepspeed_mpi" : true
} Avec votre environnement correctement configuré et les fichiers de configuration corrects, vous pouvez utiliser deepy.py comme un script Python normal et démarrer (par exemple) un travail de formation avec :
python3 deepy.py train.py /path/to/configs/my_model.yml
L'utilisation de Slurm peut être légèrement plus complexe. Comme avec MPI, vous devez ajouter les éléments suivants à votre configuration :
{
"launcher" : " slurm " ,
"deepspeed_slurm" : true
} Si vous n'avez pas d'accès SSH aux nœuds de calcul de votre cluster Slurm, vous devez ajouter {"no_ssh_check": true}
Il existe de nombreux cas où les options de lancement par défaut ci-dessus ne suffisent pas.
Dans ces cas, vous devrez modifier l'utilitaire d'exécution multi-nœuds DeepSpeed pour prendre en charge votre cas d'utilisation. Globalement, ces améliorations se répartissent en deux catégories :
Dans ce cas, vous devez ajouter une nouvelle classe d'exécution multi-nœuds à deepspeed/launcher/multinode_runner.py et l'exposer en tant qu'option de configuration dans GPT-NeoX. Des exemples de la façon dont nous avons procédé pour Summit JSRun se trouvent respectivement dans ce commit DeeperSpeed et ce commit GPT-NeoX.
Nous avons rencontré de nombreux cas où nous souhaitons modifier la commande run MPI/Slurm pour une optimisation ou un débogage (par exemple pour modifier la liaison CPU Slurm srun ou pour taguer les logs MPI avec le rang). Dans ce cas, vous devez modifier la commande run de la classe runner multinode sous sa méthode get_cmd (par exemple mpirun_cmd pour OpenMPI). Des exemples de la façon dont nous avons procédé pour fournir des commandes d'exécution optimisées et classées à l'aide de Slurm et OpenMPI pour le cluster de stabilité se trouvent dans cette branche DeeperSpeed.
En général, vous ne pourrez pas avoir un seul fichier hôte fixe, vous devez donc disposer d'un script pour en générer un de manière dynamique au démarrage de votre travail. Un exemple de script pour générer dynamiquement un fichier hôte à l'aide de Slurm et de 8 GPU par nœud est :
#! /bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# need to add the current slurm jobid to hostfile name so that we don't add to previous hostfile
hostfile=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# be extra sure we aren't appending to a previous hostfile
rm $hostfile & > /dev/null
# loop over the node names
for i in ` scontrol show hostnames $SLURM_NODELIST `
do
# add a line to the hostfile
echo $i slots= $GPUS_PER_NODE >> $hostfile
done $SLURM_JOBID et $SLURM_NODELIST étant des variables d'environnement que Slurm créera pour vous. Consultez la documentation sbatch pour une liste complète des variables d'environnement Slurm disponibles définies au moment de la création de la tâche.
Ensuite, vous pouvez créer un script sbatch à partir duquel lancer votre travail GPT-NeoX. Un script sbatch simple sur un cluster basé sur Slurm avec 8 GPU par nœud ressemblerait à ceci :
#! /bin/bash
# SBATCH --job-name="neox"
# SBATCH --partition=your-partition
# SBATCH --nodes=1
# SBATCH --ntasks-per-node=8
# SBATCH --gres=gpu:8
# Some potentially useful distributed environment variables
export HOSTNAMES= ` scontrol show hostnames " $SLURM_JOB_NODELIST " `
export MASTER_ADDR= $( scontrol show hostnames " $SLURM_JOB_NODELIST " | head -n 1 )
export MASTER_PORT=12802
export COUNT_NODE= ` scontrol show hostnames " $SLURM_JOB_NODELIST " | wc -l `
# Your hostfile creation script from above
./write_hostfile.sh
# Tell DeepSpeed where to find our generated hostfile via DLTS_HOSTFILE
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# Launch training
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
Vous pouvez ensuite lancer une formation avec sbatch my_sbatch_script.sh
Nous fournissons également une configuration Dockerfile et docker-compose si vous préférez exécuter NeoX dans un conteneur.
Les conditions requises pour exécuter le conteneur doivent disposer des pilotes GPU appropriés, d'une installation à jour de Docker et de nvidia-container-toolkit installé. Pour tester si votre installation est bonne, vous pouvez utiliser leur « exemple de charge de travail », qui est :
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
À condition que cela s'exécute, vous devez exporter NEOX_DATA_PATH et NEOX_CHECKPOINT_PATH dans votre environnement pour spécifier votre répertoire de données et votre répertoire de stockage et de chargement des points de contrôle :
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 #or wherever your data is stored on your system
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
Et puis, à partir du répertoire gpt-neox, vous pouvez créer l'image et exécuter un shell dans un conteneur avec
docker compose run gpt-neox bash
Après la compilation, vous devriez pouvoir faire ceci :
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
Pour un travail de longue durée, vous devez exécuter
docker compose up -d
pour exécuter le conteneur en mode détaché, puis, dans une session de terminal distincte, exécutez
docker compose exec gpt-neox bash
Vous pouvez ensuite exécuter n’importe quelle tâche depuis l’intérieur du conteneur.
Les problèmes lors d'une utilisation prolongée ou en mode détaché incluent
Si vous préférez exécuter l'image de conteneur prédéfinie à partir de dockerhub, vous pouvez exécuter les commandes docker compose avec -f docker-compose-dockerhub.yml à la place, par exemple :
docker compose run -f docker-compose-dockerhub.yml gpt-neox bash
Toutes les fonctionnalités doivent être lancées à l'aide de deepy.py , un wrapper autour du lanceur deepspeed .
Nous proposons actuellement trois fonctions principales :
train.py est utilisé pour la formation et la mise au point des modèles.eval.py est utilisé pour évaluer un modèle entraîné à l'aide du harnais d'évaluation du modèle de langage.generate.py est utilisé pour échantillonner le texte d'un modèle entraîné.qui peut être lancé avec :
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]Par exemple, pour lancer une formation, vous pouvez exécuter
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.ymlPour plus de détails sur chaque point d'entrée, voir respectivement Formation et réglage fin, Inférence et Évaluation.
Les paramètres GPT-NeoX sont définis dans un fichier de configuration YAML qui est transmis au lanceur deepy.py. Nous avons fourni quelques exemples de fichiers .yml dans les configurations, montrant un large éventail de fonctionnalités et de tailles de modèles.
Ces fichiers sont généralement complets, mais non optimaux. Par exemple, en fonction de votre configuration GPU spécifique, vous devrez peut-être modifier certains paramètres tels que pipe-parallel-size , model-parallel-size pour augmenter ou diminuer le degré de parallélisation, train_micro_batch_size_per_gpu ou gradient-accumulation-steps pour modifier la taille du lot. paramètres associés, ou le dict zero_optimization pour modifier la façon dont les états de l'optimiseur sont parallélisés entre les travailleurs.
Pour un guide plus détaillé des fonctionnalités disponibles et comment les configurer, consultez le README de configuration, et pour la documentation de chaque argument possible, voir configs/neox_arguments.md.
GPT-NeoX comprend plusieurs implémentations expertes pour MoE. Pour choisir entre eux, spécifiez moe_type de megablocks (par défaut) ou deepspeed .
Les deux sont basés sur le cadre de parallélisme DeepSpeed MoE, qui prend en charge le parallélisme tenseur-expert-données. Les deux vous permettent de basculer entre le drop-dropping et le dropless (par défaut, et c'est pour cela que Megablocks a été conçu). Le routage Sinkhorn sera bientôt disponible !
Pour un exemple de configuration complète de base, voir configs/125M-dmoe.yml (pour les Megablocks dropless) ou configs/125M-moe.yml.
La plupart des arguments de configuration liés au MoE portent le préfixe moe . Certains paramètres de configuration courants et leurs valeurs par défaut sont les suivants :
moe_type: megablocks
moe_num_experts: 1 # 1 disables MoE. 8 is a reasonable value.
moe_loss_coeff: 0.1
expert_interval: 2 # See details below
enable_expert_tensor_parallelism: false # See details below
moe_expert_parallel_size: 1 # See details below
moe_token_dropping: false
DeepSpeed peut être configuré davantage avec les éléments suivants :
moe_top_k: 1
moe_min_capacity: 4
moe_train_capacity_factor: 1.0 # Setting to 1.0
moe_eval_capacity_factor: 1.0 # Setting to 1.0
Une couche MoE est présente dans toutes les couches de transformateur expert_interval , y compris la première, donc avec 12 couches au total :
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
Les experts seraient dans ces couches :
0, 2, 4, 6, 8, 10
Par défaut, nous utilisons le parallélisme de données expertes, donc tout parallélisme tensoriel disponible ( model_parallel_size ) sera utilisé pour le routage expert. Par exemple, compte tenu des éléments suivants :
expert_parallel_size: 4
model_parallel_size: 2 # aka tensor parallelism
Avec 32 GPU, le comportement ressemblera à :
expert_parallel_size == model_parallel_size . Le paramètre enable_expert_tensor_parallelism active le parallélisme tensor-expert-data (TED). La façon d’interpréter ce qui précède serait alors :
expert_parallel_size == 1 ou model_parallel_size == 1 .Notez donc que DP doit être divisible par (MP * EP). Pour plus de détails, consultez l'article TED.
Le parallélisme des pipelines n'est pas encore pris en charge - bientôt !
Plusieurs ensembles de données préconfigurés sont disponibles, y compris la plupart des composants de Pile, ainsi que l'ensemble de trains Pile lui-même, pour une tokenisation simple à l'aide du point d'entrée prepare_data.py .
Par exemple, pour télécharger et tokeniser l'ensemble de données enwik8 avec le GPT2 Tokenizer, en les enregistrant dans ./data vous pouvez exécuter :
python prepare_data.py -d ./data
ou un seul fragment de la pile ( pile_subset ) avec le tokenizer GPT-NeoX-20B (en supposant que vous l'ayez enregistré à ./20B_checkpoints/20B_tokenizer.json ) :
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
Les données tokenisées seront enregistrées dans deux fichiers : [data-dir]/[dataset-name]/[dataset-name]_text_document.bin et [data-dir]/[dataset-name]/[dataset-name]_text_document.idx . Vous devrez ajouter le préfixe que ces deux fichiers partagent à votre fichier de configuration de formation sous le champ data-path . PAR EXEMPLE :
" data-path " : " ./data/enwik8/enwik8_text_document " , Pour préparer votre propre ensemble de données pour l'entraînement avec des données personnalisées, formatez-le sous la forme d'un gros fichier au format jsonl, chaque élément de la liste des dictionnaires étant un document distinct. Le texte du document doit être regroupé sous une seule clé JSON, c'est-à-dire "text" . Les données auxiliaires stockées dans d'autres champs ne seront pas utilisées.
Assurez-vous ensuite de télécharger le vocabulaire du tokenizer GPT2 et de fusionner les fichiers à partir des liens suivants :
Ou utilisez le tokenizer 20B (pour lequel un seul fichier Vocab est nécessaire) :
(vous pouvez également fournir n'importe quel fichier de tokenizer pouvant être chargé par la bibliothèque de tokenizers de Hugging Face avec la commande Tokenizer.from_pretrained() )
Vous pouvez désormais prétokeniser vos données à l'aide tools/datasets/preprocess_data.py , dont les arguments sont détaillés ci-dessous :
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
optional arguments:
-h, --help show this help message and exit
input data:
--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
space separate listed of keys to extract from jsonl. Default: text
--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.
tokenizer:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
What type of tokenizer to use.
--vocab-file VOCAB_FILE
Path to the vocab file
--merge-file MERGE_FILE
Path to the BPE merge file (if necessary).
--append-eod Append an <eod> token to the end of a document.
--ftfy Use ftfy to clean text
output data:
--output-prefix OUTPUT_PREFIX
Path to binary output file without suffix
--dataset-impl {lazy,cached,mmap}
Dataset implementation to use. Default: mmap
runtime:
--workers WORKERS Number of worker processes to launch
--log-interval LOG_INTERVAL
Interval between progress updates
Par exemple:
python tools/datasets/preprocess_data.py
--input ./data/mydataset.jsonl.zst
--output-prefix ./data/mydataset
--vocab ./data/gpt2-vocab.json
--merge-file gpt2-merges.txt
--dataset-impl mmap
--tokenizer-type GPT2BPETokenizer
--append-eodVous exécuterez ensuite la formation avec les paramètres suivants ajoutés à votre fichier de configuration :
" data-path " : " data/mydataset_text_document " , La formation est lancée à l'aide de deepy.py , un wrapper autour du lanceur de DeepSpeed, qui lance le même script en parallèle sur de nombreux GPU/nœuds.
Le modèle d'utilisation général est le suivant :
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...Vous pouvez transmettre un nombre arbitraire de configurations qui seront toutes fusionnées au moment de l'exécution.
Vous pouvez également éventuellement transmettre un préfixe de configuration, qui supposera que toutes vos configurations se trouvent dans le même dossier et ajoutera ce préfixe à leur chemin.
Par exemple:
python ./deepy.py train.py -d configs 125M.yml local_setup.yml Cela déploiera le script train.py sur tous les nœuds avec un processus par GPU. Les nœuds de travail et le nombre de GPU sont spécifiés dans le fichier /job/hostfile (voir la documentation des paramètres), ou peuvent simplement être transmis en tant qu'argument num_gpus s'ils sont exécutés sur une configuration à un seul nœud.
Bien que cela ne soit pas strictement nécessaire, nous trouvons utile de définir les paramètres du modèle dans un fichier de configuration (par exemple configs/125M.yml ) et les paramètres du chemin de données dans un autre (par exemple configs/local_setup.yml ).
GPT-NeoX-20B est un modèle de langage autorégressif de 20 milliards de paramètres formé sur Pile. Les détails techniques sur GPT-NeoX-20B peuvent être trouvés dans le document associé. Le fichier de configuration de ce modèle est à la fois disponible sur ./configs/20B.yml et inclus dans les liens de téléchargement ci-dessous.
Poids minces - (Aucun état d'optimisation, pour l'inférence ou le réglage fin, 39 Go)
Pour télécharger depuis la ligne de commande vers un dossier nommé 20B_checkpoints , utilisez la commande suivante :
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpointsPoids complets – (y compris les états d'optimisation, 268 Go)
Pour télécharger depuis la ligne de commande vers un dossier nommé 20B_checkpoints , utilisez la commande suivante :
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpointsLes poids peuvent également être téléchargés à l'aide d'un client BitTorrent. Les fichiers torrent peuvent être téléchargés ici : poids minces, poids complets.
Nous avons également enregistré 150 points de contrôle tout au long de la formation, un tous les 1 000 pas. Nous travaillons à trouver la meilleure façon de les servir à grande échelle, mais en attendant, les personnes intéressées à travailler avec les points de contrôle partiellement formés peuvent nous envoyer un e-mail à [email protected] pour organiser l'accès.
La Pythia Scaling Suite est une suite de modèles allant de 70 M de paramètres à 12B de paramètres formés sur la Pile destinée à promouvoir la recherche sur l'interprétabilité et la dynamique de formation des grands modèles de langage. De plus amples détails sur le projet et des liens vers les modèles peuvent être trouvés dans le document et sur le GitHub du projet.
Le projet Polyglot vise à former de puissants modèles linguistiques pré-entraînés non anglais afin de promouvoir l'accessibilité de cette technologie aux chercheurs en dehors des puissances dominantes de l'apprentissage automatique. EleutherAI a formé et publié des modèles de langue coréenne avec paramètres 1,3B, 3,8B et 5,8B, dont le plus grand surpasse tous les autres modèles de langue disponibles au public pour les tâches en langue coréenne. De plus amples détails sur le projet et des liens vers les modèles peuvent être trouvés ici.
Pour la plupart des utilisations, nous recommandons de déployer des modèles formés à l'aide de la bibliothèque GPT-NeoX via la bibliothèque Hugging Face Transformers qui est mieux optimisée pour l'inférence.
Nous prenons en charge trois types de génération à partir d'un modèle pré-entraîné :
Les trois types de génération de texte peuvent être lancés via python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.yml avec les valeurs appropriées définies dans configs/text_generation.yml .
GPT-NeoX prend en charge l'évaluation des tâches en aval via le harnais d'évaluation du modèle de langage.
Pour évaluer un modèle entraîné sur le harnais d'évaluation, exécutez simplement :
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... taskn où --eval_tasks est une liste de tâches d'évaluation suivie d'espaces, par exemple --eval_tasks lambada hellaswag piqa sciq . Pour plus de détails sur toutes les tâches disponibles, reportez-vous au référentiel lm-evaluation-harness.
GPT-NeoX est fortement optimisé pour la formation uniquement, et les points de contrôle du modèle GPT-NeoX ne sont pas compatibles dès le départ avec d'autres bibliothèques d'apprentissage en profondeur. Pour rendre les modèles facilement chargeables et partageables avec les utilisateurs finaux, et pour une exportation ultérieure vers divers autres frameworks, GPT-NeoX prend en charge la conversion de point de contrôle au format Hugging Face Transformers.
Bien que NeoX prenne en charge un certain nombre de configurations architecturales différentes, y compris les intégrations positionnelles AliBi, toutes ces configurations ne correspondent pas clairement aux configurations prises en charge dans Hugging Face Transformers.
NeoX prend en charge l'exportation de modèles compatibles vers les architectures suivantes :
La formation d'un modèle qui ne rentre pas proprement dans l'une de ces architectures Hugging Face Transformers nécessitera l'écriture d'un code de modélisation personnalisé pour le modèle exporté.
Pour convertir un point de contrôle de bibliothèque GPT-NeoX au format chargeable Hugging Face, exécutez :
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}Ensuite, pour télécharger un modèle sur Hugging Face Hub, exécutez :
huggingface-cli login
python ./tools/ckpts/upload.pyet saisissez les informations demandées, y compris le jeton d'utilisateur du hub HF.
NeoX fournit plusieurs utilitaires pour convertir un point de contrôle de modèle pré-entraîné en un format pouvant être entraîné au sein de la bibliothèque.
Les modèles ou familles de modèles suivants peuvent être chargés dans GPT-NeoX :
Nous fournissons deux utilitaires pour convertir deux formats de point de contrôle différents en un format compatible avec GPT-NeoX.
Pour convertir un point de contrôle Llama 1 ou Llama 2 distribué par Meta AI depuis son format de fichier d'origine (téléchargeable ici ou ici) vers la bibliothèque GPT-NeoX, exécutez
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
Pour convertir un modèle Hugging Face en un modèle téléchargeable NeoX, exécutez tools/ckpts/convert_hf_to_sequential.py . Voir la documentation dans ce fichier pour d'autres options.
En plus de stocker les journaux localement, nous fournissons une prise en charge intégrée de deux frameworks de surveillance d'expériences populaires : Weights & Biases, TensorBoard et Comet.
Weights & Biases pour enregistrer nos expériences est une plateforme de surveillance d'apprentissage automatique. Pour utiliser wandb pour surveiller vos expériences gpt-neox :
wandb login – vos analyses seront automatiquement enregistrées../requirements/requirements-wandb.txt . Un exemple de configuration est fourni dans ./configs/local_setup_wandb.yml .wandb_group vous permet de nommer le groupe d'exécutions et wandb_team vous permet d'attribuer vos exécutions à un compte d'organisation ou d'équipe. Un exemple de configuration est fourni dans ./configs/local_setup_wandb.yml . Nous prenons en charge l'utilisation de TensorBoard via le champ tensorboard-dir . Les dépendances requises pour la surveillance TensorBoard peuvent être trouvées et installées à partir de ./requirements/requirements-tensorboard.txt .
Comet est une plateforme de surveillance du machine learning. Pour utiliser Comet pour surveiller vos expériences gpt-neox :
comet login ou en transmettant export COMET_API_KEY=<your-key-here>comet_ml et toutes les bibliothèques de dépendances via pip install -r requirements/requirements-comet.txtuse_comet: True . Vous pouvez également personnaliser l'emplacement où les données sont enregistrées avec comet_workspace et comet_project . Un exemple complet de configuration avec comet activé est fourni dans configs/local_setup_comet.yml . Si vous devez fournir un fichier hôte à utiliser avec le lanceur DeepSpeed basé sur MPI, vous pouvez définir la variable d'environnement DLTS_HOSTFILE pour qu'elle pointe vers le fichier hôte.
Nous prenons en charge le profilage avec Nsight Systems, le PyTorch Profiler et le PyTorch Memory Profiling.
Pour utiliser le profilage Nsight Systems, définissez les options de configuration profile , profile_step_start et profile_step_stop (voir ici pour l'utilisation des arguments et ici pour un exemple de configuration).
Pour renseigner les métriques nsys, lancez la formation avec :
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py
$TRAIN_PATH/train.py --conf_dir configs <config files>
Le fichier de sortie généré peut ensuite être visualisé avec l'interface graphique de Nsight Systems :
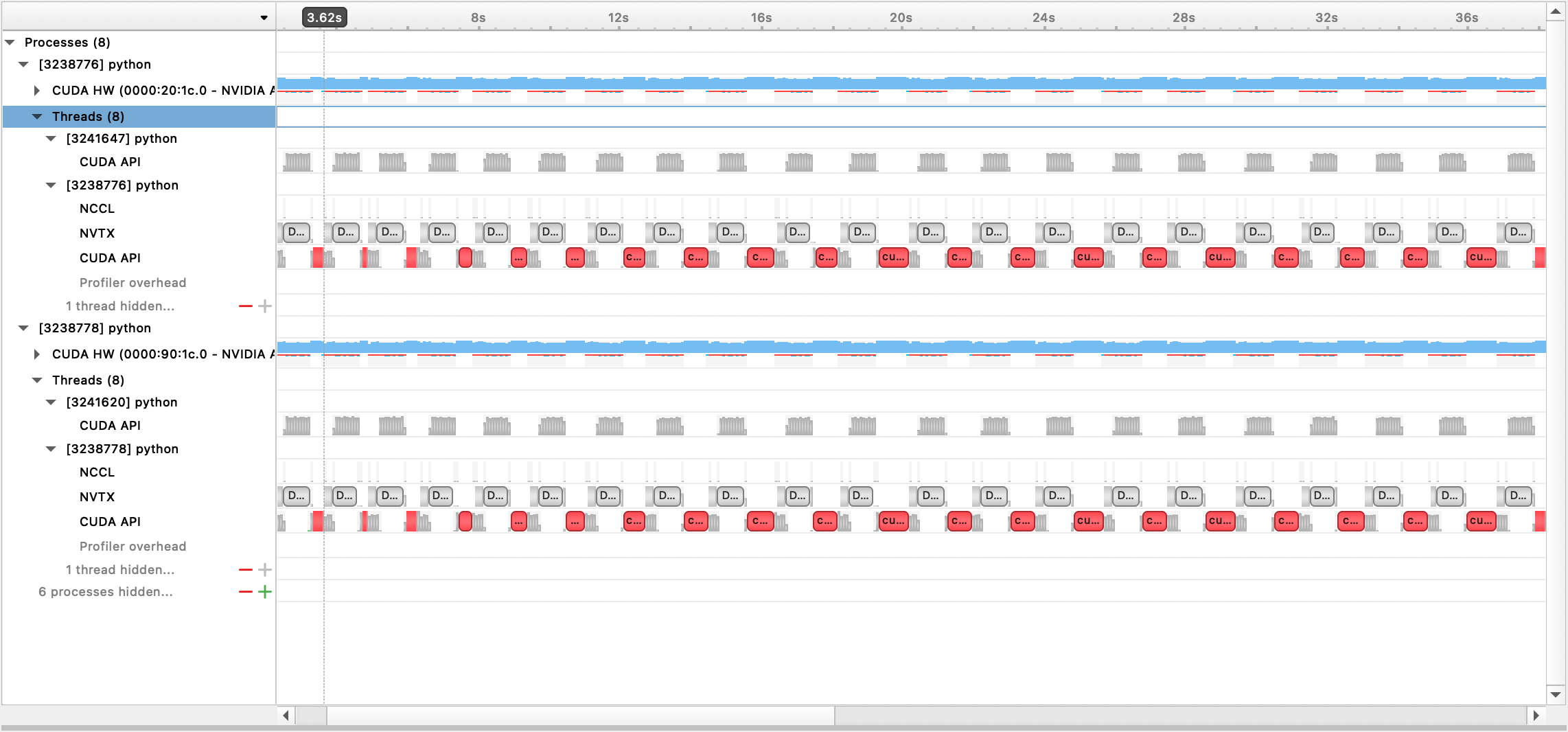
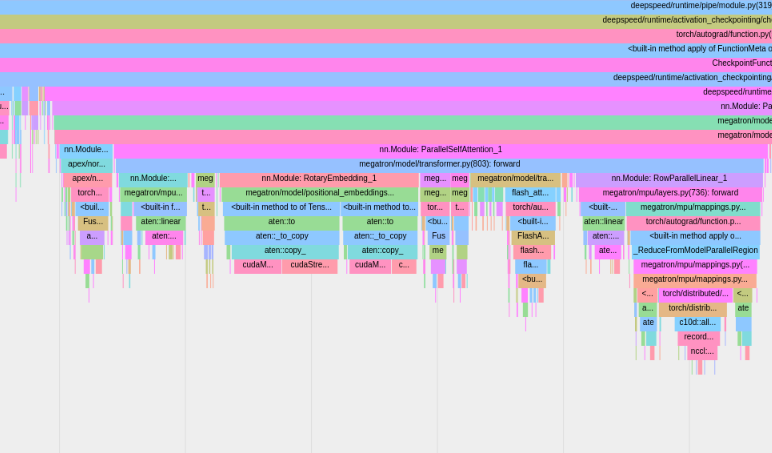
Pour utiliser le profileur PyTorch intégré, définissez les options de configuration profile , profile_step_start et profile_step_stop (voir ici pour l'utilisation des arguments, et ici pour un exemple de configuration).
Le profileur PyTorch enregistrera les traces dans le répertoire de vos journaux tensorboard . Vous pouvez afficher ces traces dans TensorBoard en suivant les étapes ici.
Pour utiliser le profilage de mémoire PyTorch, définissez les options de configuration memory_profiling et memory_profiling_path (voir ici pour l'utilisation des arguments, et ici pour un exemple de configuration).
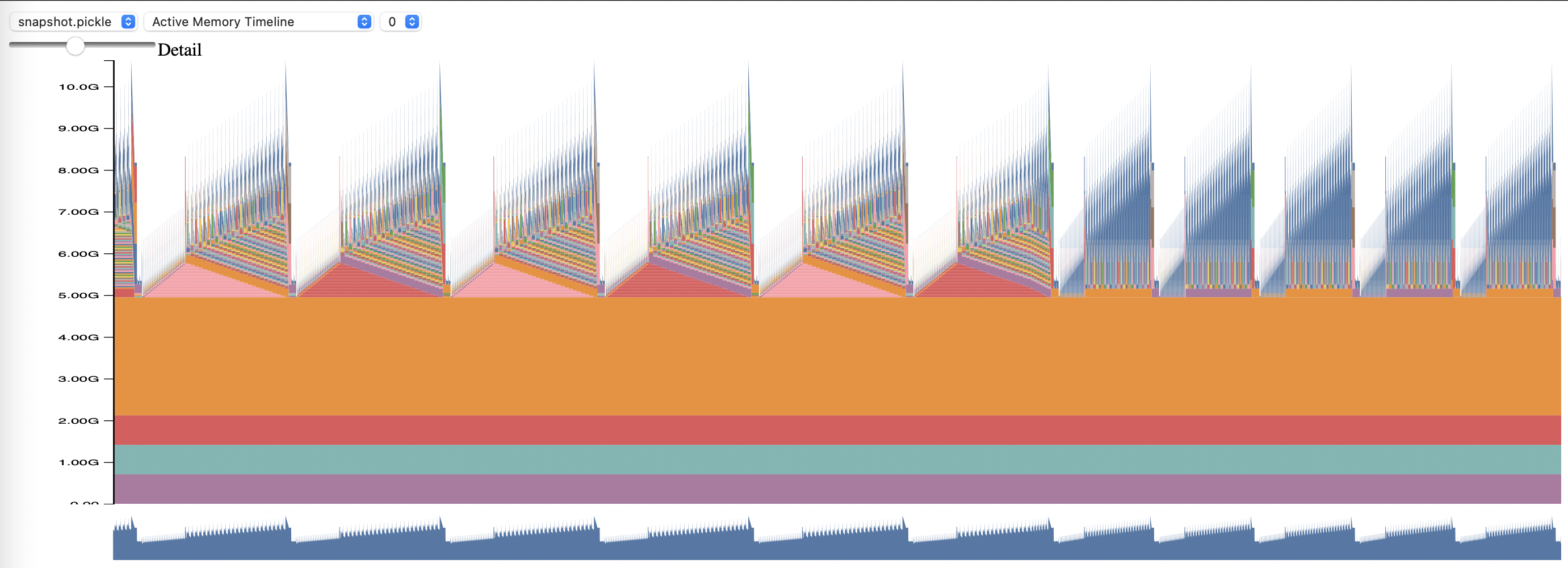
Affichez le profil généré avec le script memory_viz.py. Courez avec :
python _memory_viz.py trace_plot <generated_profile> -o trace.html
La bibliothèque GPT-NeoX a été largement adoptée par les chercheurs universitaires et industriels et portée sur de nombreux systèmes HPC.
Si vous avez trouvé cette bibliothèque utile dans vos recherches, contactez-nous et faites-le nous savoir ! Nous serions ravis de vous ajouter à nos listes.
EleutherAI et nos collaborateurs l'ont utilisé dans les publications suivantes :
Les publications suivantes d'autres groupes de recherche utilisent cette bibliothèque :


